python应用:爬虫框架Scrapy系统学习第四篇——scrapy爬取笔趣阁小说
使用cmd创建一个scrapy项目:
scrapy startproject project_name (project_name 必须以字母开头,只能包含字母、数字以及下划线<underscorce>)
项目目录层级如下:
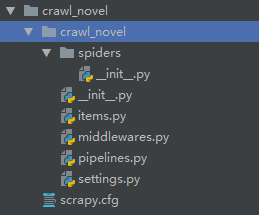
声明Item
声明我们可能用到的所有字段,包括管理字段等。管理字段可以让我们清楚何时(date)、何地(url server)及如何(spider)执行爬去,此外,还可以自动完成诸如使item失效、规划新的抓取迭代或是删除来自有问题的爬虫的item。
管理字段 |
Python表达式 |
| url |
response.url 例:‘http://www.baidu.com’ |
| project |
self.ettings.get('BOT_NAME') 例:‘crawl_novel’ |
| spider |
self.name 例:‘basic’ |
| server |
socket.gethostname() 例:‘scrapyserverl’ |
| date |
datetime.datetime.now() 例:‘datetime.datetime(2019,1,21……)’ |
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class CrawlNovelItem(scrapy.Item):
# Primary fields
title = scrapy.Field()
author = scrapy.Field()
classify = scrapy.Field()
recommend = scrapy.Field()
chapter_urls = scrapy.Field() # Calculated fields
chapter = scrapy.Field() # Housekeeping fields
url = scrapy.Field()
project = scrapy.Field()
spider = scrapy.Field()
server = scrapy.Field()
date = scrapy.Field()
编写爬虫并填充item
使用scrapy genspider 命令
scrapy genspider -l 查看可用模板
scrapy genspider -t 使用任意其他模板创建爬虫
e.g. scrapy genspider basic www spiders目录中新增一个basic.py文件,并限制只能爬取www域名下的url
使用 scrapy crawl 命令运行爬虫文件
e.g. scrapy crawl basic (basic是spider下的爬虫文件)
使用 scrapy parse命令用不同页面调试代码
e.g. scrapy parse --spider=basic http://www.……
使用scrapy crawl basic -o +文件名.文件类型 保存文件
e.g. scrapy crawl basic -o items.json(items.csv、items.j1、items.xml)
basic.py
# -*- coding: utf-8 -*-
import scrapy from crawl_novel.items import CrawlNovelItem class BasicSpider(scrapy.Spider):
name = 'basic'
allowed_domains = ['www']
start_urls = ['http://www.biquge.info/22_22559/'] def parse(self, response):
'''
self.log("title: %s" % response.xpath('//h1[1]/text()').extract())
self.log("author: %s" % response.xpath('//*[@id="info"]/p[1]/text()').extract())
self.log("classify: %s" % response.xpath('//*[@id="info"]/p[2]/text()').extract())
self.log("recommend: %s" % response.xpath('//*[@id="listtj"]//text()').extract())
self.log("chapter_urls %s" % response.xpath('//*[@id="list"]//a').extract())
'''
# 填充item
item = CrawlNovelItem()
item['title'] = response.xpath('//h1[1]/text()').extract()
item['author'] = response.xpath('//*[@id="info"]/p[1]/text()').extract()
item['classify'] = response.xpath('//*[@id="info"]/p[2]/text()').extract()
item['recommend'] = response.xpath('//*[@id="listtj"]//text()').extract()
item['chapter_urls'] = response.xpath('//*[@id="list"]//a/@href').extract()
return item
清理——item装载器、添加管理字段,并对数据进行格式化和清洗
使用ItemLoader以代替那些杂乱的extract()和xpath()操作
使用MapCompose参数
使用lambda表达式
# -*- coding: utf-8 -*-
import datetime
import socket
import urlparse import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose, Join from crawl_novel.items import CrawlNovelItem class BasicSpider(scrapy.Spider):
name = 'basic'
allowed_domains = ['www']
start_urls = ['http://www.biquge.info/22_22559/'] def parse(self, response):
# 定义装载器
l = ItemLoader(item=CrawlNovelItem(), response=response)
# 使用处理器
# 去除首位空白符,使结果按照收尾标题格式
l.add_xpath('title', '//h1[1]/text()', MapCompose(unicode.strip, unicode.title))
