吴裕雄--天生自然 R语言数据可视化绘图(4)
par(ask=TRUE) # Basic scatterplot
library(ggplot2)
ggplot(data=mtcars, aes(x=wt, y=mpg)) +
geom_point() +
labs(title="Automobile Data", x="Weight", y="Miles Per Gallon")
# Scatter plot with additional options
library(ggplot2)
ggplot(data=mtcars, aes(x=wt, y=mpg)) +
geom_point(pch=17, color="blue", size=2) +
geom_smooth(method="lm", color="red", linetype=2) +
labs(title="Automobile Data", x="Weight", y="Miles Per Gallon")
# Scatter plot with faceting and grouping
data(mtcars)
mtcars$am <- factor(mtcars$am, levels=c(0,1),
labels=c("Automatic", "Manual"))
mtcars$vs <- factor(mtcars$vs, levels=c(0,1),
labels=c("V-Engine", "Straight Engine"))
mtcars$cyl <- factor(mtcars$cyl) library(ggplot2)
ggplot(data=mtcars, aes(x=hp, y=mpg,
shape=cyl, color=cyl)) +
geom_point(size=3) +
facet_grid(am~vs) +
labs(title="Automobile Data by Engine Type",
x="Horsepower", y="Miles Per Gallon")
# Using geoms
data(singer, package="lattice")
