Spark学习进度10-DS&DF基础操作
有类型操作
flatMap
通过 flatMap 可以将一条数据转为一个数组, 后再展开这个数组放入 Dataset
val ds1=Seq("hello spark","hello hadoop").toDS()
ds1.flatMap(item => item.split(" ")).show()
map
可以将数据集中每条数据转为另一种形式
val ds2=Seq(Person("zhangsan",15),Person("lisi",32)).toDS()
ds2.map(p => Person(p.name,p.age*2)).show()
mapPartitions
mapPartitions 和 map 一样, 但是 map 的处理单位是每条数据, mapPartitions 的处理单位是每个分区
ds2.mapPartitions(item => {
val persons = item.map(p => Person(p.name, p.age * 2))
persons
}).show()
transform
map 和 mapPartitions 以及 transform 都是转换, map 和 mapPartitions 是针对数据, 而 transform 是针对整个数据集, 这种方式最大的区别就是 transform 可以直接拿到 Dataset 进行操作
@Test
def transform(): Unit ={
val ds=spark.range(10)
ds.transform(dataset => dataset.withColumn("doubleid",'id*2)).show()
}
as
as[Type] 算子的主要作用是将弱类型的 Dataset 转为强类型的 Dataset,
@Test
def as(): Unit ={
val structType = StructType(
Seq(
StructField("name", StringType),
StructField("age", IntegerType),
StructField("gpa", FloatType)
)
) val sourceDF = spark.read
.schema(structType)
.option("delimiter", "\t")
.csv("dataset/studenttab10k") val dataset = sourceDF.as[(String,Int,Float)]
dataset.show()
}
filter
用来按照条件过滤数据集
@Test
def filter(): Unit ={
val ds=Seq(Person("zhangsan",15),Person("lisi",32)).toDS()
ds.filter(person => person.age>20).show()
}
groupByKey
grouByKey 算子的返回结果是 KeyValueGroupedDataset, 而不是一个 Dataset, 所以必须要先经过 KeyValueGroupedDataset 中的方法进行聚合, 再转回 Dataset, 才能使用 Action 得出结果
@Test
def groupByKey(): Unit ={
val ds=Seq(Person("zhangsan",15),Person("zhangsan",20),Person("lisi",32)).toDS()
val grouped = ds.groupByKey(p => p.name)
val result: Dataset[(String, Long)] = grouped.count()
result.show()
}
randomSplit
randomSplit 会按照传入的权重随机将一个 Dataset 分为多个 Dataset, 传入 randomSplit 的数组有多少个权重, 最终就会生成多少个 Dataset, 这些权重的加倍和应该为 1, 否则将被标准化
@Test
def randomSplit(): Unit ={
val ds = spark.range(15)
val datasets: Array[Dataset[lang.Long]] = ds.randomSplit(Array[Double](2, 3))
datasets.foreach(dataset => dataset.show()) ds.sample(withReplacement = false, fraction = 0.4).show()
}
orderBy
orderBy 配合 Column 的 API, 可以实现正反序排列
val ds=Seq(Person("zhangsan",15),Person("zhangsan",20),Person("lisi",32)).toDS()
ds.orderBy('age.desc).show() //select * from .. order by .. desc
sort
ds.sort('age.asc).show()
dropDuplicates
使用 dropDuplicates 可以去掉某一些列中重复的行
@Test
def dropDuplicates(): Unit ={
val ds=Seq(Person("zhangsan",15),Person("zhangsan",20),Person("lisi",32)).toDS()
ds.distinct().show()
ds.dropDuplicates("age").show()
}
distinct
根据所有列去重
ds.distinct().show()
集合操作
差集,交集,并集,limit
@Test
def collection(): Unit ={
val ds1=spark.range(1,10)
val ds2=spark.range(5,15) //差集
ds1.except(ds2).show() //交集
ds1.intersect(ds2).show() //并集
