日志服务Python消费组实战(二):实时分发数据
场景目标
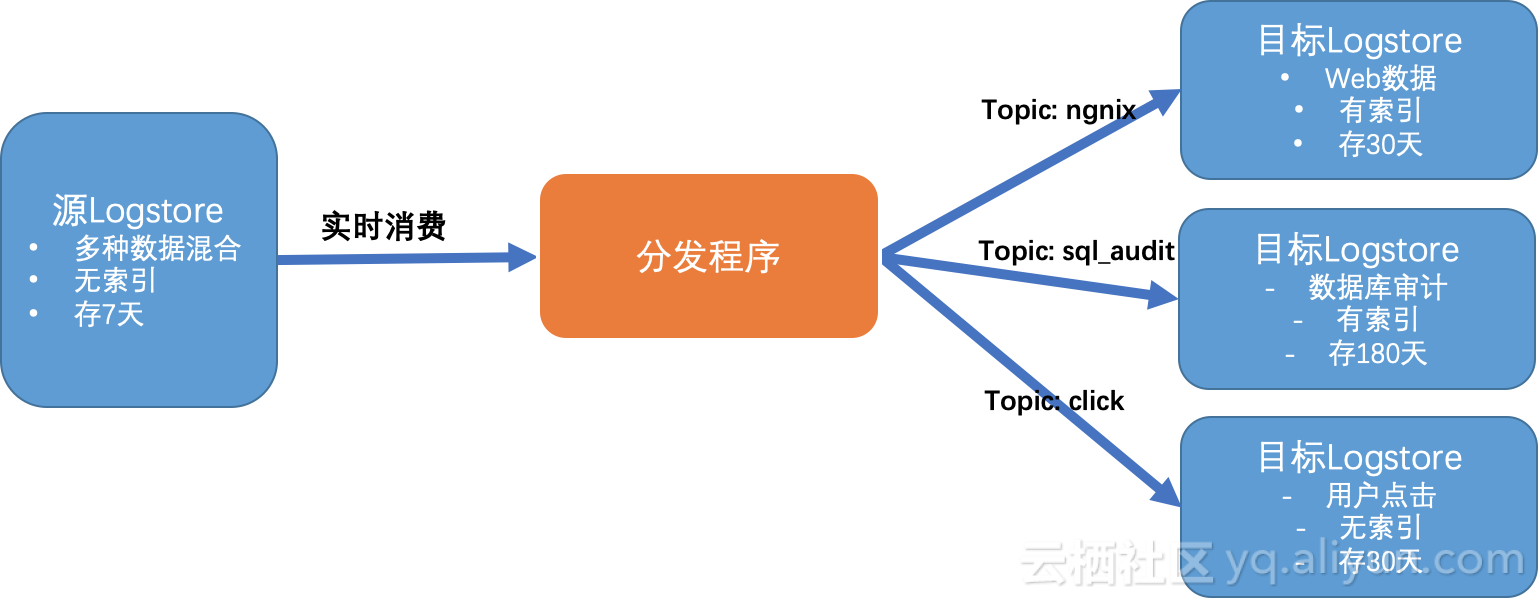
使用日志服务的Web-tracking、logtail(文件极简)、syslog等收集上来的日志经常存在各种各样的格式,我们需要针对特定的日志(例如topic)进行一定的分发到特定的logstore中处理和索引,本文主要介绍如何使用消费组实时分发日志到不通的目标日志库中。并且利用消费组的特定,达到自动平衡、负载均衡和高可用性。
基本概念
协同消费库(Consumer Library)是对日志服务中日志进行消费的高级模式,提供了消费组(ConsumerGroup)的概念对消费端进行抽象和管理,和直接使用SDK进行数据读取的区别在于,用户无需关心日志服务的实现细节,只需要专注于业务逻辑,另外,消费者之间的负载均衡、failover等用户也都无需关心。
消费组(Consumer Group) - 一个消费组由多个消费者构成,同一个消费组下面的消费者共同消费一个logstore中的数据,消费者之间不会重复消费数据。
消费者(Consumer) - 消费组的构成单元,实际承担消费任务,同一个消费组下面的消费者名称必须不同。
在日志服务中,一个logstore下面会有多个shard,协同消费库的功能就是将shard分配给一个消费组下面的消费者,分配方式遵循以下原则:
- 每个shard只会分配到一个消费者。
- 一个消费者可以同时拥有多个shard。
新的消费者加入一个消费组,这个消费组下面的shard从属关系会调整,以达到消费负载均衡的目的,但是上面的分配原则不会变,分配过程对用户透明。
协同消费库的另一个功能是保存checkpoint,方便程序故障恢复时能接着从断点继续消费,从而保证数据不会被重复消费。
使用消费组进行实时分发
这里我们描述用Python使用消费组进行编程,实时根据数据的topic进行分发。
注意:本篇文章的相关代码可能会更新,最新版本在这里可以找到:Github样例.
