回归损失函数2 : HUber loss,Log Cosh Loss,以及 Quantile Loss
均方误差(Mean Square Error,MSE)和平均绝对误差(Mean Absolute Error,MAE) 是回归中最常用的两个损失函数,但是其各有优缺点。为了避免MAE和MSE各自的优缺点,在Faster R-CNN和SSD中使用\(\text{Smooth} L_1\)损失函数,当误差在\([-1,1]\) 之间时,\(\text{Smooth} L_1\)损失函数近似于MSE,能够快速的收敛;在其他的区间则近似于MAE,其导数为\(\pm1\),不会对离群值敏感。
本文再介绍几种回归常用的损失函数
- Huber Loss
- Log-Cosh Loss
- Quantile Loss
Huber Loss
Huber损失函数(\(\text{Smooth} L_1\)损失函数是其的一个特例)整合了MAE和MSE各自的优点,并避免其缺点
\[
L_\delta(y,f(x)) = \left \{ \begin{array}{c} \frac{1}{2} (y - f(x))^2 & \mid y - f(x) \mid \leq \delta \\ \delta \mid y-f(x) \mid - \frac{1}{2} \delta ^2 & \text{otherwise}\end{array}\right.
\]
\(\delta\) 是Huber的一个超参数,当真实值和预测值的差值\(\mid y- f(x) \mid \leq \delta\) 时,Huber就是MSE;当差值在\((-\infty,\delta )\)或者 \((\delta,+\infty)\) 时,Huber就是MAE。这样,当误差较大时,使用MAE对离群点不那么敏感;在误差较小时使用MSE,能够快速的收敛;
这里超参数\(\delta\)的值的设定就较为重要,和真实值的差值超过该值的样本为异常值。误差的绝对值小于\(\delta\) 时,使用MSE;当误差大于\(\delta\) 时,使用MAE。
