CentOS7.5搭建Solr7.4.0集群服务
一.Solr集群概念
solr单机版搭建参考: https://www.cnblogs.com/frankdeng/p/9615253.html
1.概念
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
2.结构
SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud需要由多台服务器组成,由zookeeper来进行协调管理。
二.Solr集群安装
这里把solr当成独立服务安装,官方参考文档:http://lucene.apache.org/solr/guide/7_4/taking-solr-to-production.html#taking-solr-to-production
1. 安装环境,集群部署
| 系统 | 节点名称 | IP |
Java |
zookeeper |
Solr |
|---|---|---|---|---|---|
| CentOS7.5 | node21 | 192.168.100.21 | √ | √ | 8983/8984 |
| CentOS7.5 | node22 | 192.168.100.22 | √ | √ | 8983/8984 |
| CentOS7.5 | node23 | 192.168.100.23 | √ | √ |
Zookeeper集群安装参考:https://www.cnblogs.com/frankdeng/p/9018177.html ,启动zookeeper集群 zkServer.sh start
2. 解压安装包,运行安装脚本
[admin@node21 software]$ tar zxvf solr-7.4..tgz

[admin@node21 software]$ tar xzf solr-7.4..tgz solr-7.4./bin/install_solr_service.sh --strip-components=
上一个命令将install_solr_service.sh脚本从存档中提取到当前目录中,如果在Red Hat上安装,请确保在运行Solr安装脚本()之前安装了lsof,sudo yum install lsof。安装脚本必须以root身份运行:下一个命令时运行服务安装脚本。
[admin@node21 software]$ sudo bash ./install_solr_service.sh solr-7.4..tgz -i /opt/module/solr -d /opt/module/solr/solrhome -u solr -s solr -p
报错找不到JAVA_HOME,原因:如果使用bash,建议将其放入/etc/bashrc(基于RH)或/etc/bash.bashrc(基于Debian)

[root@node21 software]# bash ./install_solr_service.sh solr-7.4..tgz -i /opt/module/solr -d /opt/module/solr/solrhome -u solr -s solr -p
切换root用户再次执行安装成功,默认情况下,脚本将分发存档解压缩/opt,配置Solr以将文件写入/var/solr,并以solr用户身份运行Solr ,也可以指定路径,安装信息如下
[root@node21 software]# bash ./install_solr_service.sh solr-7.4..tgz -i /opt/module/solr -d /opt/module/solr/solrhome -u solr -s solr -p
We recommend installing the 'lsof' command for more stable start/stop of Solr
id: solr: no such user
Creating new user: solr Extracting solr-7.4..tgz to /opt/module/solr Installing symlink /opt/module/solr/solr -> /opt/module/solr/solr-7.4. ... Installing /etc/init.d/solr script ... Installing /etc/default/solr.in.sh ... Service solr installed.
Customize Solr startup configuration in /etc/default/solr.in.sh
*** [WARN] *** Your Max Processes Limit is currently 4096.
It should be set to 65000 to avoid operational disruption.
