RPN FPN ROIPooling
RPN(Region Proposal Network)介绍--->
特点从backbone 生成的Feture Map中 用一个 3x3 的Conv卷积核 遍历FeatureMap的每个点然后 根据每个点的感受野,回到最初始的图像层,感受野的中心点就是锚框中心点,然后在中心点生成3种不同大小不同长宽比的锚框,然后根据卷积的结果对生成的锚框进行初步筛选 进行2分类,判断它是否为 网络所需要的特征图 (前景), 随后将分类出来的锚框 作为预选框 送到ROIPooling层, ROIPooling的作用是加速2Stage的推理和训练速度,由于生成的预选框的大小形状都不同 如果对每种形状的FeatureMap都进行推理那么,该处的耗时就为原来的9倍。进行ROIPooling就是不管原来的FeaturenMap是怎样的只对他按比例进行MaxPooling的操作,然后得到相同尺寸的FeatureMap进行分类任务的输入
生成anchor --->对anchor进行二分类--->边框回归--->生成最终的Proposal
生成anchor box
anchor可以翻译为锚,这个anchor指的是输入图像上的点,是生成候选框的基础,有了anchor后就可以为每个anchor生成不同大小和长宽比的box,用这些box来覆盖输入图片中要检测的物体(当然,会生成很多很多的box, 在图片上密密麻麻的,需要后续的操作进行筛选)。筛选过后剩下的就是最终的Proposal。Proposal会给ROIPooling然后进行分类和回归。
生成anchor box分为两步:第一先从Feature map的点对应回输入图像感受野的中心点;第二以该点为中心点创建不同面积和长宽比的box,这个也是输入图像上的box。
生成anchor box
有了anchor点后就可以为每个点生成anchor box了,Faster R-CNN中设置了三种面积的box,每一个面积又有三种长宽比,也就是每一个点会有9个anchor box。
分类和边框回归
在第一步生成了很多很多的anchor box,后面就是要对这些anchor box进行分类和边框回归的操作。
分类操作就是上图中上面的那个分支,首先通过一个1x1的卷积,将维度降为18(因为是9个框,每个框进行二分类),通过softmax进行二分类(框中有没有目标,也就是前景和背景),来生成后面的正负样本。
边框回归的目的是使anchor box更接近ground truth。首先也会通过一个1x1的卷积,维度降为36(和之前的类似每个框四个值来确定)。
生成Proposal
有了前面生成的anchor box后下一步就是利用各种方法剔除我们不需要的那些box,主要分一下几步:
第一步:先将anchor box利用feat_stride和im_info(这个里面保存了原始图像的大小,注意这个不是网络输入的图像,是原始图像)将box映射会原始图像,将严重超出边界的box剔除;
第二步:按照上面说的二分类的分支得到的score得分进行排序,提取前2000个;
第三步:对得到的2000个box执行NMS(非极大值抑制);
第四步:将得到的结果再进行排序,取前300个作为最终的Proposal,给后面进行分类和回归。
Single Shot MultiBox Detector(SSD)