下图给出了不同的\(\delta\) 值,Huber的函数曲线。
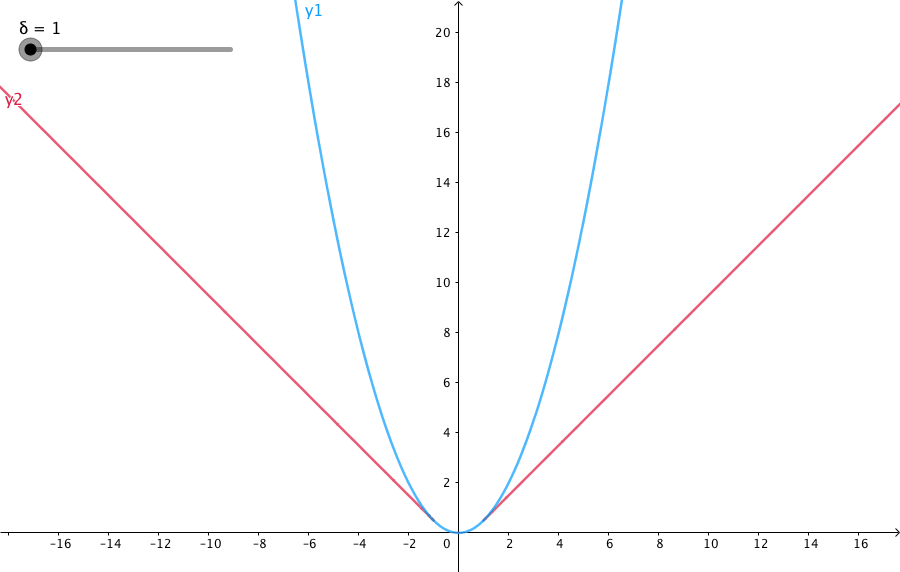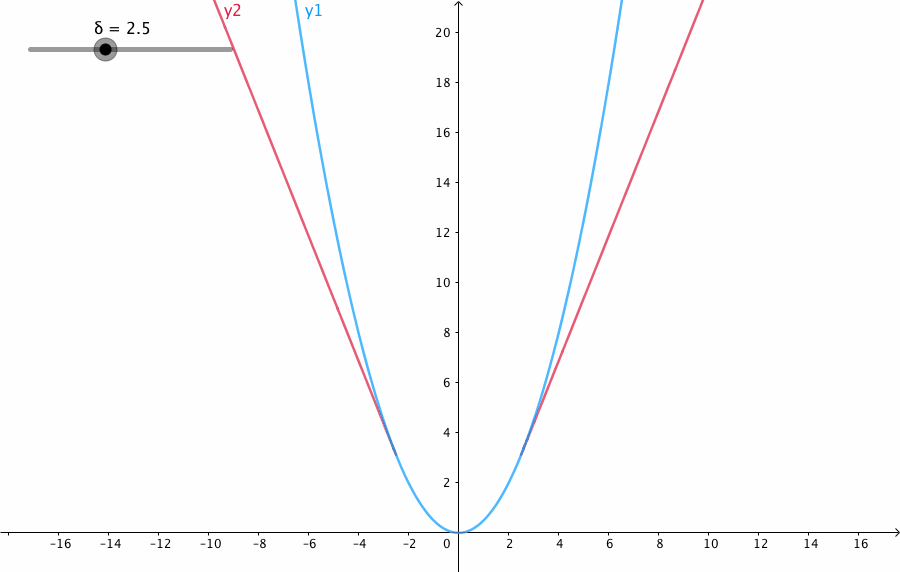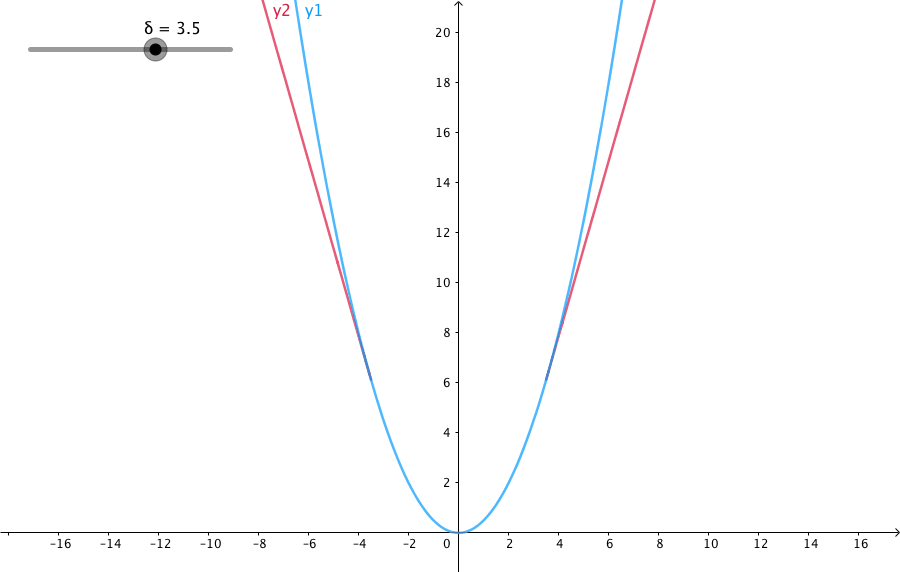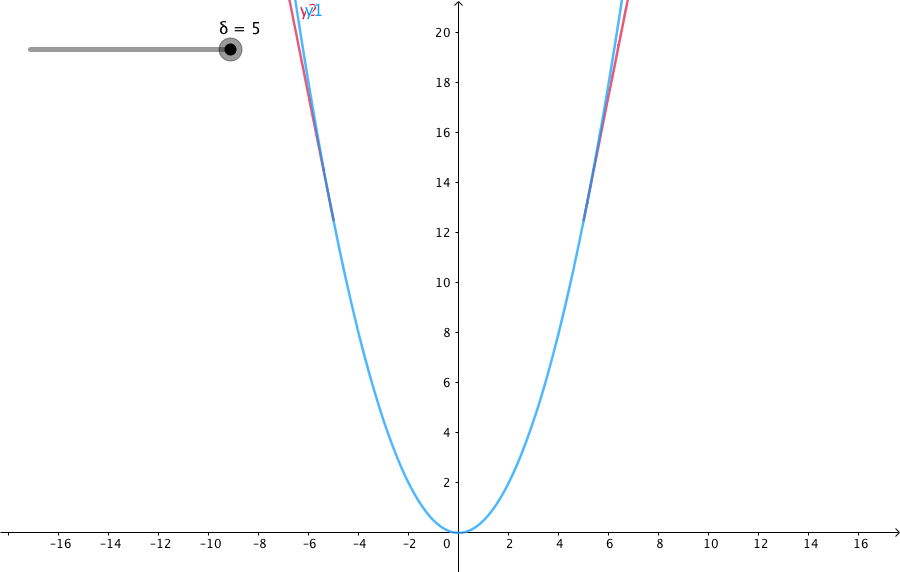
横轴表示真实值和预测值的差值,纵轴为Huber的函数值。可以看出,\(\delta\) 越小其曲线越趋近于MSE;越大,越趋近于MAE。
另外,使用MAE训练神经网络最大的一个问题就是不变的大梯度,这可能导致在使用梯度下降快要结束时,错过了最小点。而对于MSE,梯度会随着损失的减小而减小,使结果更加精确。
在这种情况下,Huber损失就非常有用。它会由于梯度的减小而落在最小值附近。比起MSE,它对异常点更加鲁棒。因此,Huber损失结合了MSE和MAE的优点。但是,Huber损失的问题是我们可能需要不断调整超参数\(\delta\) 。
\(\text{Smooth }L_1\) 损失函数可以看作超参数\(\delta = 1\) 的Huber函数。
Log-Cosh Loss
Log-Cosh是比\(L_2\) 更光滑的损失函数,是误差值的双曲余弦的对数
\[
L(y,f(x)) = \sum_{i=1}^n\log \cosh(y-f(x))
\]
其中,\(y\)为真实值,\(f(x)\) 为预测值。
对于较小的误差$\mid y - f(x) \mid $ ,其近似于MSE,收敛下降较快;对于较大的误差\(\mid y - f(x) \mid\) 其近似等于\(\mid y-f(x) \mid - log(2)\) ,类似于MAE,不会受到离群点的影响。 Log-Cosh具有Huber 损失的所有有点,且不需要设定超参数。
相比于Huber,Log-Cosh求导比较复杂,计算量较大,在深度学习中使用不多。不过,Log-Cosh处处二阶可微,这在一些机器学习模型中,还是很有用的。例如XGBoost,就是采用牛顿法来寻找最优点。而牛顿法就需要求解二阶导数(Hessian)。因此对于诸如XGBoost这类机器学习框架,损失函数的二阶可微是很有必要的。但Log-cosh损失也并非完美,其仍存在某些问题。比如误差很大的话,一阶梯度和Hessian会变成定值,这就导致XGBoost出现缺少分裂点的情况。