If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
NOTE: Please install lsof as this script needs it to determine if Solr is listening on port . Started Solr server on port (pid=). Happy searching! Found Solr nodes: Solr process running on port
INFO - -- ::26.210; org.apache.solr.util.configuration.SSLCredentialProviderFactory; Processing SSL Credential Provider chain: env;sysprop
{
"solr_home":"/opt/module/solr/data/data",
"version":"7.4.0 9060ac689c270b02143f375de0348b7f626adebc - jpountz - 2018-06-18 16:55:13",
"startTime":"2018-09-07T15:39:11.678Z",
"uptime":"0 days, 0 hours, 0 minutes, 19 seconds",
"memory":"25.3 MB (%5.2) of 490.7 MB"} [root@node21 software]#

3.安装多个solr服务
node21上再实例化一个solr2,端口8984
[root@node21 software]# mkdir /opt/module/solr2
[root@node21 software]# bash ./install_solr_service.sh solr-7.4..tgz -i /opt/module/solr2 -d /opt/module/solr2/solrhome -u solr -s solr2 -p
安装脚本,安装包拷贝一份到node22上,实例化solr 8983,solr2 8984两个服务。
[root@node21 software]# scp -r install_solr_service.sh solr-7.4..tgz root@node22:`pwd`
[root@node22 software]# mkdir /opt/module/solr
[root@node22 software]# bash ./install_solr_service.sh solr-7.4..tgz -i /opt/module/solr -d /opt/module/solr/solrhome -u solr -s solr -p 8983
[root@node22 software]# mkdir /opt/module/solr2
[root@node22 software]# bash ./install_solr_service.sh solr-7.4..tgz -i /opt/module/solr2 -d /opt/module/solr2/solrhome -u solr -s solr2 -p 8984
启动停止验证服务命令
#在root用户下操作
service solr start|stop|status
service solr2 start|stop|ststus
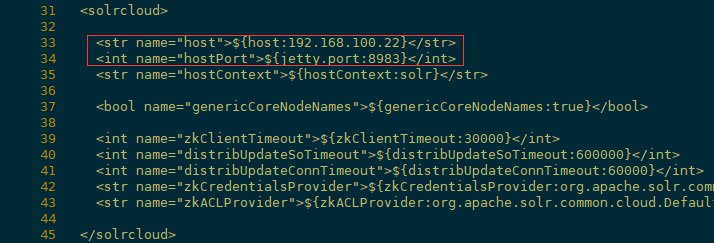
修改对应jetty服务的端口8983/8984
[root@node21 solr]# vi /opt/module/solr/solrhome/data/solr.xml
[root@node21 solr]# vi /opt/module/solr2/solrhome/data/solr.xml
[root@node22 solr]# vi /opt/module/solr/solrhome/data/solr.xml
[root@node22 solr]# vi /opt/module/solr2/solrhome/data/solr.xml
4. 配置zk启动优先级
solr集群需要zk来管理节点,目前solr是开机自启动,然后自己手工再启动zookeeper,solr是不能访问的,要求zookeeper集群先于solr集群启动,因此在设置zookeeper集群开机启动前要先查看solr开机启动的优先级 ls /etc/rc3.d/*solr*