Single shot指明了SSD算法属于one-stage方法,MultiBox指明了SSD是多框预测。在上一篇文章中我们已经讲了Yolo算法,SSD算法在准确度和速度(除了SSD512)上都比Yolo要好很多。图2给出了不同算法的基本框架图,对于Faster R-CNN,其先通过CNN得到候选框,然后再进行分类与回归,而Yolo与SSD可以一步到位完成检测。相比Yolo,SSD采用CNN来直接进行检测,而不是像Yolo那样在全连接层之后做检测。其实采用卷积直接做检测只是SSD相比Yolo的其中一个不同点,另外还有两个重要的改变,一是SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;二是SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)。Yolo算法缺点是难以检测小目标,而且定位不准,但是这几点重要改进使得SSD在一定程度上克服这些缺点。下面我们详细讲解SDD算法的原理,并最后给出如何用TensorFlow实现SSD算法。
FPN(金字塔网络)详解--->为了解决对不同尺度的物体检测问题而提出的方法。
1.在图像金字塔提特征 Featurized Image Pyramid
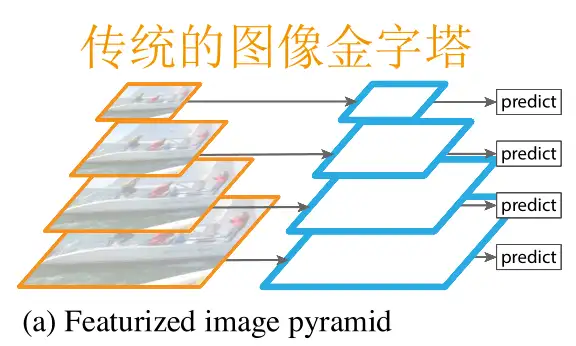
十分想当然的思路,既然你图片太小我预测不出来,那就把图片缩放到不同的大小,分别预测。
这是最直观的办法,自然也是最蠢的办法。
想象一下它的过程:
把一张图片提取特征预测→放大→提取特征预测→放大→提取特征预测……
这个过程中,每个特征提取/预测都是独立进行的!即使同一张图片的不同分辨率,模型之间也很难共享它们中间提取的特征。这让模型预测的过程费时费力,比如本来一个图片预测需要五秒,一个五级的图像金字塔耗时绝对不会少于25秒。
这还只是预测,训练模型更加耗时,因此出于这种考虑,图像金字塔通常只能在预测时使用。
这又导致了新的问题,即此时模型本质上只是为了某种分辨率训练的,只是强行被拿去检测别的分辨率,这样的效果自然不可能好。
2. 原始CNN Naïve CNN
现在我们都知道,若以表征学习(representation learning)的角度思考CNN,那么CNN实际上是有层次地学习图片的特征,即深度越深,则特征的语义越高级(从线到面,再到物体特征)
由于后续存在池化和降采样,浅层网络的特征图可以保留更多的分辨率,但是特征语义较为低级。
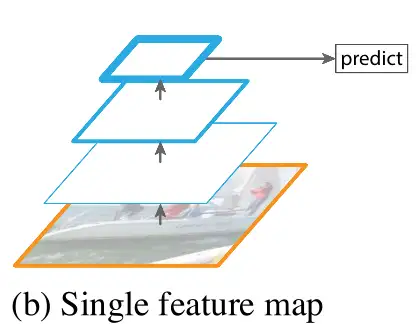
因此,CNN只能寄希望于小物体的特征够在最后一层“存活下来”,但由于分辨率的损失,这显然是不切实际的。
但CNN这种层级计算特征如此高效,fast(er) R-CNN也是靠这种层级结构达到加速效果的。因为此时至少特征计算是“共享的”,不用像图像金字塔那样傻乎乎一个个算。
那么问题来了,层级计算的时候,有辣么多分辨率的特征,那我们何不全用上?
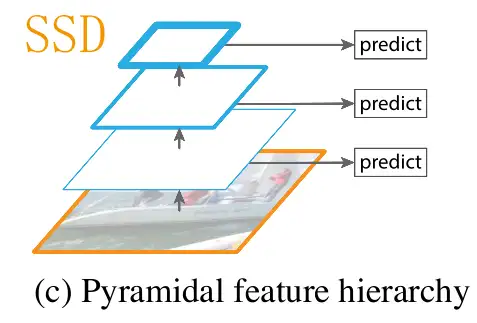
3. 金字塔型特征层级 Pyramidal feature hierarchy
实际上SSD就是“把不同分辨率特征”全用上的先驱之一。SSD会在不同分辨率的特征上直接预测,那么不就大物体小物体都能预测到了吗?
这想法很不错,但还没有那么好。SSD这么做有两个问题:
- 底层特征语义不够
- 最高分辨率并不高
正如之前分析的,实际上,底层特征的语义较低,携带信息的“有效性”略少,导致预测结果不佳。
SSD缓解上述问题的方法是,太底层的语义干脆不用不就好了?
