Hadoop综合大作业
Hadoop综合大作业 要求:
用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
用Hive对爬虫大作业产生的csv文件进行数据分析
1. 用Hive对爬虫大作业产生的文本文件
这里的具体操作步骤如下:
- 将网页上的歌词段落爬取下来
- 通过jieba分词后将结果用txt文件保存,
- 将txt文件放入Hadoop分布式文件系统
- 使用hive将文件作为表数据导入
- 使用hive查询统计歌词中单词的出现次数
首先,Python爬虫程序代码如下:
import jieba
import requests
from bs4 import BeautifulSoup
lyrics = ''
headers = {
'User-Agent': 'User-Agent:*/*'
}
resp = requests.get('http://www.juzimi.com/writer/%E6%96%B9%E6%96%87%E5%B1%B1', headers=headers)
resp.encoding = 'UTF-8'
print(resp.status_code)
soup = BeautifulSoup(resp.text, 'html.parser')
page_url = 'http://www.juzimi.com/writer/%E6%96%B9%E6%96%87%E5%B1%B1?page={}'
page_last = soup.select('.pager-last')
if len(page_last) > 0:
page_last = page_last[0].text
for i in range(0, int(page_last)):
print(i)
resp = requests.get(page_url.format(i), headers=headers)
resp.encoding = 'UTF-8'
soup = BeautifulSoup(resp.text, 'html.parser')
for a in soup.select('.xlistju'):
lyrics += a.text + ' '
# 保留爬取的句子
with open('lyrics.txt', 'a+', encoding='UTF-8') as lyricFile:
lyricFile.write(lyrics)
# 加载标点符号并去除歌词中的标点
with open('punctuation.txt', 'r', encoding='UTF-8') as punctuationFile:
for punctuation in punctuationFile.readlines():
lyrics = lyrics.replace(punctuation[0], ' ')
# 加载无意义词汇
with open('meaningless.txt', 'r', encoding='UTF-8') as meaninglessFile:
mLessSet = set(meaninglessFile.read().split('\n'))
mLessSet.add(' ')
# 加载保留字
with open('reservedWord.txt', 'r', encoding='UTF-8') as reservedWordFile:
reservedWordSet = set(reservedWordFile.read().split('\n'))
for reservedWord in reservedWordSet:
jieba.add_word(reservedWord)
keywordList = list(jieba.cut(lyrics))
keywordSet = set(keywordList) - mLessSet # 将无意义词从词语集合中删除
keywordDict = {}
# 统计出词频字典
for word in keywordSet:
keywordDict[word] = keywordList.count(word)
# 对词频进行排序
keywordListSorted = list(keywordDict.items())
keywordListSorted.sort(key=lambda e: e[1], reverse=True)
# 将所有词频写出到txt
for topWordTup in keywordListSorted:
print(topWordTup)
with open('word.txt', 'a+', encoding='UTF-8') as wordFile:
for i in range(0, topWordTup[1]):
wordFile.write(topWordTup[0]+'\n')
现在将word.txt放入HDFS中并用hive查询统计,命令如下:
hdfs dfs -mkdir temp
hdfs dfs -put news.csv temp
hive
hive>
create database db_temp;
use db_temp;
create table tb_word(word string);
load data inpath '/user/hadoop/temp/word.txt' into table tb_word;
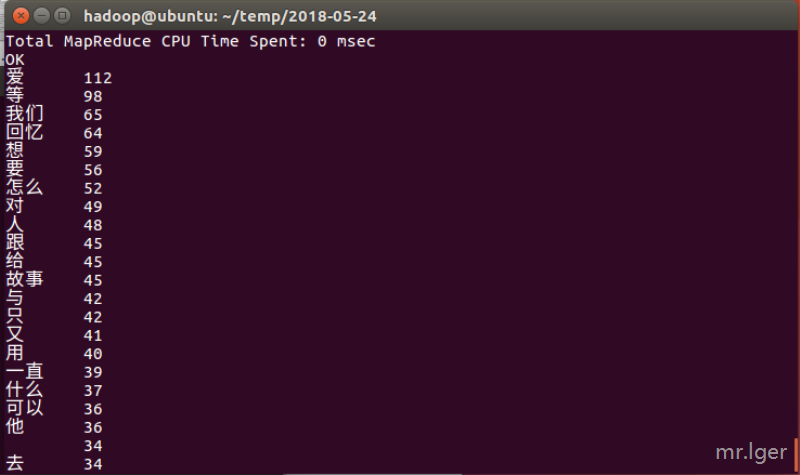
select word, count(1) as num from tb_word group by word order by num desc limit 50;
以上的运行结果截图如下:
2. 用Hive对爬虫大作业产生的csv文件进行数据分析
我这里选择了爬取校园新闻并生产csv文件来分析,首先编写爬虫,主要代码如下:
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import re
import pandas
news_list = []
def crawlOnePageSchoolNews(page_url):
res0 = requests.get(page_url)