Quantile Loss 分位数损失
通常的回归算法是拟合训练数据的期望或者中位数,而使用分位数损失函数可以通过给定不同的分位点,拟合训练数据的不同分位数。 如下图
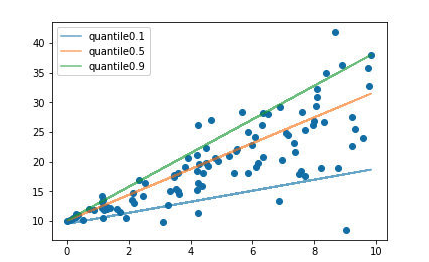
设置不同的分位数可以拟合出不同的直线。
分位数损失函数如下:
\[
L_{quantile} = \frac{1}{N}\sum_{i=1}^N \amalg_{y > f(x)}(1-\gamma)\mid y-f(x)\mid + \amalg_{y < f(x)}\gamma \mid y - f(x) \mid
\]
该函数是一个分段函数,\(\gamma\) 为分位数系数,\(y\)为真实值,\(f(x)\)为预测值。根据预测值和真实值的大小,分两种情况来开考虑。\(y > f(x)\) 为高估,预测值比真实值大;\(y < f(x)\)为低估,预测值比真实值小,使用不同过得系数来控制高估和低估在整个损失值的权重 。
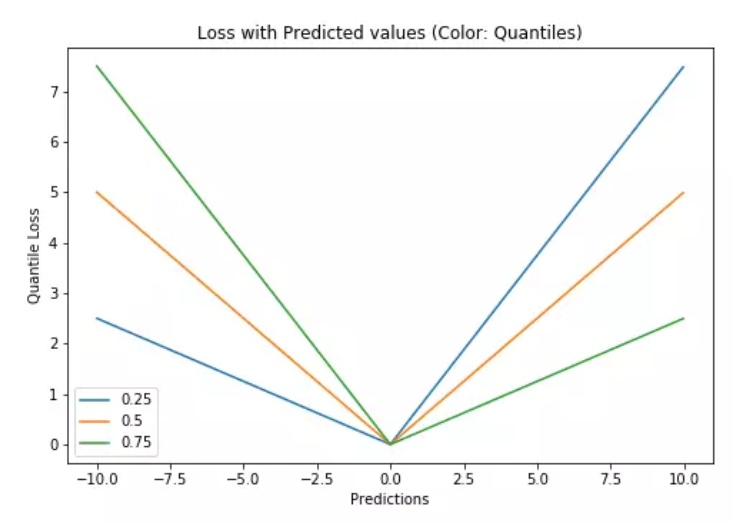
特别的,当\(\gamma = 0.5\) 时,分位数损失退化为平均绝对误差MAE,也可以将MAE看成是分位数损失的一个特例 - 中位数损失。下图是取不同的中位点\([0.25,0.5,0.7]\) 得到不同的分位数损失函数的曲线,也可以看出0.5时就是MAE。
总结
均方误差(Mean Square Error,MSE)和平均绝对误差(Mean Absolute Error,MAE) 可以说是回归损失函数的基础。但是MSE对对离群点(异常值)较敏感,MAE在梯度下降的过程中收敛较慢,就出现各种样的分段损失函数,在loss值较小的区间使用MSE,loss值较大的区间使用MAE。
- Huber Loss ,需要一个超参数\(\delta\) ,来定义离群值。$ \text{smooth } L_1$ 是\(\delta = 1\) 的一种情况。