所以,你以为SSD是这样的:
卖家秀
实际上是这样的:
买家秀
实际上,太浅层的特征SSD也根本没用上。这也不能怪SSD,因为技术的发展永远是循序渐进的,它能意识到可以在不同分辨率特征上检测已是不易。
分析到这,一个很自然的想法就出现了“我们是否可以结合深浅特征,兼顾分辨率与特征语义?”原来大家都会说不可能,直到一个叫ResNet的模型告诉我们什么叫跳接。
现在,正文终于可以开始了
二、特征金字塔网络
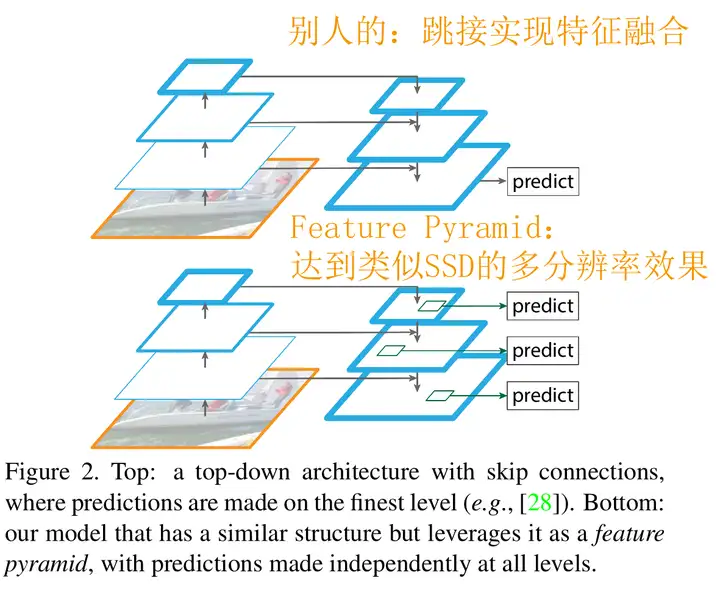
FPN是一种自顶向下路径和横向连接将低分辨率、语义强的特性与高分辨率、语义弱的特性结合起来的体系结构。
FPN通过讲浅层的特征跳接到深层的特征,兼顾了分辨率与特征语义。但实际上,这也不是FPN的首创,在对分辨率要求更高的语义分割问题中早有涉猎(如医学图像常用的U-Net)。
但FPN的独到之处在于将深/潜层特征融合与多分辨率预测结合了起来。
有了初步认识,接下来就是模型的细节了。
三、模型细节 Details
从图上可以看出,FPN可以分为三部分:
- 自底向上的部分
- 自顶向下的部分
- 连接两部分的跳接
注意,实际上这个网络掰直了更像一个漏斗,可以理解为这里的底=高分辨率,顶=低分辨率。
自底向上
前馈Backbone的一部分,每一级往上用step=2的降采样。
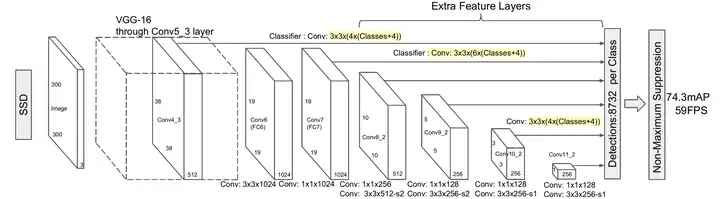
输出size相同的网络部分叫一级(Stage),举个例子:下图是fasterRCNN的网络结构,左列ResNet用每级最后一个Residual Block的输出,记为{C1,C2,C3,C4,C5}。
FPN用2~5级参与预测(因为第一级的语义还是太低了),而{C1,C2,C3,C4,C5}这几级等效于在图片上以{4,8,16,32}为步长提取特征。
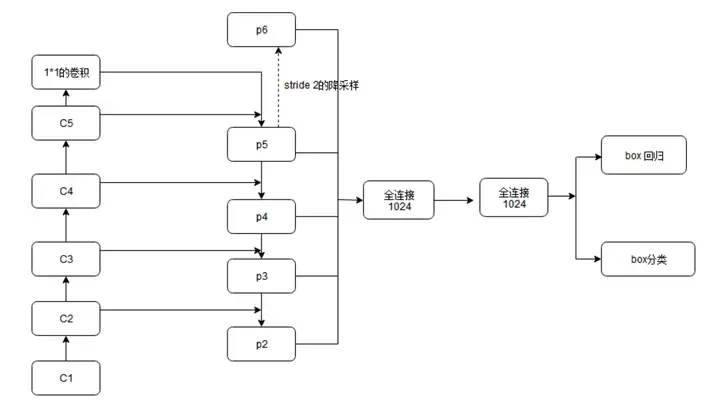
摘自博客:https://blog.csdn.net/xiamentingtao/article/details/78598027
自顶向下&跳接
对底向上的特征图一级级上采样,再加上底向上跳接来的高分辨低语义特征用于预测。
上采样的方法是简单的最近邻插值

一个最近邻插值的例子,上采样加起来 相当于把算完后在这个地方 把在这一层最能代表 该区域语义的特征值 加上上一层 类似于在数值上面的整数加上小数部分
其中跳接时前后维度不一致问题的解决方法采用了1*1conv。

通过跳接融合特征之后,还要进行一个3*3conv,以减轻最近邻插值带来的影响(因为周围的数字都比较相近,会出现重叠现象)