ggplot(singer, aes(x=height)) + geom_histogram()
ggplot(singer, aes(x=voice.part, y=height)) + geom_boxplot()
data(Salaries, package="car")
library(ggplot2)
ggplot(Salaries, aes(x=rank, y=salary)) +
geom_boxplot(fill="cornflowerblue",
color="black", notch=TRUE)+
geom_point(position="jitter", color="blue", alpha=.5)+
geom_rug(side="l", color="black")
# Grouping
library(ggplot2)
data(singer, package="lattice")
ggplot(singer, aes(x=voice.part, y=height)) +
geom_violin(fill="lightblue") +
geom_boxplot(fill="lightgreen", width=.2)
data(Salaries, package="car")
library(ggplot2)
ggplot(data=Salaries, aes(x=salary, fill=rank)) +
geom_density(alpha=.3)
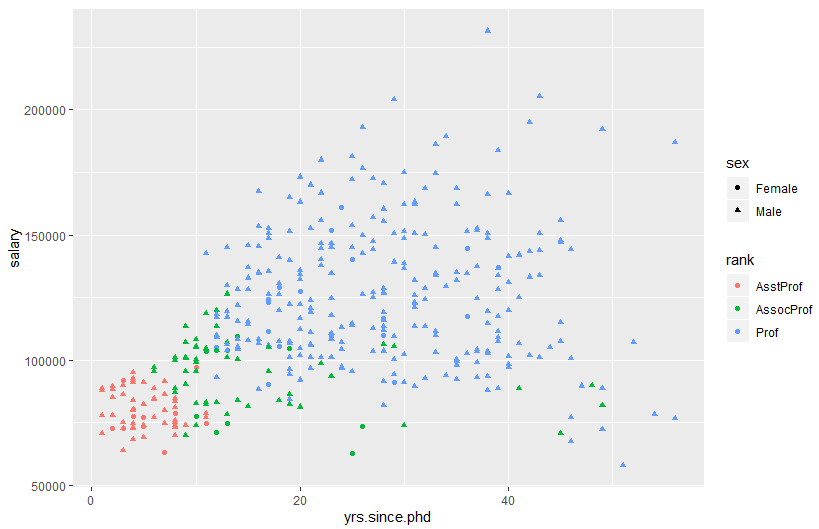
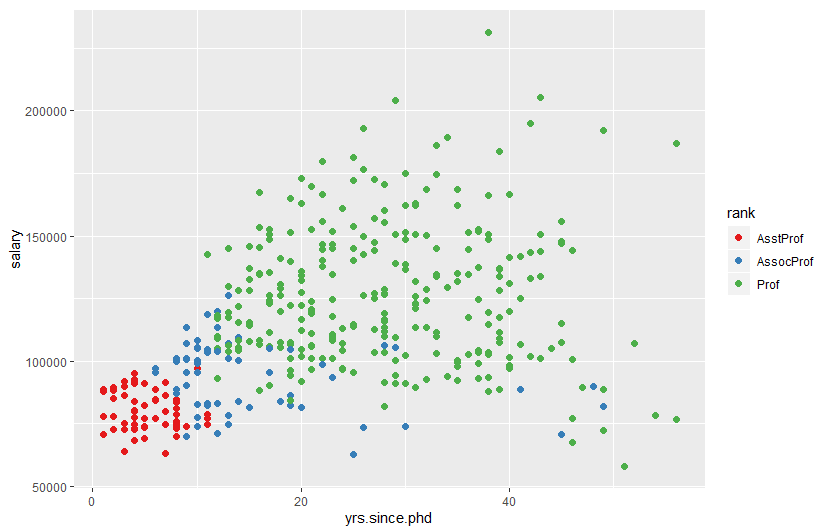
ggplot(Salaries, aes(x=yrs.since.phd, y=salary, color=rank,
shape=sex)) + geom_point()
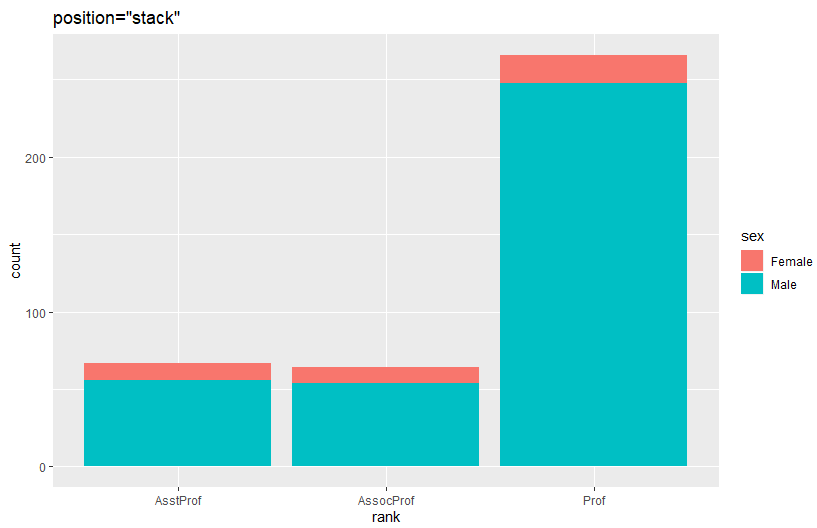
ggplot(Salaries, aes(x=rank, fill=sex)) +
geom_bar(position="stack") + labs(title='position="stack"')
