k-近邻算法(KNN)
最近邻算法可以说是最简单的分类算法,其思想是将被预测的项归类为和它最相近的项相同的类。我们通过简单的计算比较即将被预测的项与已有训练集中各项的距离(差距),选择其中差距最小的一项,该项的类别即为我们即将预测的类别。
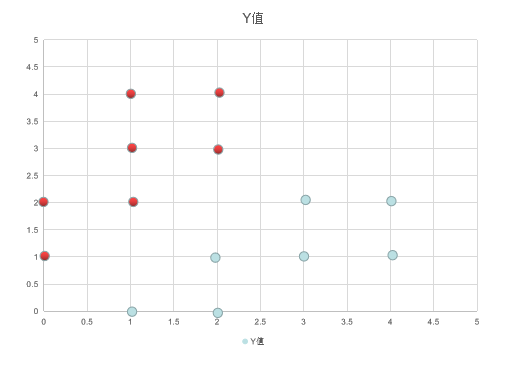
下表为我们即将使用的数据集,所有的点分为红色和蓝色两种,我们随机给出一个坐标位置,然后预测其应该属于的类别。
代码如下:
import math
"""
此python程序用来实现最近邻算法
""" def dot_distance(dot1, dot2):
# 计算两点之间的距离
return math.sqrt(pow(dot1.x - dot2.x, 2) + pow(dot1.y - dot2.y, 2)) def cal_nearest_neighbor(example, goal):
""" :param example: 已有的样例集合
:param goal: 待预测的目标
:return: 距目标最近样例
""" dis, aim = dot_distance(example[0], goal), example[0]
example_len = len(example)
for i in range(1, example_len):
dis1, aim1 = dot_distance(example[i],goal), example[i]
if dis > dis1:
dis, aim = dis1, aim1
return aim
最近邻算法只依据一个数据点来判断其类别,显然如果是一个噪音与即将预测的项目距离很近的话,这就有很大的可能会预测错误。然后就有了最近邻算法的改进--k-近邻算法。
k-近邻算法的思想与最近邻算法类似,不过,它是选择了k个与即将预测的项目最近的训练项目,然后让k个项目投票,以此判断其应该属于的类别。代码如下:
import math def dot_distance(dot1, dot2):
# 计算两点之间的距离
return math.sqrt(pow(dot1.x - dot2.x, 2) + pow(dot1.y - dot2.y, 2)) def predict(example, goal, k):
""" :param example: 训练集
:param goal: 待测点
:param k: 投票的个数,一般为奇数
:return: 最近的k个点
"""
example_len = len(example)
if example_len < k:
k = example_len
k_nearest_dots = []
for i in range(k):
k_nearest_dots.append((example[i], dot_distance(example[i], goal)))
k_nearest_dots.sort(key=lambda item: item[1])
for i in range(k, example_len):
dis = dot_distance(example[i], goal)
if dis < k_nearest_dots[k-1][1]:
k_nearest_dots.pop()
k_nearest_dots.append((example[i],dis))
k_nearest_dots.sort(key=lambda item: item[1]) return k_nearest_dots
k-近邻算法存在的问题是,当某一类的数据较大时,会对该类别的预测造成过大的影响。如一个小圆圈内都是一个类别,但是数据很少,然后一个同心圆中数据很多,这时我们预测一个在小圆圈内的数据,我们倾向于它应该是属于小圆圈同一个类别的,但是因为数据不足的原因,其可能会被预测为大圆圈类别。
k-近邻算法的改进是,为不同的距离确定不同的权重。即为更小的距离,确定一个较大的权重。
以上两部分测试代码如下:
import csv
from NN import nearest_neighbor
from NN import k_nearest_neighbor class Data:
def __init__(self):
self.x = 0
self.y = 0
self.type = None with open("test\\NN\\data.csv","r") as csv_file:
reader = csv.reader(csv_file)
rows = [row for row in reader]
example = []
for item in rows:
data = Data()
data.x = int(item[0])
data.y = int(item[1])
data.type = item[2]
example.append(data)
goal = Data()
goal.x = 0
goal.y = 3
result = nearest_neighbor.cal_nearest_neighbor(example,goal)
print(goal.x, " ", goal.y, " :", result.type) goal.x = 3
goal.y = 0
result = nearest_neighbor.cal_nearest_neighbor(example,goal)
print(goal.x, " ", goal.y, " :", result.type) k_num = 3
preset = k_nearest_neighbor.predict(example,goal,k_num)
red = 0
blue = 0
for item in preset:
if item[0].type == "red":
red += 1
elif item[0].type == "blue":
blue += 1
if red > blue:
print("predict ", goal.x, " ", goal.y, " is red")
else:
print("predict ", goal.x, " ", goal.y, " is blue")
训练集数据,保存为data.csv
0,1,red
0,2,red
1,2,red
1,3,red
1,4,red
2,3,red
2,4,red
1,0,blue
2,0,blue
2,1,blue
3,1,blue
3,2,blue
4,1,blue
4,2,blue
k-近邻算法(KNN)的更多相关文章
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- k近邻算法(knn)的c语言实现
最近在看knn算法,顺便敲敲代码. knn属于数据挖掘的分类算法.基本思想是在距离空间里,如果一个样本的最接近的k个邻居里,绝大多数属于某个类别,则该样本也属于这个类别.俗话叫,"随大流&q ...