- Log-Cosh Loss, Log-Cosh是比\(L_2\) 更光滑的损失函数,是误差值的双曲余弦的对数.
- Quantile Loss , 分位数损失,则可以设置不同的分位点,控制高估和低估在loss中占的比重。
回归损失函数2 : HUber loss,Log Cosh Loss,以及 Quantile Loss的更多相关文章
- 回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss
回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss 2019-06-04 20:09:34 clover_my 阅读数 430更多 分类专栏: 阅读笔记 版权声明: ...
- 目标检测——Faster R_CNN使用smooth L1作为bbox的回归损失函数原因
前情提要—— 网上关于目标检测框架——faster r_cnn有太多太好的博文,这是我在组会讲述faster r_cnn这一框架时被人问到的一个点,当时没答上来,于是会下好好百度和搜索一下研究了一下这 ...
- 感知机、logistic回归 损失函数对比探讨
感知机.logistic回归 损失函数对比探讨 感知机 假如数据集是线性可分的,感知机学习的目标是求得一个能够将正负样本完全分开的分隔超平面 \(wx+b=0\) .其学习策略为,定义(经验)损失函数 ...
- logistic回归损失函数(非常重要,深入理解)
2.2 logistic回归损失函数(非常重要,深入理解) 上一节当中,为了能够训练logistic回归模型的参数w和b,需要定义一个成本函数 使用logistic回归训练的成本函数 为了让模型通过学 ...
- L1、L2损失函数、Huber损失函数
L1范数损失函数,也被称为最小绝对值偏差(LAD),最小绝对值误差(LAE) L2范数损失函数,也被称为最小平方误差(LSE) L2损失函数 L1损失函数 不是非常的鲁棒(robust) 鲁棒 稳定解 ...