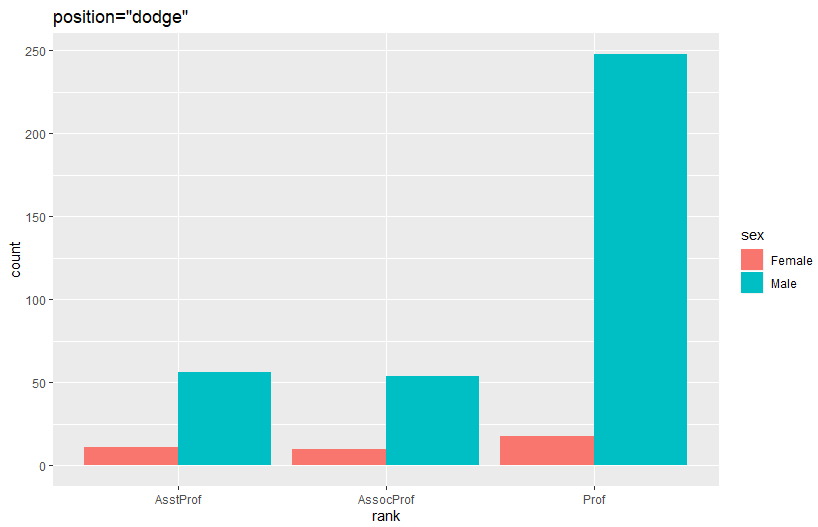
ggplot(Salaries, aes(x=rank, fill=sex)) +
geom_bar(position="dodge") + labs(title='position="dodge"')
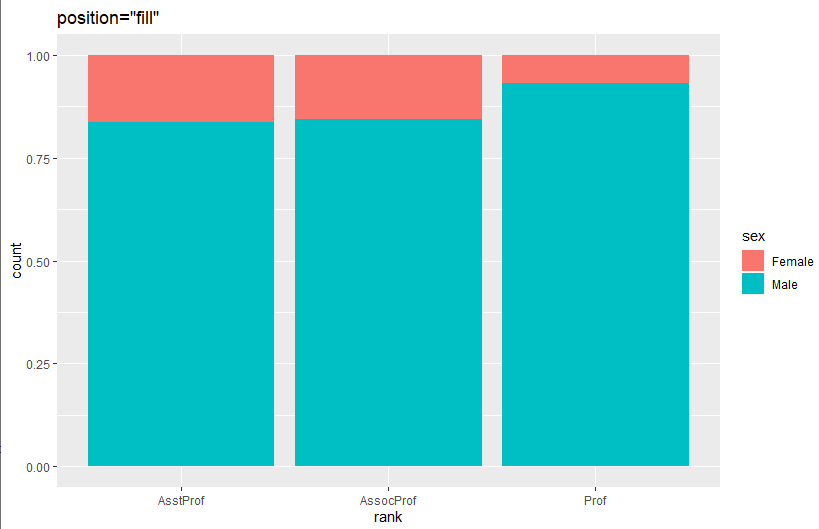
ggplot(Salaries, aes(x=rank, fill=sex)) +
geom_bar(position="fill") + labs(title='position="fill"')
# Placing options
ggplot(Salaries, aes(x=rank, fill=sex))+ geom_bar()
ggplot(Salaries, aes(x=rank)) + geom_bar(fill="red")
ggplot(Salaries, aes(x=rank, fill="red")) + geom_bar()
# Faceting
data(singer, package="lattice")
library(ggplot2)
ggplot(data=singer, aes(x=height)) +
geom_histogram() +
facet_wrap(~voice.part, nrow=4)
library(ggplot2)
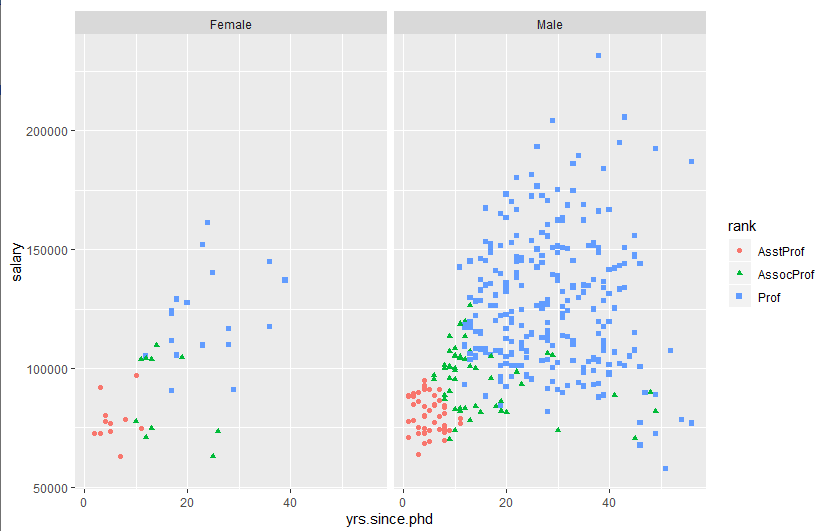
ggplot(Salaries, aes(x=yrs.since.phd, y=salary, color=rank,
shape=rank)) + geom_point() + facet_grid(.~sex)
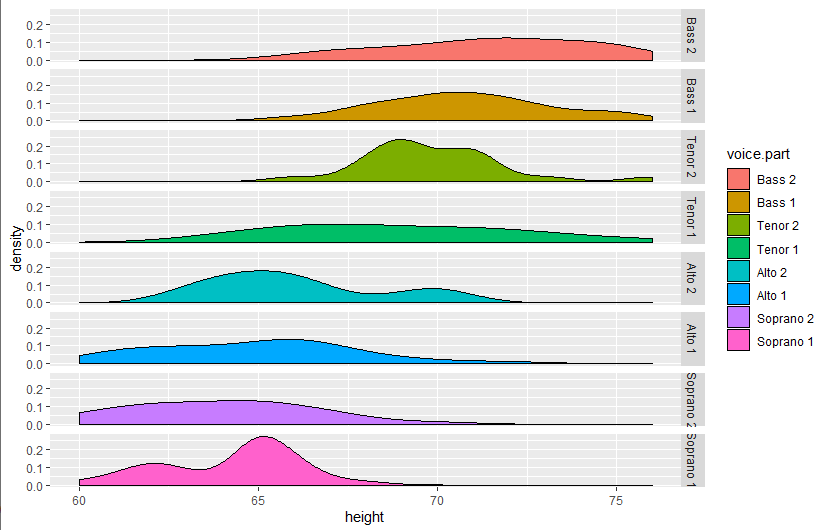
data(singer, package="lattice")
library(ggplot2)
ggplot(data=singer, aes(x=height, fill=voice.part)) +
geom_density() +
facet_grid(voice.part~.)
