TensorFlow从0到1之TensorFlow逻辑回归处理MNIST数据集(17)
本节基于回归学习对 MNIST 数据集进行处理,但将添加一些 TensorBoard 总结以便更好地理解 MNIST 数据集。
MNIST由https://www.tensorflow.org/get_started/mnist/beginners提供。
大部分人已经对 MNIST 数据集很熟悉了,它是机器学习的基础,包含手写数字的图像及其标签来说明它是哪个数字。
对于逻辑回归,对输出 y 使用独热(one-hot)编码。因此,有 10 位表示输出,每位的值为 1 或 0,独热意味着对于每个图片的标签 y,10 位中仅有一位的值为 1,其余的为 0。
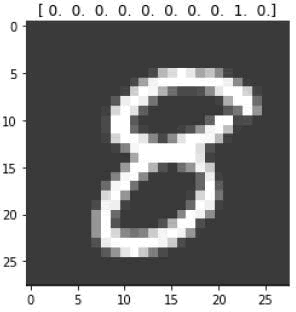
因此,对于手写数字 8 的图像,其编码值为 [0000000010]:
具体做法
- 导入所需的模块:
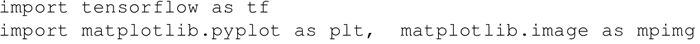
- 可以从模块 input_data 给出的 TensorFlow 示例中获取 MNIST 的输入数据。该 one_hot 标志设置为真,以使用标签的 one_hot 编码。这产生了两个张量,大小为 [55000,784] 的 mnist.train.images 和大小为 [55000,10] 的 mnist.train.labels。mnist.train.images 的每项都是一个范围介于 0 到 1 的像素强度:

- 在 TensorFlow 图中为训练数据集的输入 x 和标签 y 创建占位符:

- 创建学习变量、权重和偏置:
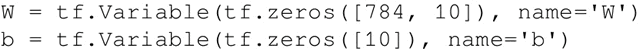
- 创建逻辑回归模型。TensorFlow OP 给出了 name_scope("wx_b"):
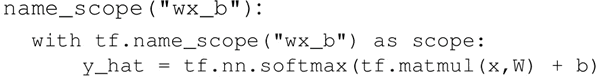
- 训练时添加 summary 操作来收集数据。使用直方图以便看到权重和偏置随时间相对于彼此值的变化关系。可以通过 TensorBoard Histogtam 选项卡看到:
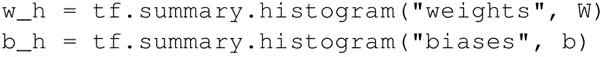
- 定义交叉熵(cross-entropy)和损失(loss)函数,并添加 name scope 和 summary 以实现更好的可视化。使用 scalar summary 来获得随时间变化的损失函数。scalar summary 在 Events 选项卡下可见:

- 采用 TensorFlow GradientDescentOptimizer,学习率为 0.01。为了更好地可视化,定义一个 name_scope:

- 为变量进行初始化:

- 组合所有的 summary 操作:
- 现在,可以定义会话并将所有的 summary 存储在定义的文件夹中:

- 经过 30 个周期,准确率达到了 86.5%;经过 50 个周期,准确率达到了 89.36%;经过 100 个周期,准确率提高到了 90.91 %。
解读分析
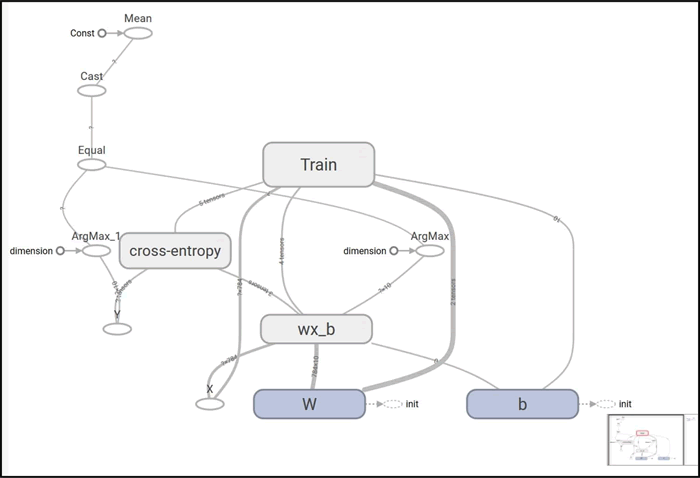
这里使用张量 tensorboard--logdir=garphs 运行 TensorBoard。在浏览器中,导航到网址 localhost:6006 查看 TensorBoard。该模型图如下:
在 Histogram 选项卡下,可以看到权重(weights)和偏置(biases)的直方图:
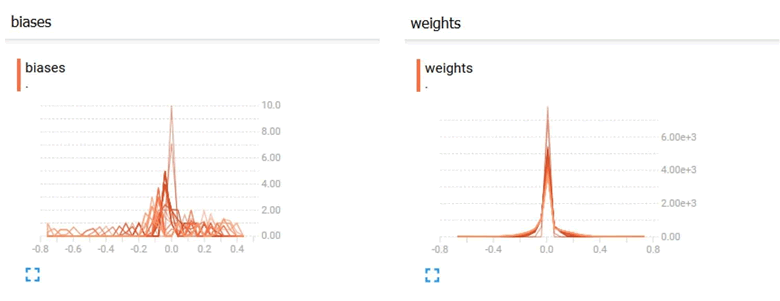
权重和偏置的分布如下:
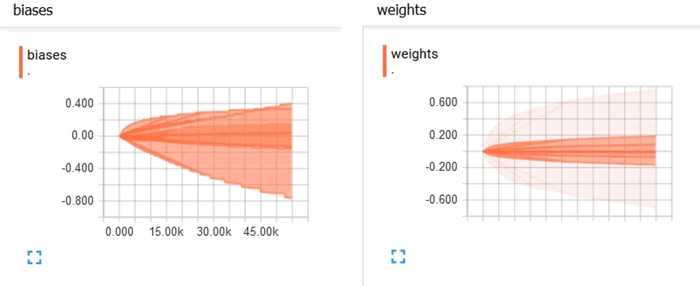
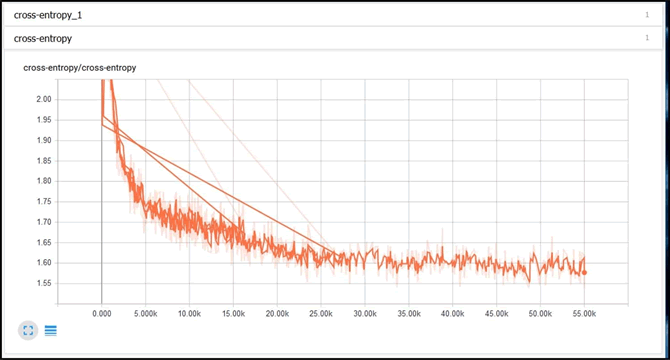
可以看到,随着时间的推移,偏置和权重都发生了变化。在该示例中,根据 TensorBoard 中的分布可知偏置变化的范围更大。在 Events 选项卡下,可以看到 scalar summary,即本示例中的交叉熵。下图显示交叉熵损失随时间不断减少:
TensorFlow从0到1之TensorFlow逻辑回归处理MNIST数据集(17)的更多相关文章
- TensorFlow从0到1之TensorFlow实现反向传播算法(21)
反向传播(BPN)算法是神经网络中研究最多.使用最多的算法之一,它用于将输出层中的误差传播到隐藏层的神经元,然后用于更新权重. 学习 BPN 算法可以分成以下两个过程: 正向传播:输入被馈送到网络,信 ...
- TensorFlow从0到1之TensorFlow实现单层感知机(20)
简单感知机是一个单层神经网络.它使用阈值激活函数,正如 Marvin Minsky 在论文中所证明的,它只能解决线性可分的问题.虽然这限制了单层感知机只能应用于线性可分问题,但它具有学习能力已经很好了 ...
- TensorFlow从0到1之TensorFlow优化器(13)
高中数学学过,函数在一阶导数为零的地方达到其最大值和最小值.梯度下降算法基于相同的原理,即调整系数(权重和偏置)使损失函数的梯度下降. 在回归中,使用梯度下降来优化损失函数并获得系数.本节将介绍如何使 ...
- TensorFlow从0到1之TensorFlow损失函数(12)
正如前面所讨论的,在回归中定义了损失函数或目标函数,其目的是找到使损失最小化的系数.本节将介绍如何在 TensorFlow 中定义损失函数,并根据问题选择合适的损失函数. 声明一个损失函数需要将系数定 ...
- TensorFlow从0到1之TensorFlow Keras及其用法(25)
Keras 是与 TensorFlow 一起使用的更高级别的作为后端的 API.添加层就像添加一行代码一样简单.在模型架构之后,使用一行代码,你可以编译和拟合模型.之后,它可以用于预测.变量声明.占位 ...
- TensorFlow从0到1之TensorFlow多层感知机函数逼近过程(23)
Hornik 等人的工作(http://www.cs.cmu.edu/~bhiksha/courses/deeplearning/Fall.2016/notes/Sonia_Hornik.pdf)证明 ...
- TensorFlow从0到1之TensorFlow常用激活函数(19)
每个神经元都必须有激活函数.它们为神经元提供了模拟复杂非线性数据集所必需的非线性特性.该函数取所有输入的加权和,进而生成一个输出信号.你可以把它看作输入和输出之间的转换.使用适当的激活函数,可以将输出 ...