安装
环境
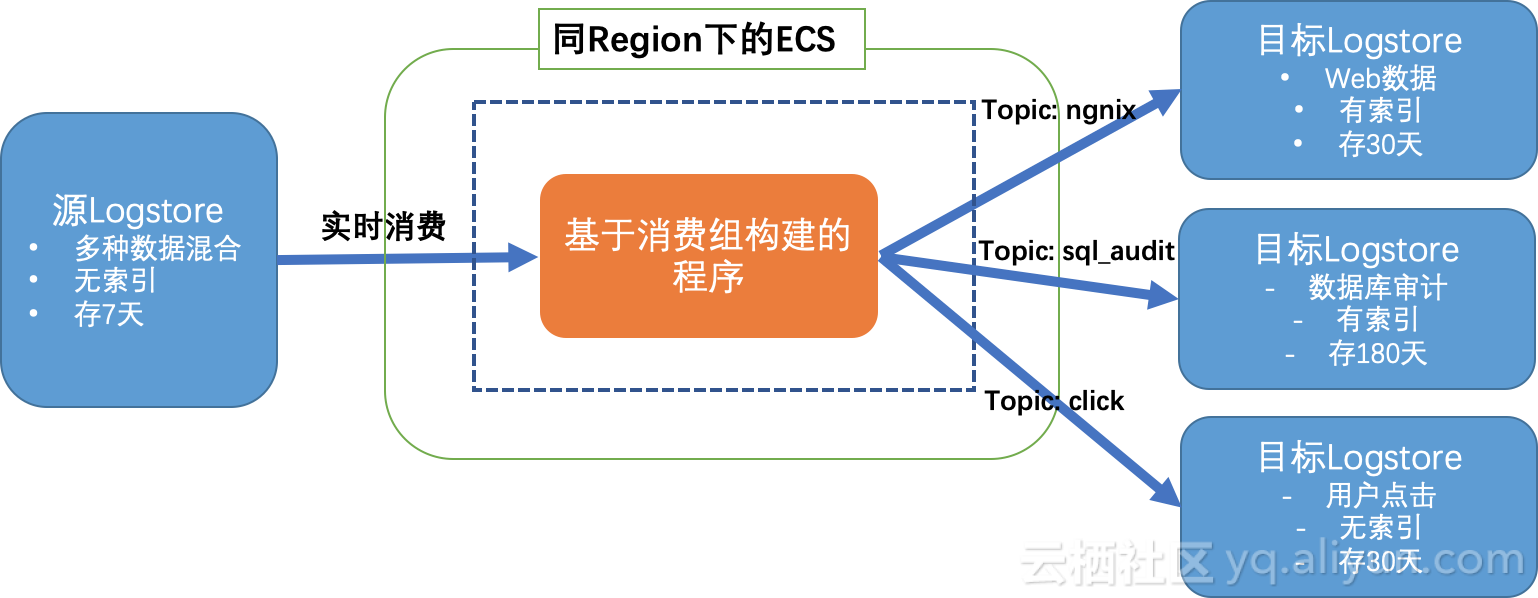
- 建议程序运行在源日志库同Region下的ECS上,并使用局域网服务入口,这样好处是网络速度最快,其次是读取没有外网费用产生。
- 强烈推荐PyPy3来运行本程序,而不是使用标准CPython解释器。
- 日志服务的Python SDK可以如下安装:
pypy3 -m pip install aliyun-log-python-sdk -U更多SLS Python SDK的使用手册,可以参考这里
程序配置
如下展示如何配置程序:
- 配置程序日志文件,以便后续测试或者诊断可能的问题(跳过,具体参考样例)。
- 基本的日志服务连接与消费组的配置选项。
- 目标Logstore的一些连接信息
请仔细阅读代码中相关注释并根据需要调整选项:
#encoding: utf8
def get_option():
##########################
# 基本选项
##########################
# 从环境变量中加载SLS参数与选项,根据需要可以配置多个目标
accessKeyId = os.environ.get('SLS_AK_ID', '')
accessKey = os.environ.get('SLS_AK_KEY', '')
endpoint = os.environ.get('SLS_ENDPOINT', '')
project = os.environ.get('SLS_PROJECT', '')
logstore = os.environ.get('SLS_LOGSTORE', '')
to_endpoint = os.environ.get('SLS_ENDPOINT_TO', endpoint)
to_project = os.environ.get('SLS_PROJECT_TO', project)
to_logstore1 = os.environ.get('SLS_LOGSTORE_TO1', '')
to_logstore2 = os.environ.get('SLS_LOGSTORE_TO2', '')
to_logstore3 = os.environ.get('SLS_LOGSTORE_TO3', '')
consumer_group = os.environ.get('SLS_CG', '')
# 消费的起点。这个参数在第一次跑程序的时候有效,后续再次运行将从上一次消费的保存点继续。
# 可以使”begin“,”end“,或者特定的ISO时间格式。
cursor_start_time = "2018-12-26 0:0:0"