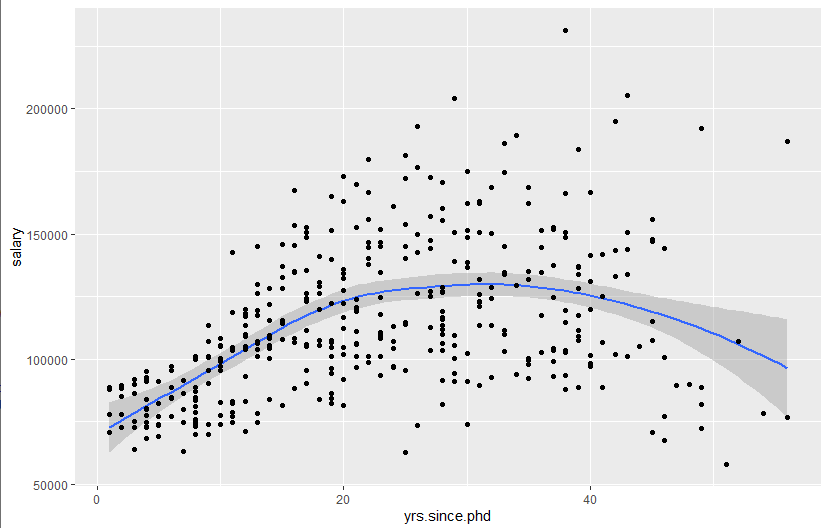
# Adding smoothed lines
data(Salaries, package="car")
library(ggplot2)
ggplot(data=Salaries, aes(x=yrs.since.phd, y=salary)) +
geom_smooth() + geom_point()
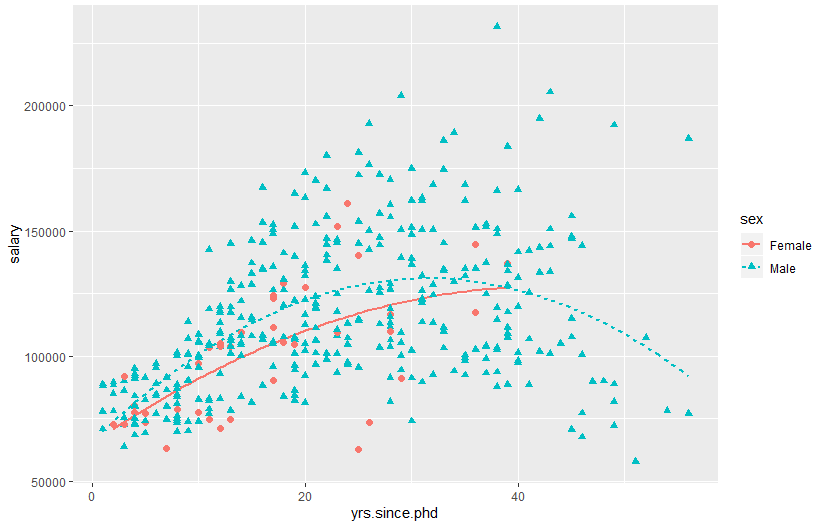
ggplot(data=Salaries, aes(x=yrs.since.phd, y=salary,
linetype=sex, shape=sex, color=sex)) +
geom_smooth(method=lm, formula=y~poly(x,2),
se=FALSE, size=1) +
geom_point(size=2)
# Modifying axes
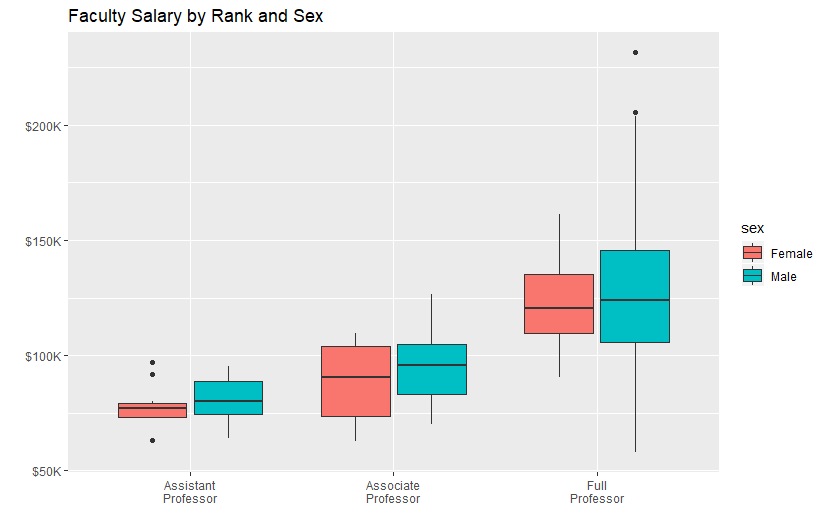
data(Salaries,package="car")
library(ggplot2)
ggplot(data=Salaries, aes(x=rank, y=salary, fill=sex)) +
geom_boxplot() +
scale_x_discrete(breaks=c("AsstProf", "AssocProf", "Prof"),
labels=c("Assistant\nProfessor",
"Associate\nProfessor",
"Full\nProfessor")) +
scale_y_continuous(breaks=c(50000, 100000, 150000, 200000),
labels=c("$50K", "$100K", "$150K", "$200K")) +
labs(title="Faculty Salary by Rank and Sex", x="", y="")