- TensorFlow从0到1之TensorFlow csv文件读取数据(14)
大多数人了解 Pandas 及其在处理大数据文件方面的实用性.TensorFlow 提供了读取这种文件的方法. 前面章节中,介绍了如何在 TensorFlow 中读取文件,本节将重点介绍如何从 CSV ...
- TensorFlow从0到1之TensorFlow超参数及其调整(24)
正如你目前所看到的,神经网络的性能非常依赖超参数.因此,了解这些参数如何影响网络变得至关重要. 常见的超参数是学习率.正则化器.正则化系数.隐藏层的维数.初始权重值,甚至选择什么样的优化器优化权重和偏 ...
随机推荐
- 十、理解JavaBean
1. 理解Bean 1.JavaBean本身就是一个类,属于Java的面向对象编程. 2.在JSP中如果要应用JSP提供的Javabean的标签来操作简单类的话,则此类必须满足如下的开发要求: (1) ...
- IDEA提高开发效率的7个插件
IDEA提高开发效率的7个插件 1. 多行编辑 先来体验一下从xml文件拷贝字段新建实体对象 一般我们为了新建多表连接后映射的 ResultMap ,耗费不少时间,那么我们就来试一试这个多行编辑 表字 ...
- pyqt5_实例:修改xml文件中节点值
需求: 将类似如下xml文件的externalid节点值修改成不重复的值 实现该功能的代码Func.py: #coding=utf-8 ''' Created on 2019年10月15日 @auth ...
- Java效率工具Lombok使用与原理
Java效率工具Lombok使用与原理 我个人觉得 Lombok是一个优化Java代码以及提升开发效率不错的工具.Lombok 的Github地址为:https://github.com/rzwits ...
- php实用正则
1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ 2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z ...
- oracle计算两日期相差多少秒,分钟,小时,天,周,月,年
--计算两个时间差相差多少秒select ceil((sysdate-t.transdate)* 24 * 60 * 60),t.transdate,sysdate from esc_trans_lo ...
- 「持续集成实践系列」Jenkins 2.x 搭建CI需要掌握的硬核要点
1. 前言 随着互联网软件行业快速发展,为了抢占市场先机,企业不得不持续提高软件的交付效率.特别是现在国内越来越多企业已经在逐步引入DevOps研发模式的变迁,在这些背景催促之下,对于企业研发团队所需 ...
- Hive 集成 Hudi 实践(含代码)| 可能是全网最详细的数据湖系列
公众号后台越来越多人问关于数据湖相关的内容,看来大家对新技术还是很感兴趣的.关于数据湖的资料网络上还是比较少的,特别是实践系列,对于新技术来说,基础的入门文档还是很有必要的,所以这一篇希望能够帮助到想 ...
- 8.Hash集合类型操作使用
数据类型Hash (1)介绍 hash数据类型存储的数据与mysql数据库中存储的一条记录极为相似 Redis本身就类似于Hash的存储结构,分为key-value键值对,实际上它的Hash数据就好像 ...
- static关键字修饰属性
static 静态的,可以修饰属性,方法,代码块(或初始化块) , 内部内 非static修饰的属性(实例变量):各个对象各自拥有一套各自的副本 static修饰属性(l类变量): 1.由类创建的所有 ...