ds1.union(ds2).show() //limit
ds1.limit(3).show() }
无类型转换
选择
select:选择某些列出现在结果集中
selectExpr :在 SQL 语句中, 经常可以在 select 子句中使用 count(age), rand() 等函数, 在 selectExpr 中就可以使用这样的 SQL 表达式, 同时使用 select 配合 expr 函数也可以做到类似的效果
@Test
def select(): Unit ={ val ds=Seq(Person("zhangsan",15),Person("zhangsan",20),Person("lisi",32)).toDS()
ds.select('name).show()
ds.selectExpr("sum(age)").show() }
withColumn:通过 Column 对象在 Dataset 中创建一个新的列或者修改原来的列
withColumnRenamed:修改列名
@Test
def withcolumn(): Unit ={
import org.apache.spark.sql.functions._
val ds=Seq(Person("zhangsan",15),Person("zhangsan",20),Person("lisi",32)).toDS()
ds.withColumn("random",expr("rand()")).show()
ds.withColumn("name_new",'name).show()
ds.withColumn("name_jok",'name === "").show() ds.withColumnRenamed("name","new_name").show() }
剪除
drop:减掉某列
@Test
def drop(): Unit ={
import spark.implicits._
val ds = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS()
ds.drop('age).show()
}
集合
groupBy:按给定的行进行分组
@Test
def groupBy(): Unit ={
import spark.implicits._
val ds = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS()
ds.groupBy('name).count().show()
}
Column 对象
创建
val spark=SparkSession.builder().master("local[6]").appName("trans").getOrCreate()
import spark.implicits._
@Test
def column(): Unit ={
import spark.implicits._
val personDF = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDF()
val c1: Symbol ='name
val c2: ColumnName =$"name"
import org.apache.spark.sql.functions._
val c3: Column =col("name")
//val c4: Column =column("name")
val c5: Column =personDF.col("name")
val c6: Column =personDF.apply("name")
val c7: Column =personDF("name")
personDF.select(c1).show()
personDF.where(c1 ==="zhangsan").show()
}
别名和转换
@Test
def as(): Unit ={
val personDF = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDF()
import org.apache.spark.sql.functions._
//as 用法1:更换数据类型
personDF.select(col("age").as[Long]).show()
personDF.select('age.as[Long]).show()
//as:用法二
personDF.select(col("age").as("new_age")).show()
personDF.select('age as 'new_age ).show()
}
添加列
val ds = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS()
//增加一列
ds.withColumn("doubled",'age *2).show()
操作
like:模糊查询;isin:是否含有;sort:排序
//模糊查询
ds.where('name like "zhang%").show()
//排序
ds.sort('age asc).show()
//枚举判断
ds.where('name isin("zhangsan","wangwu","wxlf")).show()
聚合
package cn.itcast.spark.sql
import org.apache.spark.sql.{RelationalGroupedDataset, SparkSession}
import org.apache.spark.sql.types.{DoubleType, IntegerType, StructField, StructType}
import org.junit.Test
class Aggprocessor {
val spark=SparkSession.builder().master("local[6]").appName("trans").getOrCreate()
import spark.implicits._
@Test