# Legends
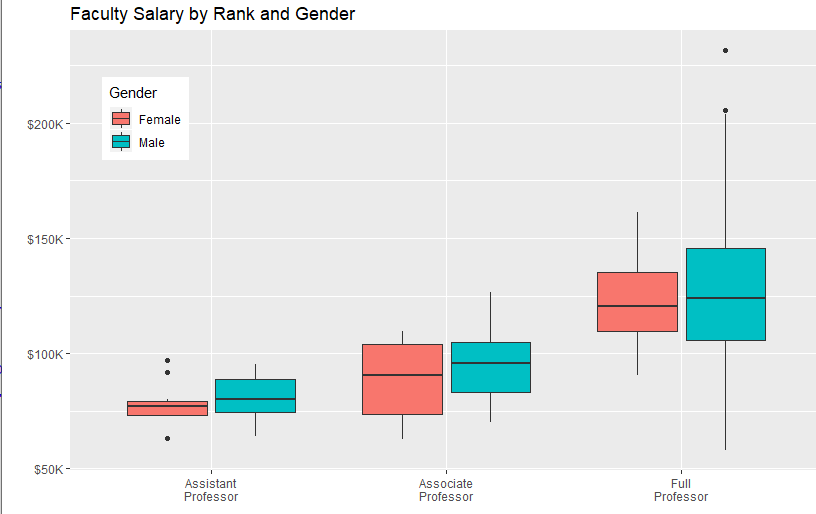
data(Salaries,package="car")
library(ggplot2)
ggplot(data=Salaries, aes(x=rank, y=salary, fill=sex)) +
geom_boxplot() +
scale_x_discrete(breaks=c("AsstProf", "AssocProf", "Prof"),
labels=c("Assistant\nProfessor",
"Associate\nProfessor",
"Full\nProfessor")) +
scale_y_continuous(breaks=c(50000, 100000, 150000, 200000),
labels=c("$50K", "$100K", "$150K", "$200K")) +
labs(title="Faculty Salary by Rank and Gender",
x="", y="", fill="Gender") +
theme(legend.position=c(.1,.8))
# Scales
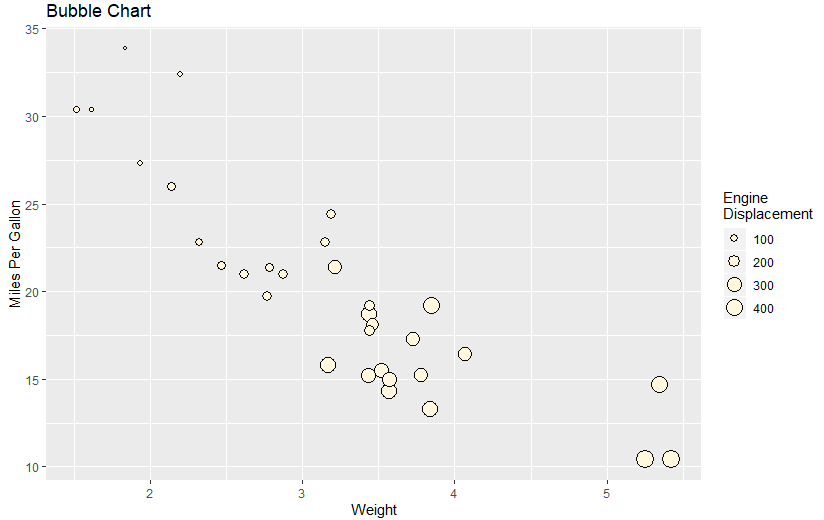
ggplot(mtcars, aes(x=wt, y=mpg, size=disp)) +
geom_point(shape=21, color="black", fill="cornsilk") +
labs(x="Weight", y="Miles Per Gallon",
title="Bubble Chart", size="Engine\nDisplacement")
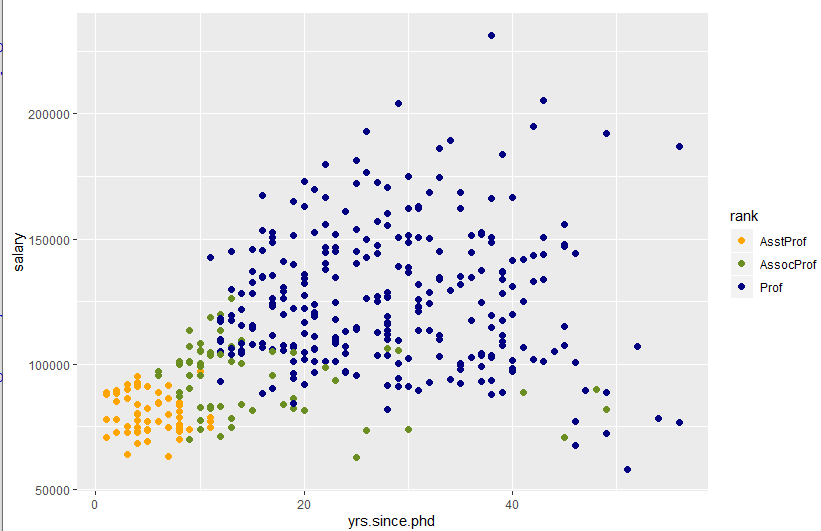
data(Salaries, package="car")
ggplot(data=Salaries, aes(x=yrs.since.phd, y=salary, color=rank)) +
