[转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
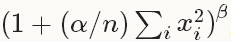 ,得到归一化后的输出
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
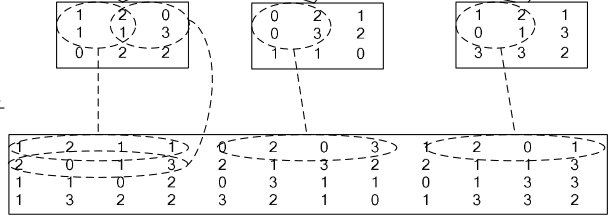
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
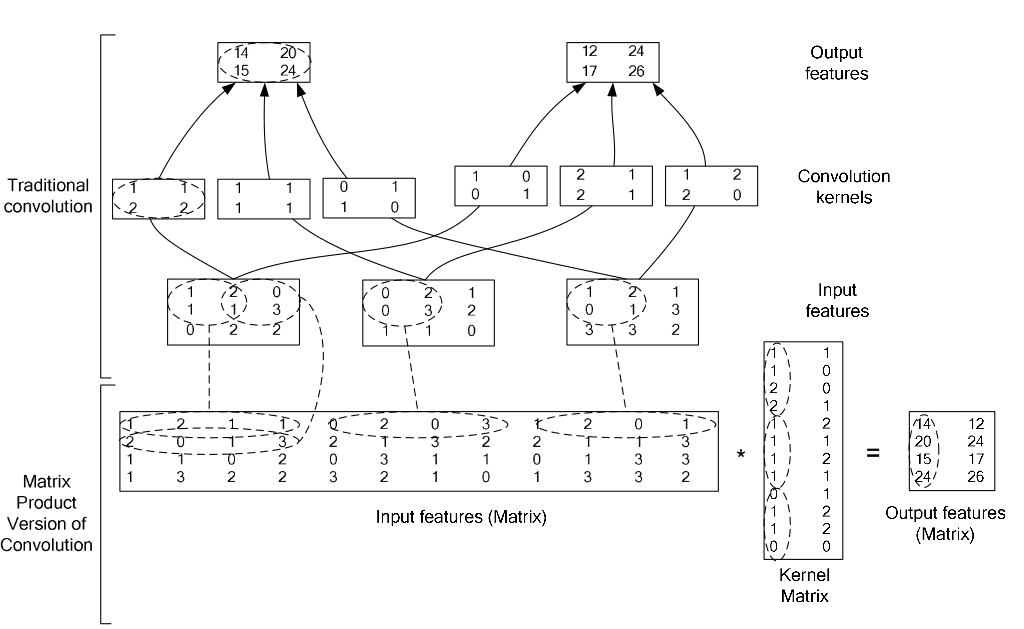
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
原文:http://www.cnblogs.com/denny402/p/5071126.html
[转] caffe视觉层Vision Layers 及参数的更多相关文章
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 【转】Caffe初试(五)视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. ...
- caffe(3) 视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN)局部相应归一化, im2 ...
- caffe学习系列(4):视觉层介绍
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 这里介绍下conv层. layer { name: & ...
- 1、Caffe数据层及参数
要运行Caffe,需要先创建一个模型(model),每个模型由许多个层(layer)组成,每个层又都有自己的参数, 而网络模型和参数配置的文件分别是:caffe.prototxt,caffe.solv ...
- caffe 每层结构
如何在Caffe中配置每一个层的结构 最近刚在电脑上装好Caffe,由于神经网络中有不同的层结构,不同类型的层又有不同的参数,所有就根据Caffe官网的说明文档做了一个简单的总结. 1. Vision ...
- Caffe 激励层(Activation)分析
Caffe_Activation 一般来说,激励层的输入输出尺寸一致,为非线性函数,完成非线性映射,从而能够拟合更为复杂的函数表达式激励层都派生于NeuronLayer: class XXXlayer ...
- Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
随机推荐
- CentOS下安装Python3
目录 CentOS下安装Python3 下载 解压 配置 gcc sudo权限 vim 编译 安装 添加软链接 pip安装出错,找不到SSL 安装virtualenv和virtualenvwrappe ...
- ES6学习笔记(五):Class和Module
Class Class 只是一个语法糖,其功能用es5也能实现,但是比es5更符合类的期待 定义: constructor代表构造方法,而this指向new 生成的实例 定义类方法时,可以不使用fun ...
- 阿里云ECS提示RHSA-2017:3263: curl security update
服务器配置: 原因阿里云安装的CentOS 7.3的curl和libcurl的源不是最新的,会导致安全漏洞出现 方法首先还是要在实例列表远程连接打开终端. 1.更新ca-bundle1.备份: cp ...
- Merkle Tree 概念
Merkle Tree 概念 来源 https://www.cnblogs.com/fengzhiwu/p/5524324.html /*最近在看Ethereum,其中一个重要的概念是Merkle T ...
- 无旋treap板子!
#include <cstdio> #include <cstring> #include <cmath> #include <algorithm> # ...
- PyCharm远程开发配置及一些问题的解决方案
PyCharm远程开发配置 具体请参考:https://www.jianshu.com/p/79df9ac88e96 Tips:必须要安装PyCharm专业版 实践过程中遇到的问题 背景 因项目需要, ...
- 【CF1077F2】Pictures with Kittens 单调队列+dp
题目大意:给定一个长度为 N 的序列,点有点权,从序列中选出恰好 X 个数,并且保证任意连续的 K 个数中均有一个被选中,求选出的点权最大是多少. 题解:此题可以作为 烽火传递+ 来处理,只不过在烽火 ...
- LeetCode 7最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow" ...
- 哈夫曼树;二叉树;二叉排序树(BST)
优先队列:priority_queue<Type, Container, Functional>Type 为数据类型, Container 为保存数据的容器,Functional 为元素比 ...
- gdb调试2—单步执行和跟踪函数
int add_range(int low, int high); int main(int argc, char *argv[]) { int result[100]; result[0] = ad ...