基于物品的协同过滤ItemCF的mapreduce实现
文章的UML图比较好看.....
原文链接:www.cnblogs.com/anny-1980/articles/3519555.html
基于物品的协同过滤ItemCF
数据集字段:
1. User_id: 用户ID
2. Item_id: 物品ID
3. preference:用户对该物品的评分
算法的思想:
1. 建立物品的同现矩阵A,即统计两两物品同时出现的次数
数据格式:Item_id1:Item_id2 次数
2. 建立用户对物品的评分矩阵B,即每一个用户对某一物品的评分
数据格式:Item_id user_id:preference
3. 推荐结果=物品的同现矩阵A * 用户对物品的评分矩阵B
数据格式:user_id item_id,推荐分值
4. 过滤用户已评分的物品项
5.对推荐结果按推荐分值从高到低排序
原始数据:
|
1,101,5.0 1,102,3.0 1,103,2.5 2,101,2.0 2,102,2.5 2,103,5.0 2,104,2.0 3,101,2.0 3,104,4.0 3,105,4.5 3,107,5.0 4,101,5.0 4,103,3.0 4,104,4.5 4,106,4.0 5,101,4.0 5,102,3.0 5,103,2.0 5,104,4.0 5,105,3.5 5,106,4.0 6,102,4.0 6,103,2.0 6,105,3.5 6,107,4.0 |
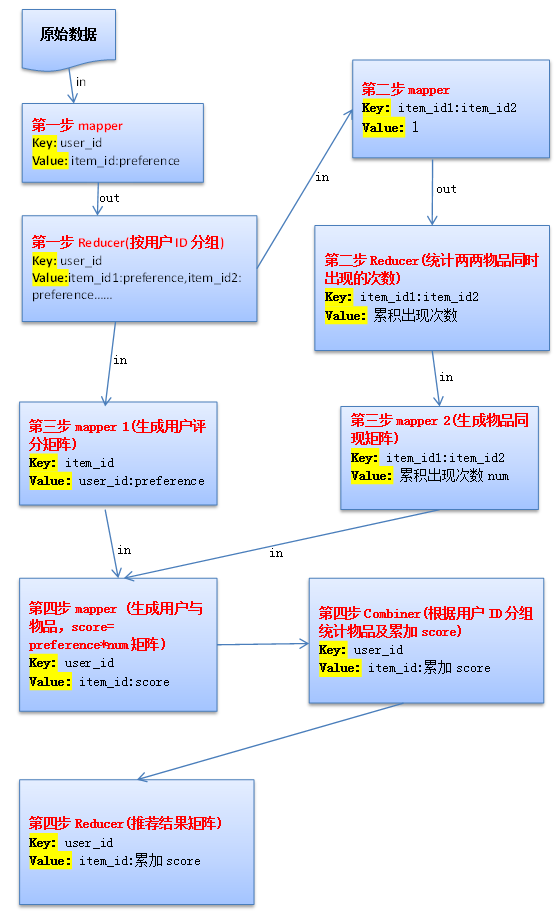
Hadoop MapReduce程序分为四步:
第一步: 读取原始数据,按用户ID分组,输出文件数据格式为
|
1 103:2.5,101:5.0,102:3.0 2 101:2.0,102:2.5,103:5.0,104:2.0 3 107:5.0,101:2.0,104:4.0,105:4.5 4 103:3.0,106:4.0,104:4.5,101:5.0 5 101:4.0,102:3.0,103:2.0,104:4.0,105:3.5,106:4.0 6 102:4.0,103:2.0,105:3.5,107:4.0 |
第二步:统计两两物品同时出现的次数,输出文件数据格式为
|
101:101 5 101:102 3 101:103 4 101:104 4 101:105 2 101:106 2 101:107 1 102:101 3 102:102 4 102:103 4 102:104 2 102:105 2 102:106 1 102:107 1 103:101 4 103:102 4 103:103 5 103:104 3 103:105 2 103:106 2 103:107 1 104:101 4 104:102 2 104:103 3 104:104 4 104:105 2 104:106 2 104:107 1 105:101 2 105:102 2 105:103 2 105:104 2 105:105 3 105:106 1 105:107 2 106:101 2 106:102 1 106:103 2 106:104 2 106:105 1 106:106 2 107:101 1 107:102 1 107:103 1 107:104 1 107:105 2 107:107 2 |
第三步:生成用户评分矩阵和物品同现矩阵
第一个mapper结果为用户评分矩阵,结果如下:
|
101 2:2.0 101 5:4.0 101 4:5.0 101 3:2.0 101 1:5.0 102 2:2.5 102 1:3.0 102 6:4.0 102 5:3.0 103 6:2.0 103 5:2.0 103 1:2.5 103 4:3.0 103 2:5.0 104 5:4.0 104 2:2.0 104 3:4.0 104 4:4.5 105 5:3.5 105 3:4.5 105 6:3.5 106 4:4.0 106 5:4.0 107 3:5.0 107 6:4.0 |
第二个mapper生成物品同现矩阵,结果如下:
|
101:101 5 101:102 3 101:103 4 101:104 4 101:105 2 101:106 2 101:107 1 102:101 3 102:102 4 102:103 4 102:104 2 102:105 2 102:106 1 102:107 1 103:101 4 103:102 4 103:103 5 103:104 3 103:105 2 103:106 2 103:107 1 104:101 4 104:102 2 104:103 3 104:104 4 104:105 2 104:106 2 104:107 1 105:101 2 105:102 2 105:103 2 105:104 2 105:105 3 105:106 1 105:107 2 106:101 2 106:102 1 106:103 2 106:104 2 106:105 1 106:106 2 107:101 1 107:102 1 107:103 1 107:104 1 107:105 2 107:107 2 |
第四步:做矩阵乘法,推荐结果=物品的同现矩阵A * 用户对物品的评分矩阵B
结果如下:
|
1 107,10.5 1 106,18.0 1 105,21.0 1 104,33.5 1 103,44.5 1 102,37.0 1 101,44.0 2 107,11.5 2 106,20.5 2 105,23.0 2 104,36.0 2 103,49.0 2 102,40.0 2 101,45.5 3 107,25.0 3 106,16.5 3 105,35.5 3 104,38.0 3 103,34.0 3 102,28.0 3 101,40.0 4 107,12.5 4 106,33.0 4 105,29.0 4 104,55.0 4 103,56.5 4 102,40.0 4 101,63.0 5 107,20.0 5 106,34.5 5 105,40.5 5 104,59.0 5 103,65.0 5 102,51.0 5 101,68.0 6 107,21.0 6 106,11.5 6 105,30.5 6 104,25.0 6 103,37.0 6 102,35.0 6 101,31.0 |
基于物品的协同过滤ItemCF的mapreduce实现的更多相关文章
- 转】Mahout分步式程序开发 基于物品的协同过滤ItemCF
原博文出自于: http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ 感谢! Posted: Oct 14, 2013 Tags: Hadoopite ...