scale_color_manual(values=c("orange", "olivedrab", "navy")) +
geom_point(size=2)
ggplot(data=Salaries, aes(x=yrs.since.phd, y=salary, color=rank)) +
scale_color_brewer(palette="Set1") + geom_point(size=2)
library(RColorBrewer)
display.brewer.all()

# Themes
data(Salaries, package="car")
library(ggplot2)
mytheme <- theme(plot.title=element_text(face="bold.italic",
size="", color="brown"),
axis.title=element_text(face="bold.italic",
size=10, color="brown"),
axis.text=element_text(face="bold", size=9,
color="darkblue"),
panel.background=element_rect(fill="white",
color="darkblue"),
panel.grid.major.y=element_line(color="grey",
linetype=1),
panel.grid.minor.y=element_line(color="grey",
linetype=2),
panel.grid.minor.x=element_blank(),
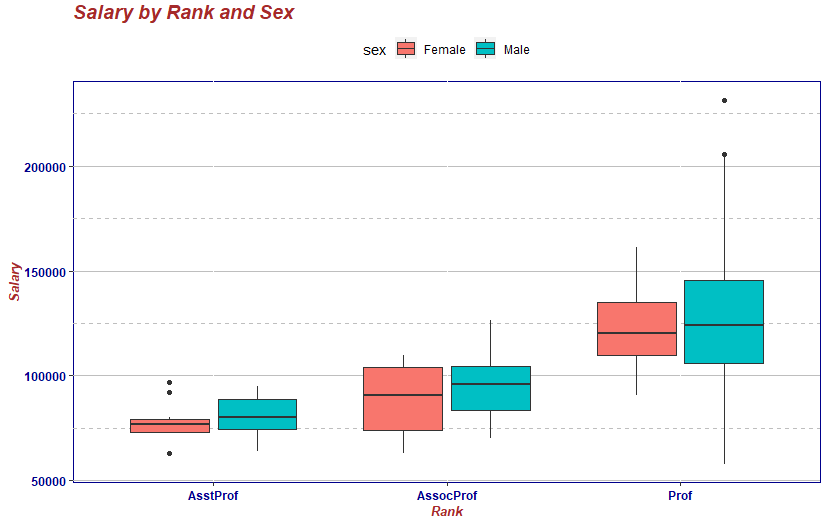
legend.position="top") ggplot(Salaries, aes(x=rank, y=salary, fill=sex)) +
geom_boxplot() +
labs(title="Salary by Rank and Sex",