def groupBy(): Unit ={
val schema = StructType(
List(
StructField("id", IntegerType),
StructField("year", IntegerType),
StructField("month", IntegerType),
StructField("day", IntegerType),
StructField("hour", IntegerType),
StructField("season", IntegerType),
StructField("pm", DoubleType)
)
)
//读取数据集
val sourceDF=spark.read
.schema(schema)
.option("header",value = true)
.csv("dataset/beijingpm_with_nan.csv")
//去掉pm为空的
val clearDF=sourceDF.where('pm =!= Double.NaN)
//分组
val groupedDF: RelationalGroupedDataset = clearDF.groupBy('year, 'month)
import org.apache.spark.sql.functions._
//进行聚合
groupedDF.agg(avg('pm) as("pm_avg"))
.orderBy('pm_avg desc)
.show()
//方法二
groupedDF.avg("pm")
.select($"avg(pm)" as "pm_avg")
.orderBy('pm_avg desc)
.show()
groupedDF.max("pm").show()
groupedDF.min("pm").show()
groupedDF.sum("pm").show()
groupedDF.count().show()
groupedDF.mean("pm").show()
}
}
连接
无类型连接 join
@Test
def join(): Unit ={
val person = Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 0))
.toDF("id", "name", "cityId") val cities = Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou"))
.toDF("id", "name") val df=person.join(cities, person.col("cityId") === cities.col("id"))
.select(person.col("id"),
person.col("name"),
cities.col("name") as "city") df.createOrReplaceTempView("user_city")
spark.sql("select id ,name,city from user_city where city=='Beijing'")
.show()
}
连接类型
交叉连接:cross交叉连接就是笛卡尔积, 就是两个表中所有的数据两两结对
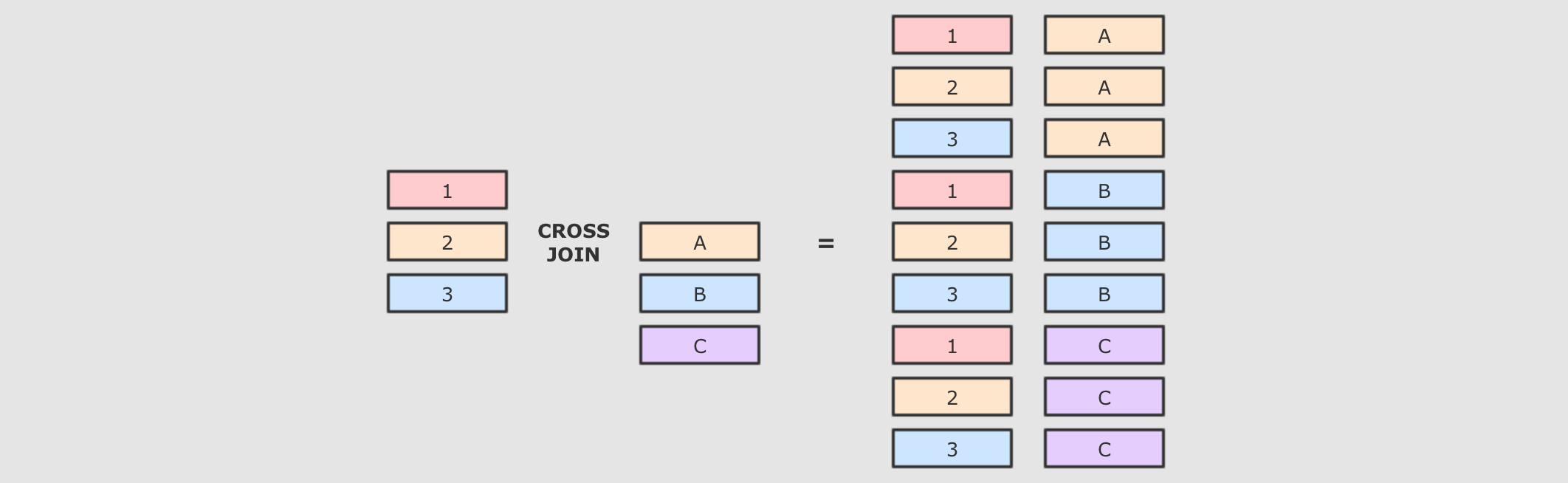
@Test
def crossJoin(): Unit ={ person.crossJoin(cities)
.where(person.col("cityId") === cities.col("id"))
.show() spark.sql("select p.id,p.name,c.name from person p cross join cities c where p.cityId = c.id")
.show() }
内连接:就是按照条件找到两个数据集关联的数据, 并且在生成的结果集中只存在能关联到的数据

@Test
def inner(): Unit ={
person.join(cities,person.col("cityId")===cities.col("id"),joinType = "inner")
.show() spark.sql("select p.id,p.name,c.name from person p inner join cities c on p.cityId=c.id").show()
}
全外连接:

@Test
def fullOuter(): Unit ={
person.join(cities,person.col("cityId") === cities.col("id"),joinType = "full")
.show() spark.sql("select p.id,p.name,c.name from person p full outer join cities c on p.cityId=c.id")
.show()
}
左外连接

person.join(cities,person.col("cityId") === cities.col("id"),joinType = "left")
.show()
右外连接

person.join(cities,person.col("cityId") === cities.col("id"),joinType = "right")
.show()
Spark学习进度10-DS&DF基础操作的更多相关文章
- postgresql数据库学习-win平台下SQLshell基础操作及语法
由于在学习https://www.bilibili.com/video/av24590479小马视频时, up主采用的linux虚拟机进行教学, 而本人采用window7进行操作,故在基础操作和语法上 ...
- spark入门(二)RDD基础操作
1 简述 spark中的RDD是一个分布式的元素集合. 在spark中,对数据的所有操作不外乎创建RDD,转化RDD以及调用RDD操作进行求值,而这些操作,spark会自动将RDD中的数据分发到集群上 ...