# 一般不要修改消费者名,尤其是需要并发跑时
consumer_name = "{0}-{1}".format(consumer_group, current_process().pid)
# 构建一个消费组和消费者
option = LogHubConfig(endpoint, accessKeyId, accessKey, project, logstore, consumer_group, consumer_name, cursor_position=CursorPosition.SPECIAL_TIMER_CURSOR, cursor_start_time=cursor_start_time)
# bind put_log_raw which is faster
to_client = LogClient(to_endpoint, accessKeyId, accessKey)
put_method1 = partial(to_client.put_log_raw, project=to_project, logstore=to_logstore1)
put_method2 = partial(to_client.put_log_raw, project=to_project, logstore=to_logstore2)
put_method3 = partial(to_client.put_log_raw, project=to_project, logstore=to_logstore3)
return option, {u'ngnix': put_method1, u'sql_audit': put_method2, u'click': put_method3}注意,这里使用了functools.partial对put_log_raw进行绑定,以便后续调用方便。
数据消费与分发
如下代码展示如何从SLS拿到数据后根据topic进行转发。
if __name__ == '__main__':
option, put_methods = get_copy_option()
def copy_data(shard_id, log_groups):
for log_group in log_groups.LogGroups:
# update topic
if log_group.Topic in put_methods:
put_methods[log_group.Topic](log_group=log_group)
logger.info("*** start to consume data...")
