pandas(5):数学统计——描述性统计
Pandas 可以对 Series 与 DataFrame 进行快速的描述性统计,方便快速了解数据的集中趋势和分布差异。源Excel文件descriptive_statistics.xlsx:

一、描述性统计汇总df.describe()
df.describe(percentiles=None, include=None, exclude=None)
参数说明:
- percentiles,百分位数,默认为[.25, .5, .75],即上下四分位数和中位数,其中,中位数一定输出;
- include,控制描述性统计输出包含的内容。
数值型和离散型特征数据(定序数据和定类数据)
默认值:None,即只输出数值型数据列的统计信息(count、mean、std、min、百分位数、max)。
'all':输入的所有列的统计信息。
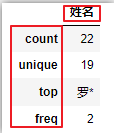
'O':只输出 object(字符、定类数据)的统计信息:count、unique(分类分组数量)、top(出现次数最多的类别)、freq(top出现的频数) - exclude,和参数include是相反的,表示不输出哪些内容。
df.describe() # 默认:数值型数据,上下四分位和中位数
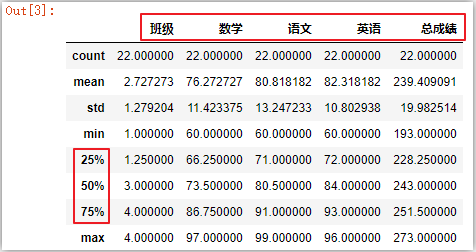
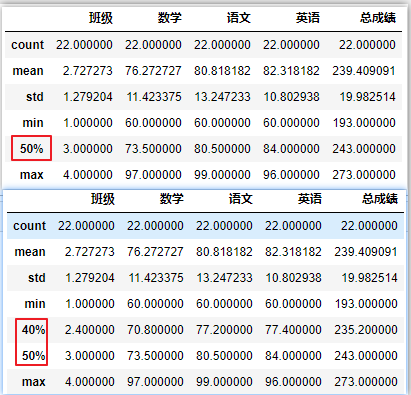
df.describe([]) # 只输出中位数
df.describe([.4]) # 中位数和40%分位数
# 指定类型:只输出字符型离散数据统计特征
df.describe(include='O')
# df.describe(include=[np.object])
# 排除类型
df.describe(exclude=[np.number])
二、其他数学统计方法
DataFrame 计算后一般为一个 Series或df,Series 计算后为一个定值。
df.mean() # 返回所有列的均值
df.mean(1) # 返回所有行的均值,下同
df.corr() # 返回列与列之间的相关系数
df.count() # 返回每一列中的非空值的个数
df.max() # 返回每一列的最大值
df.min() # 返回每一列的最小值
df.abs() # 绝对值
df.median() # 返回每一列的中位数
df.std() # 返回每一列的标准差, 贝塞尔校正的样本标准偏差
df.var() # 无偏方差
df.sem() # 平均值的标准误差
df.mode() # 众数
df.prod() # 连乘
df.mad() # 平均绝对偏差
df.cumprod() # 累积连乘,累乘
df.cumsum(axis=0) # 累积连加,累加
df.nunique() # 去重数量,不同值的量
df.idxmax() # 每列最大的值的索引名
df.idxmin() # 最小
df.cummax() # 累积最大值
df.cummin() # 累积最小值
df.skew() # 样本偏度 (第三阶)
df.kurt() # 样本峰度 (第四阶)
df.quantile() # 样本分位数 (不同 % 的值)
特殊说明:
- 很多方法支持行列指定,默认为列axis=0;
- 是否排除缺失值,默认排除skipna=False;
- 假若索引为多层索引,支持索引层次选择,level参数控制;
- 是否排除bool值,numeric_only,默认为False,不排除;
- 如果有空值总共算几,min_count,默认为0,一个不算。
pandas(5):数学统计——描述性统计的更多相关文章
- Pandas描述性统计
有很多方法用来集体计算DataFrame的描述性统计信息和其他相关操作. 其中大多数是sum(),mean()等聚合函数,但其中一些,如sumsum(),产生一个相同大小的对象. 一般来说,这些方法采 ...
- Pandas | 06 描述性统计
有很多方法用来集体计算DataFrame的描述性统计信息和其他相关操作. 其中大多数是sum(),mean()等聚合函数. 一般来说,这些方法采用轴参数,就像ndarray.{sum,std,...} ...