最后再看一眼网络图,一个完整的FPN架构就完成啦~
two_Stage的ROIPooling
目标检测typical architecture 通常可以分为两个阶段:
(1)region proposal:给定一张输入image找出objects可能存在的所有位置。这一阶段的输出应该是一系列object可能位置的bounding box。这些通常称之为region proposals或者 regions of interest(ROI)。
(2)final classification:确定上一阶段的每个region proposal是否属于目标一类或者背景。
这个architecture存在的一些问题是:
- 产生大量的region proposals 会导致performance problems,很难达到实时目标检测。
- 在处理速度方面是suboptimal。
- 无法做到end-to-end training。
这就是ROI pooling提出的根本原因。
ROI pooling层能实现training和testing的显著加速,并提高检测accuracy。该层有两个输入:
- 从具有多个卷积核池化的深度网络中获得的固定大小的feature maps;
- 一个表示所有ROI的N*5的矩阵,其中N表示ROI的数目。第一列表示图像index,其余四列表示其余的左上角和右下角坐标;
ROI pooling具体操作如下:
(1)根据输入image,将ROI映射到feature map对应位置;
(2)将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
(3)对每个sections进行max pooling操作;
这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
ROI pooling example
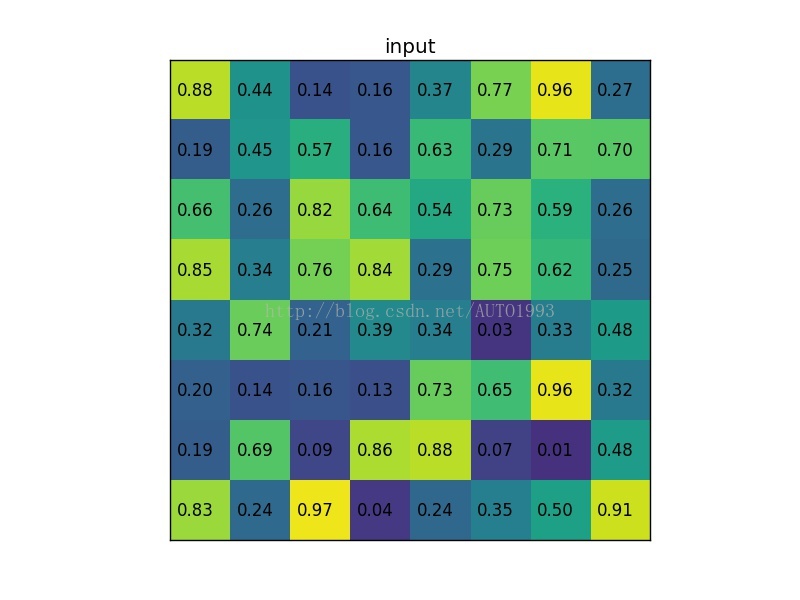
考虑一个88大小的feature map,一个ROI,以及输出大小为22.
(1)输入的固定大小的feature map
(2)region proposal 投影之后位置(左上角,右下角坐标):(0,3),(7,8)。
**
**
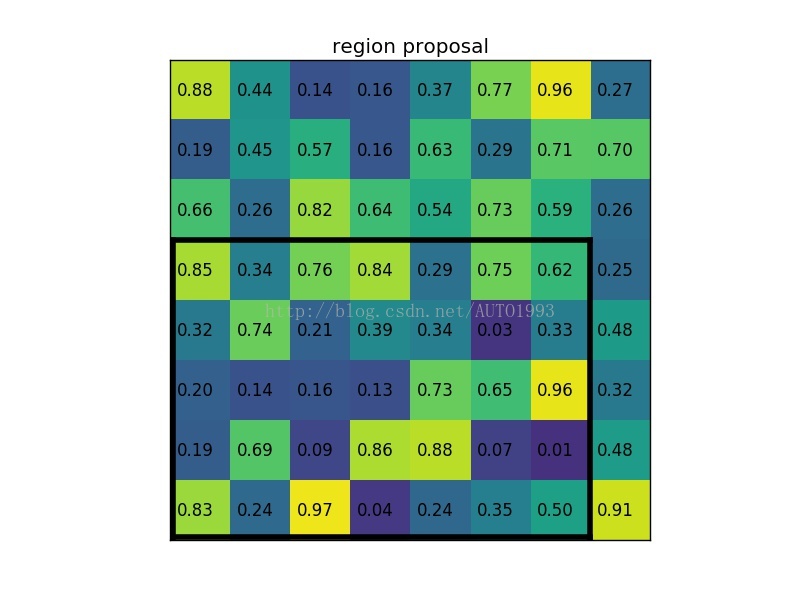
(3)将其划分为(22)个sections(因为输出大小为22),我们可以得到:
**
****
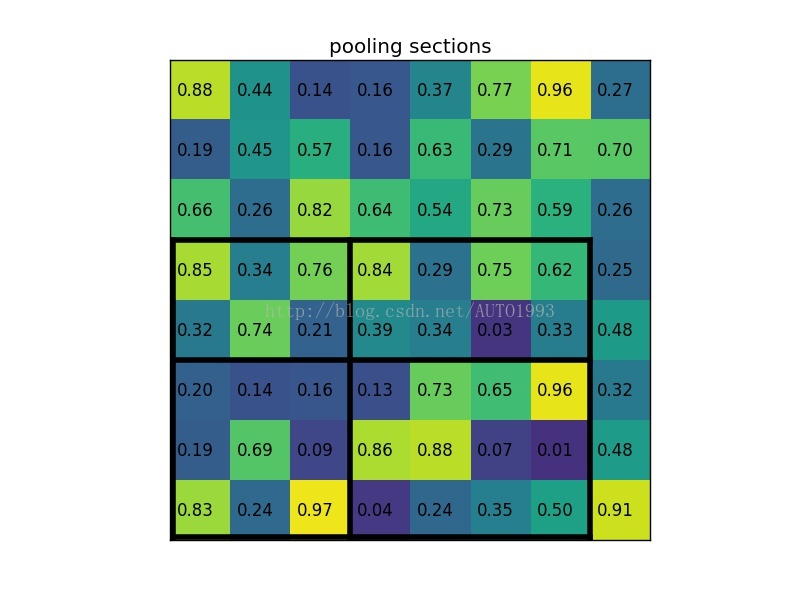