worker = ConsumerWorker(ConsumerProcessorAdaptor, option, args=(copy_data, ))
worker.start(join=True)启动
假设程序命名为"dispatch_data.py",可以如下启动:
export SLS_ENDPOINT=<Endpoint of your region>
export SLS_AK_ID=<YOUR AK ID>
export SLS_AK_KEY=<YOUR AK KEY>
export SLS_PROJECT=<SLS Project Name>
export SLS_LOGSTORE=<SLS Logstore Name>
export SLS_LOGSTORE_TO1=<SLS To Logstore1 Name>
export SLS_LOGSTORE_TO1=<SLS To Logstore2 Name>
export SLS_LOGSTORE_TO1=<SLS To Logstore3 Name>
export SLS_CG=<消费组名,可以简单命名为"dispatch_data">
pypy3 dispatch_data.py性能考虑
启动多个消费者
基于消费组的程序可以直接启动多次以便达到并发作用:
nohup pypy3 dispatch_data.py &
nohup pypy3 dispatch_data.py &
nohup pypy3 dispatch_data.py &
...注意:
所有消费者使用了同一个消费组的名字和不同的消费者名字(因为消费者名以进程ID为后缀)。
因为一个分区(Shard)只能被一个消费者消费,假设一个日志库有10个分区,那么最多有10个消费者同时消费。
性能吞吐
基于测试,在没有带宽限制、接收端速率限制(如Splunk端)的情况下,以推进硬件用pypy3运行上述样例,单个消费者占用大约10%的单核CPU下可以消费达到5 MB/s原始日志的速率。因此,理论上可以达到50 MB/s原始日志每个CPU核,也就是每个CPU核每天可以消费4TB原始日志。
注意: 这个数据依赖带宽、硬件参数和目标Logstore是否能够较快接收数据。
高可用性
消费组会将检测点(check-point)保存在服务器端,当一个消费者停止,另外一个消费者将自动接管并从断点继续消费。
可以在不同机器上启动消费者,这样当一台机器停止或者损坏的清下,其他机器上的消费者可以自动接管并从断点进行消费。
理论上,为了备用,也可以启动大于shard数量的消费者。
其他
限制与约束
每一个日志库(logstore)最多可以配置10个消费组,如果遇到错误ConsumerGroupQuotaExceed则表示遇到限制,建议在控制台端删除一些不用的消费组。
监测
Https
如果服务入口(endpoint)配置为https://前缀,如https://cn-beijing.log.aliyuncs.com,程序与SLS的连接将自动使用HTTPS加密。
服务器证书*.aliyuncs.com是GlobalSign签发,默认大多数Linux/Windows的机器会自动信任此证书。如果某些特殊情况,机器不信任此证书,可以参考这里下载并安装此证书。
更多案例
- 日志服务Python消费组实战(一):日志服务与SIEM(如Splunk)集成实战
- 日志服务Python消费组实战(二):实时日志分发
- 日志服务Python消费组实战(三):实时跨域监测多日志库数据
- 本文Github样例
日志服务Python消费组实战(二):实时分发数据的更多相关文章
- 日志服务Python消费组实战(三):实时跨域监测多日志库数据
解决问题 使用日志服务进行数据处理与传递的过程中,你是否遇到如下监测场景不能很好的解决: 特定数据上传到日志服务中需要检查数据内的异常情况,而没有现成监控工具? 需要检索数据里面的关键字,但数据没有建 ...
- Spring Cloud架构教程 (八)消息驱动的微服务(消费组)【Dalston版】
使用消费组实现消息消费的负载均衡 通常在生产环境,我们的每个服务都不会以单节点的方式运行在生产环境,当同一个服务启动多个实例的时候,这些实例都会绑定到同一个消息通道的目标主题(Topic)上. 默认情 ...
- kafka 消费组功能验证以及消费者数据重复数据丢失问题说明 3
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94 背景 上一篇文章记录了kafka的副本机制和容错功能的说明,本篇则主要在上一篇文章的基础上 ...
- Python网络爬虫实战(二)数据解析
上一篇说完了如何爬取一个网页,以及爬取中可能遇到的几个问题.那么接下来我们就需要对已经爬取下来的网页进行解析,从中提取出我们想要的数据. 根据爬取下来的数据,我们需要写不同的解析方式,最常见的一般都是 ...