- Mahout分步式程序开发 基于物品的协同过滤ItemCF
http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- 基于物品的协同过滤item-CF 之电影推荐 python
推荐算法有基于协同的Collaboration Filtering:包括 user Based和item Based:基于内容 : Content Based 协同过滤包括基于物品的协同过滤和基于用户 ...
- 推荐召回--基于物品的协同过滤:ItemCF
目录 1. 前言 2. 原理&计算&改进 3. 总结 1. 前言 说完基于用户的协同过滤后,趁热打铁,我们来说说基于物品的协同过滤:"看了又看","买了又 ...
- 基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法.ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通 ...
- ItemCF_基于物品的协同过滤_MapReduceJava代码实现思路
ItemCF_基于物品的协同过滤 1. 概念 2. 原理 如何给用户推荐? 给用户推荐他没有买过的物品--103 3. java代码实现思路 数据集: 第一步:构建物品的同现矩阵 第 ...
- ItemCF_基于物品的协同过滤
ItemCF_基于物品的协同过滤 1. 概念 2. 原理 如何给用户推荐? 给用户推荐他没有买过的物品--103 3. java代码实现思路 数据集: 第一步:构建物品的同现矩阵 第 ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
随机推荐
- Selenium3+python自动化 -JS处理滚动条
selenium并不是万能的,有时候页面上操作无法实现的,这时候就需要借助JS来完成了. 常见场景: 当页面上的元素超过一屏后,想操作屏幕下方的元素,是不能直接定位到,会报元素不可见的. 这时候需要借 ...
- 【剑指Offer】56、删除链表中重复的结点
题目描述: 在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针. 例如,链表1->2->3->3->4->4-> ...
- POJ 2229 Sumsets(找规律,预处理)
题目 参考了别人找的规律再理解 /* 8=1+1+1+1+1+1+1+1+1 1 8=1+1+1+1+1+1+1+2 2 3 8=1+1+1+1+2+2 8=1+1+1+1+4 4 5 8=1+1+2 ...
- swift-正则验证手机号码
// 手机号验证正则表达式 func validateMobile(phoneNum:String)-> Bool { // 手机号以 13 14 15 18 开头 八个 \d 数字字符 let ...
- Git 基础教程 之 Git 安装 (windows)
一,安装Git,访问下面网址进行下载 https://www.git-scm.com/download/ 或者 https://pan.baidu.com/s/19imFBVHA2Yibmw1dyza ...
- 《你又怎么了我错了行了吧》第八次团队作业:Alpha冲刺
项目 内容 这个作业属于哪个课程 软件工程 这个作业的要求在哪里 实验十二 团队作业8 团队名称 你又怎么了我错了行了吧 作业学习目标 (1)掌握软件测试基础技术 (2)学习迭代式增量软件开发过程,完 ...
- 解决ICS40上设置APN无权限问题
在ICS40以前的版本中,如果程序需要设置APN,只需要在AndroidManifest文件中声明<uses-permission android:name="android.perm ...
- 【hihocoder 1297】数论四·扩展欧几里德
[题目链接]:http://hihocoder.com/problemset/problem/1297 [题意] [题解] 问题可以转化为数学问题 即(s1+v1*t)%m == (s2+v2*t)% ...
- 转载 - 跳跃的舞者,舞蹈链(Dancing Links)算法——求解精确覆盖问题
出处:http://www.cnblogs.com/grenet/p/3145800.html 精确覆盖问题的定义:给定一个由0-1组成的矩阵,是否能找到一个行的集合,使得集合中每一列都恰好包含一个1 ...
- 0804关于mysql 索引自动优化机制: 索引选择性(Cardinality:索引基数)
转自http://blog.csdn.net/zheng0518/article/details/50561761 1.两个同样结构的语句一个没有用到索引的问题: 查1到20号的就不用索引,查1到5号 ...