"S50solr"分析:
S:代表启动
50:代表启动的顺序,值越小越先启动
solr:服务名字,就是/etc/init.d中的文件名
因zookeeper要先于solr启动,所以它的启动顺序对应的值应该小于50
编写脚本设置zookeeper开机启动
[root@node21 software]# vi /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:
#description:zookeeper
#processname:zookeeper
export JAVA_HOME=/opt/module/jdk1.
export ZOO_LOG_DIR=/opt/module/zookeeper-3.4./logs
case $ in
start) su root /opt/module/zookeeper-3.4./bin/zkServer.sh start;;
stop) su root /opt/module/zookeeper-3.4./bin/zkServer.sh stop;;
status) su root /opt/module/zookeeper-3.4./bin/zkServer.sh status;;
restart) su root /opt/module/zookeeper-3.4./bin/zkServer.sh restart;;
*) echo "require start|stop|status|restart" ;;
esac
其中chkconfig:2345 20 90非常重要
2345:为主机运行的级别,表示主机运行在2、3、4、5个级别时都会启动zookeeper,而0 、1、6级别时停止zookeeper
20:开机启动的优先级,要比solr的50大
90:关机停止的顺序
一般设置时,先启动,则后停止,注意不要把启动值设置得太小,否则可能一些系统核心服务还没有启动起来,导致你的应用无法启动
JAVA_HOME是必须的
ZOO_LOG_DIR是可选的,用于保存zookeeper启动时的日志文件,我把它指定到了自定义目录,否则你得使用root用户启动zookeeper或者给root用户根目录的写权限授予给zookeeper的启动用户
赋权限给脚本,启动zookeeper,设置为开机启动
[root@node21 software]# chmod +x /etc/init.d/zookeeper
[root@node21 software]# service zookeeper start
[root@node21 software]# chkconfig --add zookeeper
然后去/etc/rc3.d中查看zookeeper的启动顺序,查看zookeeper的停止顺序
[root@node21 software]# ls /etc/rc3.d/*zoo*
/etc/rc3.d/S20zookeeper
[root@node21 software]# ls /etc/rc0.d/*zoo*
/etc/rc0.d/K90zookeeper
5. 关联solr集群与zk集群
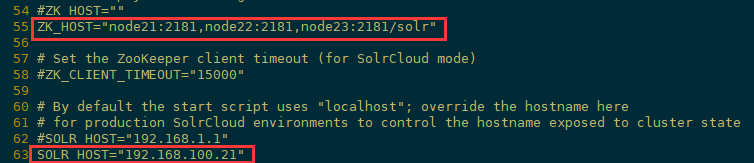
1)设置zookeeper集群关联solr集群,更新Solr的包含文件(solr.in.sh或solr.in.cmd),这样就不必在启动Solr时输入zk连接地址。
[root@node21 solr]# vi /etc/default/solr.in.sh vi /etc/default/solr2.in.sh
[root@node22 solr]# vi /etc/default/solr.in.sh vi /etc/default/solr2.in.sh
修改如下信息(对应主机host注意更改):
ZK_HOST="node21:2181,node22:2181,node23:2181/solr"
SOLR_HOST="192.168.100.21"
首次连接需要创建节点管理目录
[root@node21 solr]# ./solr/bin/solr zk mkroot /solr -z node21:,node22:,node23:
2)使用Solr的ZooKeeper CLI上传solr配置信息到zk节点
[root@node21 module]# sh solr/solr-7.4./server/scripts/cloud-scripts/zkcli.sh -zkhost node21:,node22:,node23: -cmd upconfig -confdir /opt/module/solr/solr-
7.4./server/solr/configsets/_default/conf -confname myconf
查看配置文件是否上传成功,zk客户端查看zkCli.sh
[zk: localhost:(CONNECTED) ] ls /configs/myconf
[protwords.txt, managed-schema, solrconfig.xml, synonyms.txt, stopwords.txt, lang, params.json]
[zk: localhost:(CONNECTED) ] ls /solr/configs/_default
[managed-schema, protwords.txt, solrconfig.xml, synonyms.txt, stopwords.txt, lang, params.json]
6.配置solr集群的分片规则
创建core与collection,分片规则可以自定义,也可以自动分配,我这里采取自动分配
[root@node21 solr]# ./solr/bin/solr create -c collection1 -n collection1 -shards -replicationFactor -p -force
[root@node22 solr2]# ./solr2/bin/solr create -c collection2 -n collection2 -shards -replicationFactor -p -force
参数说明:
-c <name> 要创建的核心或集合的名称(必需)。
-n <configName> 配置名称,默认与核心或集合的名称相同。
-p <port> 发送create命令的本地Solr实例的端口; 默认情况下,脚本会尝试通过查找正在运行的Solr实例来检测端口。
-s <shards> 要么 -shards 将集合拆分为的分片数,默认为1; 仅适用于Solr在SolrCloud模式下运行的情况。
-rf <replicas> 要么 -replicationFactor 集合中每个文档的副本数。默认值为1(无复制)。
-force 如果尝试以“root”用户身份运行create,则脚本将退出并显示运行Solr或针对Solr的操作作为“root”的警告可能会导致问题。可以使用-force参数覆盖此警告。
-d <confdir> 配置目录。默认为_default。
7. Web界面查看solr集群状态
solr默认端口,查看地址:http://192.168.100.21:8983/solr/#/
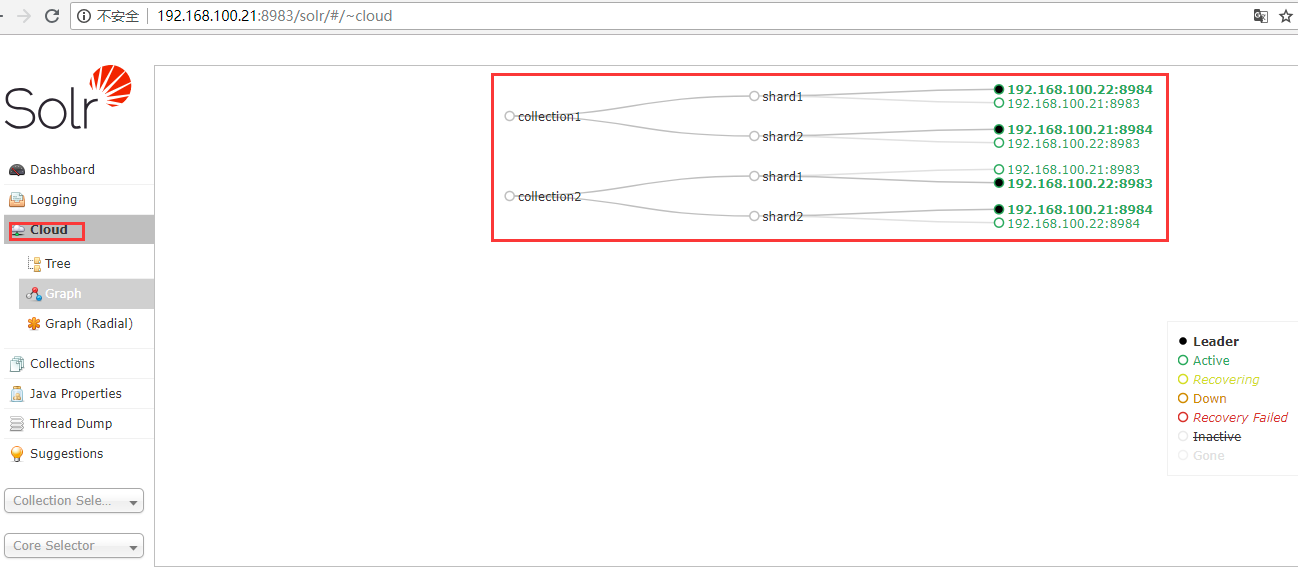
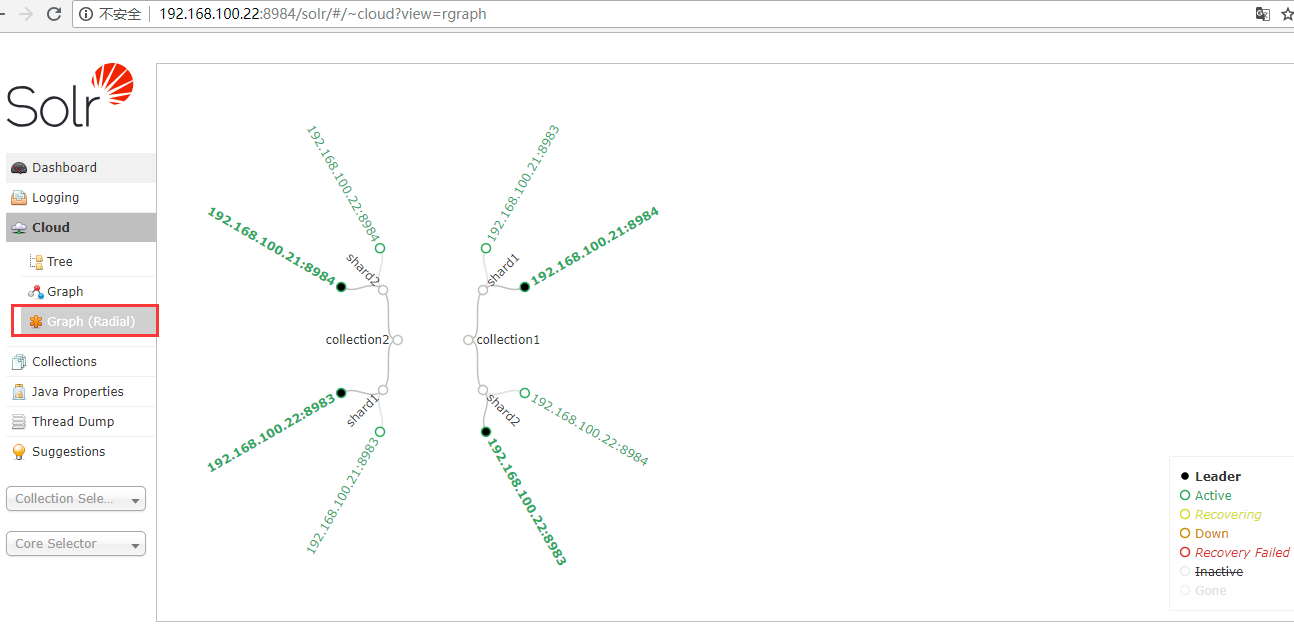
zk客户端查看solr集群信息


jps查看服务进程
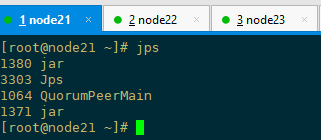
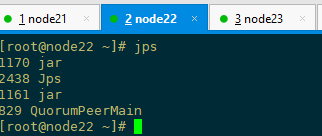
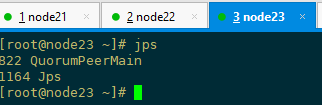
删除core与collection
[root@node21 solr]# ./solr/bin/solr delete -c collection1
INFO - -- ::04.479; org.apache.solr.util.configuration.SSLCredentialProviderFactory; Processing SSL Credential Provider chain: env;sysprop
{
"responseHeader":{
"status":,
"QTime":},
"success":{
"192.168.100.21:8983_solr":{"responseHeader":{
"status":,
"QTime":}},
"192.168.100.21:8984_solr":{"responseHeader":{