res0.encoding = 'UTF-8'
soup0 = BeautifulSoup(res0.text, 'html.parser')
news = soup0.select('.news-list > li')
for n in news:
# print(n)
print('**' * 5 + '列表页信息' + '**' * 10)
print('新闻链接:' + n.a.attrs['href'])
print('新闻标题:' + n.select('.news-list-title')[0].text)
print('新闻描述:' + n.a.select('.news-list-description')[0].text)
print('新闻时间:' + n.a.select('.news-list-info > span')[0].text)
print('新闻来源:' + n.a.select('.news-list-info > span')[1].text)
news_list.append(getNewDetail(n.a.attrs['href']))
return news_list
def getNewDetail(href):
print('**' * 5 + '详情页信息' + '**' * 10)
print(href)
res1 = requests.get(href)
res1.encoding = 'UTF-8'
soup1 = BeautifulSoup(res1.text, 'html.parser')
news = {}
if soup1.select('#content'):
news_content = soup1.select('#content')[0].text
news['content'] = news_content.replace('\n', ' ').replace('\r', ' ').replace(',', '·')
print(news_content) # 文章内容
else:
news['content'] = ''
if soup1.select('.show-info'): # 防止之前网页没有show_info
news_info = soup1.select('.show-info')[0].text
else:
return news
info_list = ['来源', '发布时间', '点击', '作者', '审核', '摄影'] # 需要解析的字段
news_info_set = set(news_info.split('\xa0')) - {' ', ''} # 网页中的 获取后会解析成\xa0,所以可以使用\xa0作为分隔符
# 循环打印文章信息
for n_i in news_info_set:
for info_flag in info_list:
if n_i.find(info_flag) != -1: # 因为时间的冒号采用了英文符所以要进行判断
if info_flag == '发布时间':
# 将发布时间字符串转为datetime格式,方便日后存储到数据库
release_time = datetime.strptime(n_i[n_i.index(':') + 1:], '%Y-%m-%d %H:%M:%S ')
news[info_flag] = release_time
print(info_flag + ':', release_time)
elif info_flag == '点击': # 点击次数是通过文章id访问php后使用js写入,所以这里单独处理
news[info_flag] = getClickCount(href)
else:
news[info_flag] = n_i[n_i.index(':') + 1:].replace(',', '·')
print(info_flag + ':' + n_i[n_i.index(':') + 1:])
print('————' * 40)
return news
def getClickCount(news_url):
click_num_url = 'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'
click_num_url = click_num_url.format(re.search('_(.*)/(.*).html', news_url).group(2))
res2 = requests.get(click_num_url)
res2.encoding = 'UTF-8'
click_num = re.search("\$\('#hits'\).html\('(\d*)'\)", res2.text).group(1)
print('点击:' + click_num)
return click_num
print(crawlOnePageSchoolNews('http://news.gzcc.cn/html/xiaoyuanxinwen/'))
pageURL = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'
res = requests.get('http://news.gzcc.cn/html/xiaoyuanxinwen/')
res.encoding = 'UTF-8'
soup = BeautifulSoup(res.text, 'html.parser')
newsSum = int(re.search('(\d*)条', soup.select('a.a1')[0].text).group(1))
if newsSum % 10:
pageSum = int(newsSum / 10) + 1
else:
pageSum = int(newsSum / 10)
for i in range(2, pageSum + 1):
crawlOnePageSchoolNews(pageURL.format(i))
# with open('news.txt', 'w') as file:
# file.write()
dit = pandas.DataFrame(news_list)