- 《机器学习实战》---第二章 k近邻算法 kNN
下面的代码是在python3中运行, # -*- coding: utf-8 -*- """ Created on Tue Jul 3 17:29:27 2018 @au ...
- 最基础的分类算法-k近邻算法 kNN简介及Jupyter基础实现及Python实现
k-Nearest Neighbors简介 对于该图来说,x轴对应的是肿瘤的大小,y轴对应的是时间,蓝色样本表示恶性肿瘤,红色样本表示良性肿瘤,我们先假设k=3,这个k先不考虑怎么得到,先假设这个k是 ...
- 07.k近邻算法kNN
1.将数据分为测试数据和预测数据 2.数据分为data和target,data是矩阵,target是向量 3.将每条data(向量)绘制在坐标系中,就得到了一系列的点 4.根据每条data的targe ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 机器学习(1)——K近邻算法
KNN的函数写法 import numpy as np from math import sqrt from collections import Counter def KNN_classify(k ...
随机推荐
- hdu4073 Lights
题意:找出m个不同的n位2进制数,异或值中前v个为1,其余为0的方案数,答案 % 10567201.. 思路:比赛时第一感觉是用容斥原理做的,然后推呀推,搞了2个小时还是错了..赛后才知道递推才是正解 ...
- django天天生鲜项目
.后台admin管理天天生鲜商品信息 models里 from django.db import modelsfrom tinymce.models import HTMLField #需要pip安装 ...
- cxGrid实现取消过滤和排序后定位到首行(单选和多选)
cxGrid实现取消过滤和排序后定位到首行(单选和多选) 原创 2013年10月06日 18:42:24 2107 DataContoller中的函数FocusedRecordIndex没有反应,Fo ...
- MacOS统计TCP/UDP端口号与对应服务
1.TCP端口 echo "### TCP LISTEN ###" lsof -nP -iTCP -sTCP:LISTEN 2.UDP端口 echo "### UDP L ...
- Centos7 下一键安装JDK和Maven
JDK 1. 使用yum search java|grep jdk 查看jdk版本 2. 选择版本安装 yum install java-1.7.0-openjdk,如果用1.8的,只用改版本号即可. ...
- .NET Core 微服务之grpc 初体验(干货)
Grpc介绍 GitHub: https://github.com/grpc/grpc gRPC是一个高性能.通用的开源RPC框架,其由Google主要面向移动应用开发并基于HTTP/2协议标准而设计 ...
- make编译
Makefile 值得一提的是,在Makefile中的命令,必须要以[Tab]键开始. 什么是makefile?或许很多Winodws的程序员都不知道这个东西,因为那些Windows的IDE都为你做了 ...
- IIS8.0配置网站,错误提示:用户 'IIS APPPOOL\你的网站名称'登录失败
项目在vs2013中能正常运行,配置到服务器(windows2012+IIS8.0),运行提示用户 'IIS APPPOOL\DefaultAppPool' 登录失败. 解决方案: 比如我的网站取名m ...
- 实现输入框不可输入、解决Enable,Disable等不能更新值问题
当在前台JS中更新不可用输入框(TextBox.Enable ="false" or Input box ReadOnly ="True")的值时, 后台可能 ...
- bower 安装后 jade 引用404问题
这个问题困扰我接近2小时,这是我在stackoveflow 上面挖到的 原文地址:http://stackoverflow.com/questions/21821773/configure-node- ...