"status":,
"QTime":}},
"192.168.100.22:8983_solr":{"responseHeader":{
"status":,
"QTime":}},
"192.168.100.22:8984_solr":{"responseHeader":{
"status":,
"QTime":}}}} Deleted collection 'collection1' using command:
http://192.168.100.21:8984/solr/admin/collections?action=DELETE&name=collection1
8. 安装IK中文分词器
解压ik中文分词安装包
[root@node21 software]# ls ikanalyzer-solr5/
ext.dic IKAnalyzer.cfg.xml ik-analyzer-solr5-5.x.jar solr-analyzer-ik-5.1.0.jar stopword.dic
1)将IK分词器 JAR 包拷贝到各solr安装节点solr-7.4.0/server/solr-webapp/webapp/WEB-INF/lib/下
[root@node21 ikanalyzer-solr5]# cp ik-analyzer-solr5-5.x.jar solr-analyzer-ik-5.1.0.jar /opt/module/solr/solr-7.4.0/server/solr-webapp/webapp/WEB-INF/lib/
2)将词典 配置文件拷贝到各solr节点solr-7.4.0/server/solr-webapp/webapp/WEB-INF/classes下
[root@node21 ikanalyzer-solr5]# mkdir -p /opt/module/solr/solr-7.4.0/server/solr-webapp/webapp/WEB-INF/classes
[root@node21 ikanalyzer-solr5]# cp ext.dic IKAnalyzer.cfg.xml stopword.dic /opt/module/solr/solr-7.4.0/server/solr-webapp/webapp/WEB-INF/classes


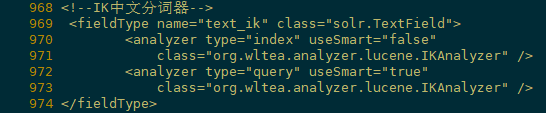
3)更改在solr-7.4.0/server/solr/configsets/_default/conf/managed-schema配置文件,末尾添加以下保存
[root@node21 software]# vi /opt/module/solr/solr-7.4.0/server/solr/configsets/_default/conf/managed-schema
<!--IK中文分词器-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false"
class="org.wltea.analyzer.lucene.IKAnalyzer" />
<analyzer type="query" useSmart="true"
class="org.wltea.analyzer.lucene.IKAnalyzer" />
</fieldType>
4)更新配置文件到zk节点
[root@node21 module]# sh /opt/module/solr/solr-7.4.0/server/scripts/cloud-scripts/zkcli.sh -zkhost node21:2181,node22:2181,node23:2181 -cmd upconfig -confdir /opt/modu
le/solr/solr-7.4.0/server/solr/configsets/_default/conf -confname myconf
5)重启服务测试中文分词
root@node21 solr]# ./solr/bin/solr create -c collection3 -n collection3 -shards 2 -replicationFactor 2 -p 8983 -force

三.设置禁止开机启动项
测试完毕之后,我这里设置solr与zookeeper服务禁止开机启动,
显示开机可以自动启动的服务