x="Rank", y="Salary") +
mytheme
# Multiple graphs per page
data(Salaries, package="car")
library(ggplot2)
p1 <- ggplot(data=Salaries, aes(x=rank)) + geom_bar()
p2 <- ggplot(data=Salaries, aes(x=sex)) + geom_bar()
p3 <- ggplot(data=Salaries, aes(x=yrs.since.phd, y=salary)) + geom_point() library(gridExtra)
grid.arrange(p1, p2, p3, ncol=3) # Saving graphs
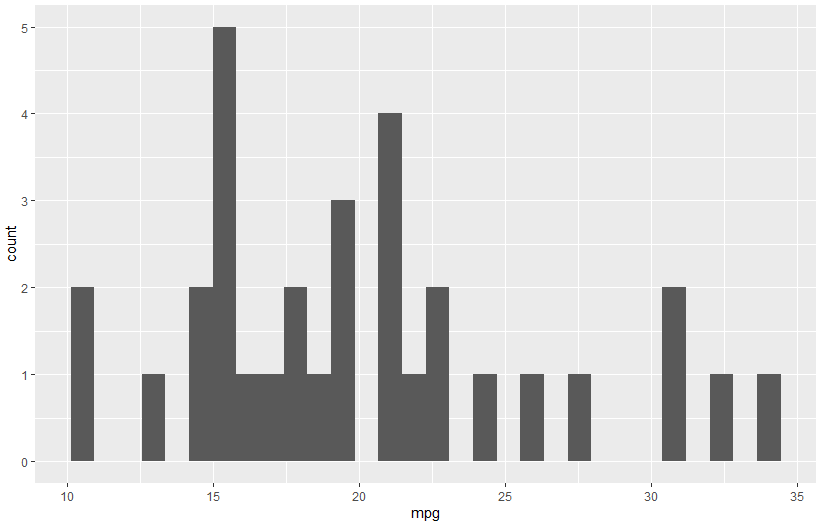
ggplot(data=mtcars, aes(x=mpg)) + geom_histogram()
ggsave(file="E:\\mygraph.pdf")
吴裕雄--天生自然 R语言数据可视化绘图(4)的更多相关文章
- 吴裕雄--天生自然 R语言数据可视化绘图(3)
par(ask=TRUE) opar <- par(no.readonly=TRUE) # record current settings # Listing 11.1 - A scatter ...
- 吴裕雄--天生自然 R语言数据可视化绘图(2)
par(ask=TRUE) opar <- par(no.readonly=TRUE) # save original parameter settings library(vcd) count ...
- 吴裕雄--天生自然 R语言数据可视化绘图(1)
par(ask=TRUE) opar <- par(no.readonly=TRUE) # make a copy of current settings attach(mtcars) # be ...
