Python -- Scrapy 架构概览
架构概览
本文档介绍了Scrapy架构及其组件之间的交互。
概述
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。 下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述。
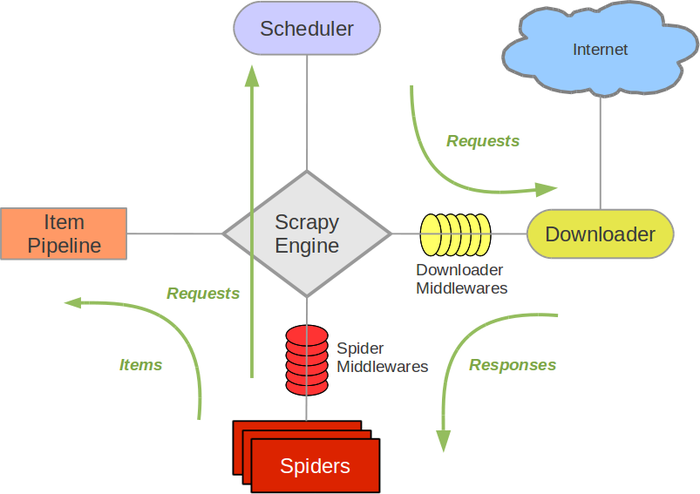
组件
引擎(Scrapy Engine)
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
爬虫(Spiders)
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
项目管道(Item Pipeline)
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
事件驱动网络(Event-driven networking)
Scrapy基于事件驱动网络框架 Twisted 编写。因此,Scrapy基于并发性考虑由非阻塞(即异步)的实现。
关于异步编程及Twisted更多的内容请查看下列链接:
Python -- Scrapy 架构概览的更多相关文章
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
- python Scrapy安装和介绍
python Scrapy安装和介绍 Windows7下安装1.执行easy_install Scrapy Centos6.5下安装 1.库文件安装yum install libxslt-devel ...
- scrapy架构初探
scrapy架构初探 引言 Python即时网络爬虫启动的目标是一起把互联网变成大数据库.单纯的开放源代码并不是开源的全部,开源的核心是"开放的思想",聚合最好的想法.技术.人员, ...
- Python——Scrapy初学
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中.Scrapy最初是为了页面抓取(更确切来说, 网络抓取)所设计的,也 ...
- scrapy架构简介
一.scrapy架构介绍 1.结构简图: 主要组成部分:Spider(产出request,处理response),Pipeline,Downloader,Scheduler,Scrapy Engine ...
- python Scrapy 从零开始学习笔记(一)
在之前我做了一个系列的关于 python 爬虫的文章,传送门:https://www.cnblogs.com/weijiutao/p/10735455.html,并写了几个爬取相关网站并提取有效信息的 ...
- python scrapy版 极客学院爬虫V2
python scrapy版 极客学院爬虫V2 1 基本技术 使用scrapy 2 这个爬虫的难点是 Request中的headers和cookies 尝试过好多次才成功(模拟登录),否则只能抓免费课 ...
- Python.Scrapy.14-scrapy-source-code-analysis-part-4
Scrapy 源代码分析系列-4 scrapy.commands 子包 子包scrapy.commands定义了在命令scrapy中使用的子命令(subcommand): bench, check, ...
随机推荐
- MySQL重装失败,could not start the service MySQL.Error:0
MySQL5.5 安装失败现象: mysqld.exe [6132] 中发生了未经处理的 win32 异常 could not start the service MySQL.Error:0 1.在 ...
- mysql备份恢复详解
前言 为什么需要备份数据? 数据的备份类型 MySQL备份数据的方式 备份需要考虑的问题 设计合适的备份策略 实战演练 使用cp进行备份 使用mysqldump+复制BINARY LOG备份 使用lv ...
- LINUX环境变量(二)
一.Shell变量分为本地变量和环境变量. 1.本地变量:在用户现有运行的脚本中使用 a) 定义本地变量 格式: variable-name=value b) 显示本地变量 格式: set c) 清 ...
- linux服务器管理员的12个有用的命令
ifconfig: 在修改内核中已有的网络接口时,你会用到ifconfig命令.这个命令通常用于系统调校和调试,但同时也可以用于在启动过程中设置接口. netstat: 对于Linux用户来说这是一个 ...
- java多线程----ReentrantReadWriteLock
package com.test; import java.util.concurrent.locks.ReadWriteLock; import java.util.concurrent.locks ...
- hue, saturation, and brightness:色调、饱和度和亮度
色调.饱和度和亮度(hue, saturation, and brightness)以人对红.绿.蓝(RGB)三色组合的感觉为基础.在描述阴极射线管显示器参数时,经常提到这三个专有名词.所有的颜色可以 ...
- Mysql的序列
Mysql的序列 Mysql自带的序列:字段设置为int,属性里面选上“自动增长”即可: 在插入数据的时候可以不插入该字段的值,mysql会自动处理:
- 20145106java实验四
实验名称:Java网络编程 实验内容: 1.掌握Socket程序的编写: 2.掌握密码技术的使用: 3.设计安全传输系统. 结对小伙伴 20145109竺文君 博客地址: 在本次实验中,是以我作为服务 ...
- STM32.定时器
一.定时器分类 11个定时器: 定时器: 1.8 高级(7路PWM输出) 2.3.4.5 通用(4路) 6.7 基本 2个看门狗 1个sysTick 时钟分布: 二.这里我们主要对定时器中 定 ...
- 维特比算法Python实现
前言 维特比算法是隐马尔科夫问题的一个基本问题算法.维特比算法解决的问题是已知观察序列,求最可能的标注序列. 什么是维特比算法? 维特比算法尽管是基于严格的数学模型的算法,但是维特比算法毕竟是算法,因 ...