- 逻辑回归损失函数(cost function)
逻辑回归模型预估的是样本属于某个分类的概率,其损失函数(Cost Function)可以像线型回归那样,以均方差来表示:也可以用对数.概率等方法.损失函数本质上是衡量”模型预估值“到“实际值”的距离, ...
- keras 分类回归 损失函数与评价指标
1.目标函数 (1)mean_squared_error / mse 均方误差,常用的目标函数,公式为((y_pred-y_true)**2).mean()(2)mean_absolute_error ...
- 2.2 logistic回归损失函数(非常重要,深入理解)
上一节当中,为了能够训练logistic回归模型的参数w和b,需要定义一个成本函数 使用logistic回归训练的成本函数 为了让模型通过学习来调整参数,要给出一个含有m和训练样本的训练集 很自然的, ...
- Huber Loss
Huber Loss 是一个用于回归问题的带参损失函数, 优点是能增强平方误差损失函数(MSE, mean square error)对离群点的鲁棒性. 当预测偏差小于 δ 时,它采用平方误差, 当预 ...
随机推荐
- C语言1博客作业01
1 你对软件工程专业或者计算机科学与技术专业了解是怎样? 主修大数据技术导论.数据采集与处理实践(Python).Web前/后端开发.统计与数据分析.机器学习.高级数据库系统.数据可视化.云计算技术. ...
- Arduino驱动ILI9341彩屏(一)——颜色问题
最近在淘宝的店铺上淘到了一块ILI9341的彩色液晶屏,打算研究一下如何使用. 淘宝店铺购买屏幕之后有附源代码可供下载,代码质量惨不忍睹,各种缩进不规范就不说了,先拿来试一下吧. 这是淘宝店铺代码的核 ...
- Andorid开发中遇到的问题
最近开始学习开发Android App,找了本教程,学了一些基本知识后,就开始着手做一个例子. 我始终觉得在做中学,可能会稍微快一点.很快,一个具有初步功能的App被我撸出来了. 在模拟器上运行,我发 ...
- SoapUI使用JDBC请求连接数据库及断言的使用
SoapUI提供了用来配置JDBC数据库连接的选项,因此我们可以在测试中使用JDBC数据源.JDBC数据接收器和JDBC请求步骤. 为了能够配置数据连接,就必须有驱动程序和连接串,SoapUI中已经提 ...
- error: Unexpected console statement (no-console)
使用console.log 报错??这个错误是Vuejs - 使用ESLint检查代码而产生的 解决办法: 1.不处理,虽然有恼人的提示,但是实际上能使用console.log的 2.关掉ESLint ...
- web服务,ftp服务以及共享实现
在开始服务前一定要确保可以ping通外网,在虚拟机联网但ping 不通外网下 确认vim /etc/sysconfig/network-scripts/ifcfg-ens33 (nmcli conne ...
- TensorBoard:可视化学习
数据序列化 TensorBoard 通过读取 TensorFlow 的事件文件来运行.TensorFlow 的事件文件包括了你会在 TensorFlow 运行中涉及到的主要数据.下面是 TensorB ...
- redis的主从复制,以及使用sentinel自动处理主机宕机问题,集群
以下部分想看懂得有一定的redis基础,且步骤是连贯的,错一步都不行.redis运行多个实例,不懂得自行百度. 1. redis主从同步 原理: 从服务器向主服务器发送 SYNC 命令. 接到 SYN ...
- Flask入门学习——配置参数的管理方式
一般来说有这么几种方式: 直接操作config的字典对象 app.config["DEBUG"] = True 使用配置文件加载,直接传入文件名 app.config.from_p ...
- P1035 级数求和
题目描述 已知:S_n= 1+1/2+1/3+…+1/nSn=1+1/2+1/3+…+1/n.显然对于任意一个整数KK,当nn足够大的时候,S_nSn大于KK. 现给出一个整数KK(1 \le k ...