- Python模拟登录实战(二)
目标:1.模拟登录豆瓣,2.自动更改签名和发表说说. 代码如下: #!/usr/bin/env python # -*- coding:utf-8 -*- __author__ = 'ziv·chan ...
- Docker最全教程之Python爬网实战(二十一)
Python目前是流行度增长最快的主流编程语言,也是第二大最受开发者喜爱的语言(参考Stack Overflow 2019开发者调查报告发布).笔者建议.NET.Java开发人员可以将Python发展 ...
- 自学Python九 爬虫实战二(美图福利)
作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛YY看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页费劲!今天我们就搞 ...
- Python核心技术与实战——二一|巧用上下文管理器和with语句精简代码
我们在Python中对于with的语句应该是不陌生的,特别是在文件的输入输出操作中,那在具体的使用过程中,是有什么引伸的含义呢?与之密切相关的上下文管理器(context manager)又是什么呢? ...
- Python核心技术与实战——二十|assert的合理利用
我们平时在看代码的时候,或多或少会看到过assert的存在,并且在有些code review也可以通过增加assert来使代码更加健壮.但是即便如此,assert还是很容易被人忽略,可是这个很不起眼的 ...
随机推荐
- [转] undefined reference to `clock_gettime'
下面这个错误通常是因为链接选项里漏了-lrt,但有时发现即使加了-lrt仍出现这个问题,使用nm命令一直,会发现-lrt最终指向的文件 没有包含任何symbol,这个时候,可以找相应的静态库版本lib ...
- ElasticSearch 索引查询使用指南
1.检测集群是否健康,我们通常用下面的命令.确保9200端口号可用: http://localhost:9200/_cat/health?v 或者 http://localhost:9200/_clu ...
- Dubbo 3.0 预览版解读,6到飞起~
, false).start(); ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(new St ...
- nginx之tcp负载代理
大多数人针对nginx的负载均衡代理都是停留在HTTP代理那一块,我也一样:然而最近遇到了一个小问题,下面简单的叙述一下: 1.开发那边使用java代码进行ssh连接Linux服务器,然后执行bash ...
- 22个Photoshop网页设计教程网站推荐
这些网站都会经常更新一些优秀且高质量的Web界面设计教程.如果你热爱网页设计并且经常搜集各种界面设计教程,那么你一定要把下面这些网站收藏起来. 您还可以参考以下网页设计相关教程及资源:<Web ...
- 我也可以独立(引用JS外部文件)
我也可以独立(引用JS外部文件) 通过前面知识学习,我们知道使用<script>标签在HTML文件中添加JavaScript代码,如图: JavaScript代码只能写在HTML文件中吗? ...
- TCP/IP协议,,OSI的七层参考模型,HTTP请求响应机制
一.TCP/IP协议 TCP/IP是Transmission Control Protocol/Internet Protocol的简写,中译名为传输控制协议/因特网互联协议,又名网络通讯协议,是In ...
- 【数论】[SDOI2010]古代猪文
大概就是求这个: $$G^\sum_{k|N} C_{n}^{k}$$ 显然只要把后面的$\sum_{k|N}C_{n}^{k}$求出来就好了 几个要用的定理: 欧拉定理的推论:(a和n互质) $$a ...
- Python re标准库
re模块包含对正则表达式的支持. 一.什么是正则表达式 正则表达式是可以匹配文本片段的模式.最简单的正则表达是就是普通字符串,可以匹配其自身.你可以用这种匹配行为搜索文本中的模式,或者用计算后的值替换 ...
- CSIC_716_20191115【内置函数、递归、模块、软件开发规范】
内置函数 map map映射:语法结构(函数对象,可迭代对象) 依次从可迭代对象中取值,然后给函数做运算,再依次返回运算的结果. ss = map(lambda x: x + x, [1, 2, 3] ...