[root@node21 ~]# chkconfig --list
添加开机自动启动***服务
[root@node21 ~]# chkconfig --add ***
删除开机自动启动***服务
[root@node21 ~]# chkconfig --del ***
查看
[root@node21 ~]# chkconfig --list Note: This output shows SysV services only and does not include native
systemd services. SysV configuration data might be overridden by native
systemd configuration. If you want to list systemd services use 'systemctl list-unit-files'.
To see services enabled on particular target use
'systemctl list-dependencies [target]'. netconsole :off :off :off :off :off :off :off
network :off :off :on :on :on :on :off
redis_6379 :off :off :on :on :on :on :off
solr :off :off :on :on :on :on :off
solr2 :off :off :on :on :on :on :off
zookeeper :off :off :on :on :on :on :off xinetd based services:
chargen-dgram: off
chargen-stream: off
daytime-dgram: off
daytime-stream: off
discard-dgram: off
discard-stream: off
echo-dgram: off
echo-stream: off
tcpmux-server: off
time-dgram: off
time-stream: off
之后手动启动
[root@node23 ~]# service zookeeper start
[root@node23 ~]# service solr start
[root@node23 ~]# service solr2 start
其他明细参考文档:https://www.cnblogs.com/jepson6669/p/9134652.html
https://my.oschina.net/u/3049601/blog/1800909
CentOS7.5搭建Solr7.4.0集群服务的更多相关文章
- 在CentOS7下搭建Hadoop2.9.0集群
系统环境:CentOS 7 JDK版本:jdk-8u191-linux-x64 MYSQL版本:5.7.26 Hadoop版本:2.9.0 Hive版本:2.3.4 Host Name Ip User ...
- CentOS7.5搭建spark2.3.1集群
一 下载安装包 1 官方下载 官方下载地址:http://spark.apache.org/downloads.html 2 安装前提 Java8 安装成功 zookeeper 安 ...
- Storm(二)CentOS7.5搭建Storm1.2.2集群
一.Storm的下载 官网下载地址:http://storm.apache.org/downloads.html 这里下载最新的版本storm1.2.2,进入之后选择一个镜像下载 二.Storm伪分布 ...
- HBase(二)CentOS7.5搭建HBase1.2.6HA集群
一.安装前提 1.HBase 依赖于 HDFS 做底层的数据存储 2.HBase 依赖于 MapReduce 做数据计算 3.HBase 依赖于 ZooKeeper 做服务协调 4.HBase源码是j ...
- Spring Cloud Alibaba(7)---docker-compose搭建nacos1.4.0集群
docker-compose搭建nacos1.4.0集群 有关Nacos之前写过四篇文章. Spring Cloud Alibaba(3)---Nacos概述 Spring Cloud Alibaba ...