dit.to_csv('news.csv')
print(dit)
因为csv是用逗号分隔,而文章内容有逗号和换行符容易造成影响,所以在爬取数据时做了相应处理,将换行逗号等使用其他代替。爬取后将文件放入HDFS系统,并将第一行的数据删除,这里使用insert语句覆盖原先导入的表即可,然后通过hive查询做出相应操作分析文章作者在什么时候发表的量比较多。
hdfs dfs -put news.csv temp/
hive
hive>
create table tb_news(id string, content string, author string, publish timestamp, verify string, photo string, source string, click int)row format delimited fields terminated by ',';
load data inpath '/user/hadoop/temp/news.csv' overwrite into table tb_news;
insert overwrite table tb_news select * from tb_news where content != 'content';
select time_publish, count(1) as num from (select hour(publish) as time_publish from tb_news) tb_time group by time_publish order by num desc;
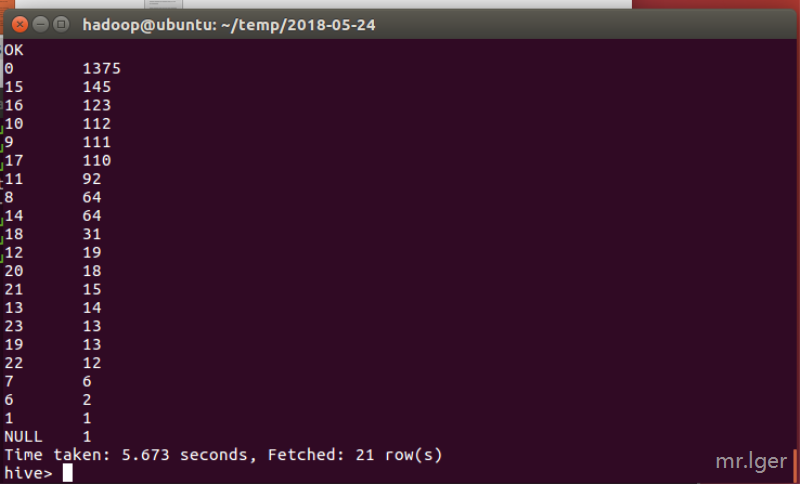
根据以上截图的结果可以看出,小编在发布时间大部分都是在0时,我只能说,熬夜不好
Hadoop综合大作业的更多相关文章
- 大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv文件 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
- 菜鸟学IT之Hadoop综合大作业
Hadoop综合大作业 作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 1.将爬虫大作业产生的csv文件上传到HDF ...
- 大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 1.将爬虫大作业产生的csv文件上传到HDFS 此次作业选取的 ...
- Hadoop综合大作业1
本次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.课程评分标准: 分数组成: 考勤 10 平时作业 30 爬 ...
- 【大数据应用技术】作业十二|Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 前言 本次作业是在<爬虫大作业>的基础上进行的 ...
- hadoop 综合大作业
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 本次作业是在期中大作业的基础上利用hadoop和hive技术进行 ...
- 大数据应用期末总评(hadoop综合大作业)
作业要求源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.将爬虫大作业产生的csv文件上传到HDFS (1)在/usr ...
随机推荐
- Python练习:哥德巴赫猜想
哥德巴赫猜想 哥德巴赫 1742 年给欧拉的信中哥德巴赫提出了以下猜想:任一大于 2 的偶数都可写成两个质数之和.但是哥德巴赫自己无法证明它,于是就写信请教赫赫有名的大数学家欧拉帮忙证明,但是一直到死 ...
- B哥竟然也被裁了,聊一聊我的看法
B哥的故事 B哥是在17年底朋友聚会上认识的一个哥们,因为都是程序员,也聊得来.就加了微信.今年是他北漂的第三个年头了. B哥是从小南方长大的一个男孩,高中学习还凑凑活活,勉强过了二本,上了大学没人管 ...
- 学习python的第三天
4.28日总结 一.关于python 1.交互式 说一句解释一句 2.命令行式 1.编写文件并且保存 2.打开python解释器,在pyrhon中打开文本,读入内存(python打开的时候,翻译不是瞬 ...
- UiPath实践经验总结(二)
1. UI操作容易受到各种意外的干扰,因此应该缩短UI操作阶段的总体时间.而为了缩短UI操作阶段的总体时间,应该将UI操作尽量放在一起,将后台的各种操作尽量放在UI操作的前后.例如,现在有 ...
- ASP.NET开发中修改代码而不重启网站
我们在做网站开发的时候,通常是写好了一个功能就要进行测试,Visual Studio上点“Start Debugging”(快捷键是F5),这是调试模式,也有直接运行模式,“Start Without ...
- vue 过滤器 基本用法
使用地点:双花括号插值和v-bind表达式. <div id="app"> <p>{{ message|capitalize}}</p> < ...
- 音频处理贤内助--libsndfile
libsndfile是由Erik de Castro Lopo写的的广泛用于读写音频文件的C语言库.它支持的音频格式十分广泛并且能够自动的从一种格式到另外一种格式.它极大的方便了开发者,可以让开发者忽 ...
- PMBook - 6.项目进度管理
6.3 排列活动顺序 6.3.1 排列活动顺序:输入 6.3.1.1 项目管理计划 6.3.1.2 项目文件 6.3.1.3 事业环境因素 6.3.1.4 组织过程资产 6.3.2 排列活动顺序: ...
- springboot打包不同环境配置与shell脚本部署
本篇和大家分享的是springboot打包并结合shell脚本命令部署,重点在分享一个shell程序启动工具,希望能便利工作: profiles指定不同环境的配置 maven-assembly-plu ...
- 《前端之路》之 operator 操作符的优先级
Github传送门,欢迎 Star - - Github地址,欢迎 Star