python开发_pickle
pickle模块使用的数据格式是python专用的,并且不同版本不向后兼容,同时也不能被其他语言说识别。要和其他语言交互,可以使用内置的json包使用pickle模块你可以把Python对象直接保存到文件,而不需要把他们转化为字符串,也不用底层的文件访问操作把它们写入到一个二进制文件里。 pickle模块会创建一个python语言专用的二进制格式,你基本上不用考虑任何文件细节,它会帮你干净利落地完成读写独享操作,唯一需要的只是一个合法的文件句柄。
pickle模块中的两个主要函数是dump()和load()。dump()函数接受一个文件句柄和一个数据对象作为参数,把数据对象以特定的格式保存到给定的文件中。当我们使用load()函数从文件中取出已保存的对象时,pickle知道如何恢复这些对象到它们本来的格式。
dumps()函数执行和dump() 函数相同的序列化。取代接受流对象并将序列化后的数据保存到磁盘文件,这个函数简单的返回序列化的数据。
loads()函数执行和load() 函数一样的反序列化。取代接受一个流对象并去文件读取序列化后的数据,它接受包含序列化后的数据的str对象, 直接返回的对象。
cPickle是pickle得一个更快得C语言编译版本。
pickle和cPickle相当于java的序列化和反序列化操作
以上来源:http://www.2cto.com/kf/201009/74973.html
下面是python的API中的Example:
# Simple example presenting how persistent ID can be used to pickle
# external objects by reference. import pickle
import sqlite3
from collections import namedtuple # Simple class representing a record in our database.
MemoRecord = namedtuple("MemoRecord", "key, task") class DBPickler(pickle.Pickler): def persistent_id(self, obj):
# Instead of pickling MemoRecord as a regular class instance, we emit a
# persistent ID.
if isinstance(obj, MemoRecord):
# Here, our persistent ID is simply a tuple, containing a tag and a
# key, which refers to a specific record in the database.
return ("MemoRecord", obj.key)
else:
# If obj does not have a persistent ID, return None. This means obj
# needs to be pickled as usual.
return None class DBUnpickler(pickle.Unpickler): def __init__(self, file, connection):
super().__init__(file)
self.connection = connection def persistent_load(self, pid):
# This method is invoked whenever a persistent ID is encountered.
# Here, pid is the tuple returned by DBPickler.
cursor = self.connection.cursor()
type_tag, key_id = pid
if type_tag == "MemoRecord":
# Fetch the referenced record from the database and return it.
cursor.execute("SELECT * FROM memos WHERE key=?", (str(key_id),))
key, task = cursor.fetchone()
return MemoRecord(key, task)
else:
# Always raises an error if you cannot return the correct object.
# Otherwise, the unpickler will think None is the object referenced
# by the persistent ID.
raise pickle.UnpicklingError("unsupported persistent object") def main():
import io
import pprint # Initialize and populate our database.
conn = sqlite3.connect(":memory:")
cursor = conn.cursor()
cursor.execute("CREATE TABLE memos(key INTEGER PRIMARY KEY, task TEXT)")
tasks = (
'give food to fish',
'prepare group meeting',
'fight with a zebra',
)
for task in tasks:
cursor.execute("INSERT INTO memos VALUES(NULL, ?)", (task,)) # Fetch the records to be pickled.
cursor.execute("SELECT * FROM memos")
memos = [MemoRecord(key, task) for key, task in cursor]
# Save the records using our custom DBPickler.
file = io.BytesIO()
DBPickler(file).dump(memos) print("Pickled records:")
pprint.pprint(memos) # Update a record, just for good measure.
cursor.execute("UPDATE memos SET task='learn italian' WHERE key=1") # Load the records from the pickle data stream.
file.seek(0)
memos = DBUnpickler(file, conn).load() print("Unpickled records:")
pprint.pprint(memos) if __name__ == '__main__':
main()
运行效果:
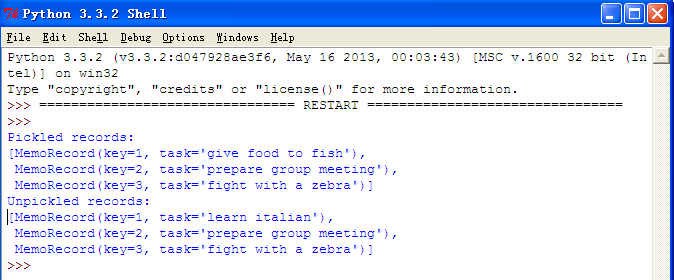
python开发_pickle的更多相关文章
- python开发环境搭建
虽然网上有很多python开发环境搭建的文章,不过重复造轮子还是要的,记录一下过程,方便自己以后配置,也方便正在学习中的同事配置他们的环境. 1.准备好安装包 1)上python官网下载python运 ...