- 吴裕雄--天生自然 R语言开发学习:R语言的安装与配置
下载R语言和开发工具RStudio安装包 先安装R
- 吴裕雄--天生自然 R语言开发学习:数据集和数据结构
数据集的概念 数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量.表2-1提供了一个假想的病例数据集. 不同的行业对于数据集的行和列叫法不同.统计学家称它们为观测(observation)和 ...
- 吴裕雄--天生自然 R语言开发学习:导入数据
2.3.6 导入 SPSS 数据 IBM SPSS数据集可以通过foreign包中的函数read.spss()导入到R中,也可以使用Hmisc 包中的spss.get()函数.函数spss.get() ...
- 吴裕雄--天生自然 R语言开发学习:处理缺失数据的高级方法(续一)
#-----------------------------------# # R in Action (2nd ed): Chapter 18 # # Advanced methods for mi ...
- 吴裕雄--天生自然 R语言开发学习:R语言的简单介绍和使用
假设我们正在研究生理发育问 题,并收集了10名婴儿在出生后一年内的月龄和体重数据(见表1-).我们感兴趣的是体重的分 布及体重和月龄的关系. 可以使用函数c()以向量的形式输入月龄和体重数据,此函 数 ...
- 吴裕雄--天生自然 R语言开发学习:使用键盘、带分隔符的文本文件输入数据
R可从键盘.文本文件.Microsoft Excel和Access.流行的统计软件.特殊格 式的文件.多种关系型数据库管理系统.专业数据库.网站和在线服务中导入数据. 使用键盘了.有两种常见的方式:用 ...
随机推荐
- 如何理解 HTMLTestRunner 中 test (result)?UnitTest是如何运行的?
我们在用Unittest框架时,生成html格式的报告一般都是用HTMLTestRunner.py这个第三方库,大概使用方法如下: with open(config.report_file, 'wb' ...
- qt QSplitter分割窗口
#include <QApplication> #include <QFont> #include <QTextEdit> #include <QSplitt ...
- 静态代码块&非静态代码块&构造函数
总结:静态代码块总是最先执行.非静态代码块跟非静态方法一样,跟对象有关.只不过非静态代码块在构造函数之前执行.父类非静态代码块.构造函数执行完毕后(相当于父类对象初始化完成), 才开始执行子类的非静态 ...
- StackExchange.Redis 之 hash 类型示例
StackExchange.Redis 的组件封装示例网上有很多,自行百度搜索即可. 这里只演示如何使用Hash类型操作数据: // 在 hash 中存入或修改一个值 并设置order_hashkey ...
- landsat8波段叠加(layer stacking)
许久没更.最近一直在看IDL,忽略了gdal的学习. 今天做了landsat8的辐射定标,需要通过reflectance gains/bias来进行波段运算.由于landsat8 oli未提供一个完整 ...
- UnityTips:不要在发布版本中实现OnGUI方法
0x00 问题 不知道大家是否在调试Unity应用性能的时候发现过一条常见的Marker:UIEvents.IMGUIRenderOverlays. 很多情况下,这条叫做UIEvents.IMGUIR ...
- [Effective Java 读书笔记] 第二章 创建和销毁对象 第一条
第二章 创建和销毁对象 第一条 使用静态工厂方法替代构造器,原因: 静态工厂方法可以有不同的名字,也就是说,构造器只能通过参数的不同来区分不同的目的,静态工厂在名字上就能表达不同的目的 静态工厂方法 ...
- ajax 解决中文乱码问题
最近遇到了ajax 中文乱码的问题.下面总结一下 1. HTTP协议的编码规定 在HTTP协议中,浏览器不能向服务器直接传递某些特殊字符,必须是这些字符进行URL编码后再进行传送.url编码遵循的规则 ...
- 02_TypeScript数据类型
typescript中为了使编写的代码更规范,更有利于维护,增加了类型校验,写ts代码必须指定类型. 1.布尔类型(boolean) var flag:boolean = true; 2.数字 ...
- python OpenCV安装
linux系统 yum install -y libSM.x86_64 libXext.x86_64 libXrender.x86_64 pip install numpy Matplotlib pi ...