- Pandas 之 描述性统计案例
认识 jupyter地址: https://nbviewer.jupyter.org/github/chenjieyouge/jupyter_share/blob/master/share/panda ...
- 基于R语言的数据分析和挖掘方法总结——描述性统计
1.1 方法简介 描述性统计包含多种基本描述统计量,让用户对于数据结构可以有一个初步的认识.在此所提供之统计量包含: 基本信息:样本数.总和 集中趋势:均值.中位数.众数 离散趋势:方差(标准差).变 ...
- Python实现描述性统计
该篇笔记由木东居士提供学习小组.资料 描述性统计的概念很好理解,在日常工作中我们也经常会遇到需要使用描述性统计来表述的问题.以下,我们将使用Python实现一系列的描述性统计内容. 有关python环 ...
- SPSS统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类
https://www.zhihu.com/topic/19582125/top-answershttps://wenku.baidu.com/search?word=spss&ie=utf- ...
- 使用Python进行描述性统计
目录 1 描述性统计是什么?2 使用NumPy和SciPy进行数值分析 2.1 基本概念 2.2 中心位置(均值.中位数.众数) 2.3 发散程度(极差,方差.标准差.变异系数) 2.4 偏差程度(z ...
- \(\S1\) 描述性统计
在认识客观世界的过程中,统计学的思想和方法经常起着不可替代的作用.在许多工程及自然科学的专业领域中,包括可靠性分析.质量控制.生物信息.脑科学.心理分析.经济分析.金融风险管理.社会科学推断.行为科学 ...
- 程序员的数学 三册数学,概率统计、线性代数pdf
程序员的数学1 2012.pdf 2012版 程序员的数学2 概率统计 ,平冈和幸,(日)堀玄著 ,P4006 2015.pdf 2015版 程序员的数学3-线性代数 2016.pdf 2016版 如 ...
随机推荐
- django学习-10.django连接mysql数据库和创建数据表
1.django模型 Django对各种数据库提供了很好的支持,包括:PostgreSQL.MySQL.SQLite.Oracle. Django为这些数据库提供了统一的调用API. 我们可以根据自己 ...
- 链表、栈、队列、KMP相关知识点
链表.栈与队列.kmp; 数组模拟单链表: 用的最多的是邻接表--就是多个单链表: 作用:存储树与图 需要明确相关定义: 为什么需要使用数组模拟链表 比使用结构体 或者类来说 速度更快 代码简洁 算法 ...
- 基于股票大数据分析的Python入门实战(视频教学版)的精彩插图汇总
在我写的这本书,<基于股票大数据分析的Python入门实战(视频教学版)>里,用能吸引人的股票案例,带领大家入门Python的语法,数据分析和机器学习. 京东链接是这个:https://i ...
- python爬虫登录保持及对http总结
[前言]这几天一直看python爬虫登录保持.实现接口太多,太乱,新手难免云山雾罩.各种get.post,深入理解一下,其实就是由于http的特性需要这些操作.http是一种无状态.不保存上次通信结果 ...
- Spring Boot 老启动失败,这次再也不怕了!
Spring Boot 项目是不是经常失败,显示一大堆的错误信息,如端口重复绑定时会打印以下异常: *************************** APPLICATION FAILED TO ...
- Python爬虫学习笔记(四)
Request: Test1(基本属性:POST): 代码1: import requests # 发送POST请求 data = { } response = requests.post(url, ...
- 007-变量的作用域和LED点阵
变量 一.局部变量和全局变量 局部变量:函数内申明的变量,只在函数内有效. 全局变量:函数外部申明的变量.一个源程序文件有一个或者多个函数,全局变量对他们都起作用. 备注:全局变量有副作用,降低了函数 ...
- win10使用cmd命令关闭防火墙
在搜索框内输入cmd,右键选择管理员运行 然后输入: NetSh Advfirewall set allprofiles state off #关闭防火墙 Netsh Advfirewall show ...
- 在windows 下查看ip 地址和 在ubundu 下查看IP地址
在windows 下查看ip 地址和 在ubundu 下查看IP地址 1.在windows 下查看 IP地址:ipconfig 2.在 ubundu 下查看IP地址:ifconfig
- ClickHouse元数据异常-MySQLHandlerFactory:Failed to read RSA key pair from server
Clickhouse版本:20.3.6.40-2 clickhouse集群三个节点,一分片,三副本,三个节点数据完全一样 1. 问题描述 在使用连接工具操作时,发现其中一个节点连接拒绝,无法操作,另外 ...