- CentOS6.4上搭建hadoop-2.4.0集群
公司Commerce Cloud平台上提供申请主机的服务.昨天试了下,申请了3台机器,搭了个hadoop环境.以下是机器的一些配置: emi-centos-6.4-x86_64medium | 6GB ...
- CentOS7搭建Hadoop2.8.0集群及基础操作与测试
环境说明 示例环境 主机名 IP 角色 系统版本 数据目录 Hadoop版本 master 192.168.174.200 nameNode CentOS Linux release 7.4.1708 ...
- CentOS7搭建Hadoop-3.3.0集群手记
前提 这篇文章是基于Linux系统CentOS7搭建Hadoop-3.3.0分布式集群的详细手记. 基本概念 Hadoop中的HDFS和YARN都是主从架构,主从架构会有一主多从和多主多从两种架构,这 ...
- centos7 下搭建hadoop2.9 分布式集群
首先说明,本文记录的是博主搭建的3节点的完全分布式hadoop集群的过程,环境是centos 7,1个nameNode,2个dataNode,如下: 1.首先,创建好3个Centos7的虚拟机,具体的 ...
随机推荐
- VC++调用MSFlexGrid的SetRow方法,出现异常“Invalid Row Value”
MSFlexGrid是微软提供的网格表格控件,SetRow方法用于设置当前焦点所在行. C++ Code 12345 void CMSFlexGrid::SetRow(long nNewVal ...
- VMware Playerでの仮想マシン起動エラー
Windows Updateすると.翌日VMware Playerの仮想マシン起動時に 「この仮想マシンを構成済み設定でパワーオンするのに十分な物理メモリがありません.」 のエラーとなることが時々あり ...
- 使用npm国内镜像
嫌npm指令速度慢的童鞋可以把npm的源转换成国内的即可提高响应速度: 镜像使用方法(三种办法任意一种都能解决问题,建议使用第1或者第3种,将配置写死,下次用的时候配置还在):1.通过config命令 ...
- vuejs使用FormData对象,ajax上传图片文件
我相信很多使用vuejs的朋友,都有采用ajax上传图片的需求,因为前后端分离后,我们希望都能用ajax来解决数据问题,传统的表单提交会导致提交成功后页面跳转,而使用ajax能够无刷新上传图片等文件. ...
- [NodeJS] Node.js 编码转换
Node.js 自带的 toString() 方法不支持 gbk,因此中文转换的时候需要加载第三方库,推荐以下两个编码转换库,iconv-lite 和 encoding. iconv, iconv-l ...
- C语言char*字符串数组和unsigned char[]数组的相互转换
#include <iostream> #include <string> using namespace std; void convertUnCharToStr(char* ...
- codeforces水题100道 第十五题 Codeforces Round #262 (Div. 2) A. Vasya and Socks (brute force)
题目链接:http://www.codeforces.com/problemset/problem/460/A题意:Vasya每天用掉一双袜子,她妈妈每m天给他送一双袜子,Vasya一开始有n双袜子, ...
- sql语句建表,并且自增加主键
sql语句建表,并且自增加主键 use [test] CREATE TABLE [dbo].[Table_4] ( [userid] [int] IDENTITY(1,1) NOT NULL, CON ...
- php API接口入门
1.简述: api接口开发,其实和平时开发逻辑差不多:但是也有略微差异: 平时使用mvc开发网站的思路一般是都 由控制器 去 调用模型,模型返回数据,再由控制器把数据放到视图中,展现给用户: api开 ...
- 基于链表的C语言堆内存检测
说明 本文基于链表实现C语言堆内存的检测机制,可检测内存泄露.越界和重复释放等操作问题. 本文仅提供即视代码层面的检测机制,不考虑编译链接级的注入或钩子.此外,该机制暂未考虑并发保护. 相关性文章参见 ...