- 【Machine Learning】Python开发工具:Anaconda+Sublime
Python开发工具:Anaconda+Sublime 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现 ...
- Python开发工具PyCharm个性化设置(图解)
Python开发工具PyCharm个性化设置,包括设置默认PyCharm解析器.设置缩进符为制表符.设置IDE皮肤主题等,大家参考使用吧. JetBrains PyCharm Pro 4.5.3 中文 ...
- Python黑帽编程1.2 基于VS Code构建Python开发环境
Python黑帽编程1.2 基于VS Code构建Python开发环境 0.1 本系列教程说明 本系列教程,采用的大纲母本为<Understanding Network Hacks Atta ...
- Eclipse中Python开发环境搭建
Eclipse中Python开发环境搭建 目 录 1.背景介绍 2.Python安装 3.插件PyDev安装 4.测试Demo演示 一.背景介绍 Eclipse是一款基于Java的可扩展开发平台. ...
- Python开发:环境搭建(python3、PyCharm)
Python开发:环境搭建(python3.PyCharm) python3版本安装 PyCharm使用(完全图解(最新经典))
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
随机推荐
- perl6 一个猜测密码的注入
use HTTP::UserAgent; my $ua = HTTP::UserAgent.new; my $r = HTTP::Request.new; my $c = HTTP::Cookies. ...
- [MySQL] gap lock/next-key lock浅析
当InnoDB在判断行锁是否冲突的时候, 除了最基本的IS/IX/S/X锁的冲突判断意外, InnoDB还将锁细分为如下几种子类型: record lock (RK) 记录锁, 仅仅锁住索引记录的一行 ...
- Deep Learning基础--word2vec 中的数学原理详解
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了很多人的关注.由于 word2vec 的作者 Tomas Miko ...
- python多线程下载文件
从文件中读取图片url和名称,将url中的文件下载下来.文件中每一行包含一个url和文件名,用制表符隔开. 1.使用requests请求url并下载文件 def download(img_url, i ...
- 基于TCP协议的聊天室控制台版
我之前写过一篇博客,主要是基于TCP协议实现的聊天室swing版,在此再写一个基于TCP协议实现的聊天室控制台版,便于学习和比较. package 聊天室console版.utils; import ...
- Oracle数据库(64位) 及 PLSQL(64位)的组合安装【第一篇】
目前PC端普遍使用64位操作系统,64位操作系统在性能上比32位更佳,但是兼容性上则不如32的操作系统,Oracle提供了64和32两种版本,而PLsql工具则只有32位,在这篇文章详细的讲述了如何在 ...
- yii2 GirdView使用全教程
开始GridView GridView主要是为了实现表格复用,尤其我们做后台的时候,你发现表单和表格占据了大部分页面,而表格的样式又是高度的统一,那么如果有这样一个挂件,传入数据集自动渲染表格该多好. ...
- tensorflow运行出现错误 : ImportError: Could not find 'cudart64_90.dll'.
安装 tensorflow-gpu 版本后,需要安装相应的 CUDA 和 cuDNN 注意版本问题:tensorflow-gpu 1.7以及之后的版本要安装 CUDA 8.0 以上的版本,tf 1.7 ...
- CentOS7.6安装screenfetch
方法1:yum install -y gitcd /usr/local/srcgit clone https://github.com/KittyKatt/screenFetch.gitcp scre ...
- lr_save_searched_string函数的使用介绍
函数功能:在某一个字符缓冲区中搜索指定的字符串,并将搜到的字符串保存在参数中. 应用场合:可配合LoadRunner的关联功能,灵活获取服务器端返回的数据 举例:客服3.0工作流系统,工单处理每次都从 ...