l.add_xpath('author', '//*[@id="info"]/p[1]/text()', MapCompose(unicode.strip))
l.add_xpath('classify', '//*[@id="info"]/p[2]/text()', MapCompose(unicode.strip))
# 将多个结果连接在一起
l.add_xpath('recommend', '//*[@id="listtj"]//text()', Join())
# 使用lambda表达式(以response.url为基础,将相对路径i转化为绝对路径)
l.add_xpath('chapter_urls', '//*[@id="list"]//a/@href', MapCompose(lambda i: urlparse.urljoin(response.url, i)))
# 添加管理字段
l.add_value('url', response.url)
l.add_value('project', self.settings.get('BOT_NAME'))
l.add_value('spider', self.name)
l.add_value('server', socket.gethostname())
l.add_value('date', datetime.datetime.now()) return l.load_item()
创建contract,检验代码可用性
使用scrapy check + 文件名 执行
e.g. scrapy check basic
def parse(self, response):
"""This function parses a property page. @url http://www.biquge.info/22_22559/
@returns items 1
@scrapes title author classify recommend chapter_urls
@scrapes url project spider server date
"""
# 定义装载器
l = ItemLoader(item=CrawlNovelItem(), response=response)
……
python应用:爬虫框架Scrapy系统学习第四篇——scrapy爬取笔趣阁小说的更多相关文章
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- Python爬取笔趣阁小说,有趣又实用
上班想摸鱼?为了摸鱼方便,今天自己写了个爬取笔阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 1. 首先导入相关的模块 import os import requests from ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- 爬虫入门实例:利用requests库爬取笔趣小说网
w3cschool上的来练练手,爬取笔趣看小说http://www.biqukan.com/, 爬取<凡人修仙传仙界篇>的所有章节 1.利用requests访问目标网址,使用了get方法 ...
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
- Python 网络爬虫 006 (编程) 解决下载(或叫:爬取)到的网页乱码问题
解决下载(或叫:爬取)到的网页乱码问题 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyCharm 20 ...
- python网络爬虫(12)去哪网酒店信息爬取
目的意义 爬取某地的酒店价格信息,示例使用selenium在Firefox中的使用. 来源 少部分来源于书.python爬虫开发与项目实战 构造 本次使用简易的方案,模拟浏览器访问,然后输入字段,查找 ...
- 用python爬虫简单爬取 笔趣网:类“起点网”的小说
首先:文章用到的解析库介绍 BeautifulSoup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能. 它是一个工具箱,通过解析文档为用户提供 ...
随机推荐
- mongodb 3.4分片复制集配置
1:启动三个实例 mongod -f /home/mongodb/db27017/mongodb27017.conf mongod -f /home/mongodb/db27018/mongodb27 ...
- 一次查找sqlserver死锁的经历
查找bug是程序员的家常便饭,我身边的人喜欢让用户来重现问题.当然他们也会从正式服务器上下载错误log,然后尝试分析log,不过当错误不是那种不经思考就可识别的情况,他们就会将问题推向用户,甚至怪罪程 ...
- 【Leetcode】【Medium】Binary Tree Preorder Traversal
Given a binary tree, return the preorder traversal of its nodes' values. For example:Given binary tr ...
- yii2.0发送qq邮件详情配置
首先要想使用qq发送邮件必须打开使用的qq邮箱里的一个配置,
- [EffectiveC++]item35:考虑virtual函数以外的其他选择
本质上是说了: Template Pattern & Strategy Pattern 详细见<C++设计模式 23种设计模式.pdf 55页> 宁可要组合 不要继承. ——— ...
- C语言main函数的参数
在Windows下使用gcc编译器: 1.首先介绍下MinGW MinGW(Minimalist GNU for Windows),又称mingw32,是将GCC编译器和GNU Binutils移植到 ...
- onload方法注意点
function initPage() { console.log("浏览器审查元素选择日志可查看!"); } window.onload = initPage; 这里要注意,一定 ...
- BZOJ2118:墨墨的等式(最短路)
Description 墨墨突然对等式很感兴趣,他正在研究a1x1+a2y2+…+anxn=B存在非负整数解的条件,他要求你编写一个程序,给定N.{an}.以及B的取值范围,求出有多少B可以使等式存在 ...
- 学会WCF之试错法——客户端调用基础
1当客户端调用未返回结果时,服务不可用(网络连接中断,服务关闭,服务崩溃等) 客户端抛出异常 异常类型:CommunicationException InnerException: Message: ...
- scp出现ssh port 22: Connection refused 问题解决具体步骤
[root(0)@sys11 09:20:29 /home/work/Code_release/bj]# scp ./release.sh root@192.168.161.151:/Users/a ...