- python学习之路-1 python基础操作
本篇所涉及的内容 变量 常量 字符编码 用户交互input 格式化字符串 python的缩进规则 注释 初始模块 条件判断 循环 变量 变量的概念基本上和初中代数的方程变量是一致的,只是在计算机程序中 ...
- MySQL数据分析-(10)SQL基础操作之表操作
大家好,我是jacky,很高兴跟大家继续分享MySQL数据分析实战课程,前面我们学习了库层面增删改查的SQL语句,这次课jacky将给大家介绍表层面的增删改查, (一)本课时的学习逻辑 表层面的增删改 ...
- Spark学习笔记(一)——基础概述
本篇笔记主要说一下Spark到底是个什么东西,了解一下它的基本组成部分,了解一下基本的概念,为之后的学习做铺垫.过于细节的东西并不深究.在实际的操作过程中,才能够更加深刻的理解其内涵. 1.什么是Sp ...
- Linux基础学习(10)--Shell基础
第十章——Shell基础 一.Shell概述 1.Shell是什么: (1)Shell是一个命令行解释器,它为用户提供了一个向Linux内核发送请求以便运行程序的界面系统级程序,用户可以用Shell来 ...
- Spark学习进度-RDD
RDD RDD 是什么 定义 RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数 ...
- Spark学习进度11-Spark Streaming&Structured Streaming
Spark Streaming Spark Streaming 介绍 批量计算 流计算 Spark Streaming 入门 Netcat 的使用 项目实例 目标:使用 Spark Streaming ...
- 大数据spark学习第一周Scala语言基础
Scala简单介绍 Scala(Scala Language的简称)语言是一种能够执行于JVM和.Net平台之上的通用编程语言.既可用于大规模应用程序开发,也可用于脚本编程,它由由Martin Ode ...
随机推荐
- 前端webSocket和后台php
HTTP协议的特性:属于"请求-响应"模型,只有客户端发起了请求消息,服务器才能给出响应消息,没有请求,就没有响应:一个请求消息,服务器只能返回一个响应消息.有些特殊应用场景中,如 ...
- POI2009 KON-Ticket Inspector
题目链接 Description 一辆火车依次经过 \(n\) 个车站,顺序是 \(1, 2, 3, ..., n - 1, n\).给定 \(A_{i, j}\) 表示从 \(i\) 站上车,\(j ...
- AcWing 294. 计算重复
暴力 其实这题的暴力就是个模拟.暴力扫一遍 \(conn(s_1, n_1)\),若出现了 \(res\) 个 \(s_2\). 答案就是 \(\lfloor res / n1 \rfloor\). ...
- 笔记-CF643E Bear and Destroying Subtrees
CF643E Bear and Destroying Subtrees 设 \(f_{i,j}\) 表示节点 \(i\) 的子树深度为 \(\le j\) 的概率,\(ch_i\) 表示 \(i\) ...
- 题解-CF1065E Side Transmutations
CF1065E Side Transmutations \(n\) 和 \(m\) 和 \(k\) 和序列 \(b_i(1\le i\le m,1\le b_i\le b_{i+1}\le \frac ...
- 四、Zookeeper伪集群搭建
伪集群模式 Zookeeper不但可以在单机上运行单机模式 Zookeeper,而且可以在单机模拟集群模式 Zookeeper的运 行,也就是将不同实例运行在同一台机器,用端口进行区分,伪集群模式为我 ...
- JS复习之深浅拷贝
一.复习导论(数据类型相关) 想掌握JS的深浅拷贝,首先来回顾一下JS的数据类型,JS中数据类型分为基本数据类型和引用数据类型. 基本数据类型是指存放在栈中的简单数据段,数据大小确定,内存空间大小可以 ...
- 去掉RedisDesktopManager更新提示弹窗
去掉RedisDesktopManager更新提示弹窗 起因 每次打开RDM都要弹出一个更新提示弹窗,虽然打开次数不频繁,总是有个弹窗再点一次OK按钮,还不能设置关闭更新检查.更新下载还要各种登录麻烦 ...
- Flink批处理读写Hive
import org.apache.flink.table.api.*; import org.apache.flink.table.catalog.hive.HiveCatalog; /** * @ ...
- QEMU网络模式(一)——bridge
网络配置 QEMU支持的网络模式 qemu-kvm主要向客户机提供了4种不同模式的网络. 1)基于网桥(bridge)的虚拟网卡; 2)基于NAT的虚拟网络 3)QEMU内置的用户模式网络(user ...