****(4)对每个section做max pooling,可以得到:
******
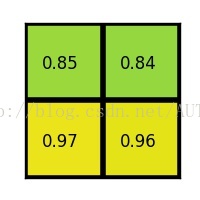
ROI pooling总结:
(1)用于目标检测任务;(2)允许我们对CNN中的feature map进行reuse;(3)可以显著加速training和testing速度;(4)允许end-to-end的形式训练目标检测系统。
RPN FPN ROIPooling的更多相关文章
- YOLO、SSD、FPN、Mask-RCNN检测模型对比
YOLO.SSD.FPN.Mask-RCNN检测模型对比 一.YOLO(you only look once) YOLO 属于回归系列的目标检测方法,与滑窗和后续区域划分的检测方法不同,他把检测任务当 ...
- python读取caffemodel文件
caffemodel是二进制的protobuf文件,利用protobuf的python接口可以读取它,解析出需要的内容 不少算法都是用预训练模型在自己数据上微调,即加载"caffemodel ...
- 特征金字塔网络Feature Pyramid Networks
小目标检测很难,为什么难.想象一下,两幅图片,尺寸一样,都是拍的红绿灯,但是一副图是离得很近的拍的,一幅图是离得很远的拍的,红绿灯在图片里只占了很小的一个角落,即便是对人眼而言,后者图片中的红绿灯也更 ...
- 论文阅读笔记三十三:Feature Pyramid Networks for Object Detection(FPN CVPR 2017)
论文源址:https://arxiv.org/abs/1612.03144 代码:https://github.com/jwyang/fpn.pytorch 摘要 特征金字塔是用于不同尺寸目标检测中的 ...
- 『计算机视觉』FPN:feature pyramid networks for object detection
对用卷积神经网络进行目标检测方法的一种改进,通过提取多尺度的特征信息进行融合,进而提高目标检测的精度,特别是在小物体检测上的精度.FPN是ResNet或DenseNet等通用特征提取网络的附加组件,可 ...
- FPN在faster_rcnn中实现细节代码说明
代码参考自:https://github.com/DetectionTeamUCAS/FPN_Tensorflow 主要分析fpn多层金字塔结构的输出如何进行预测. FPN金字塔结构插入在faster ...
- 【深度学习】目标检测算法总结(R-CNN、Fast R-CNN、Faster R-CNN、FPN、YOLO、SSD、RetinaNet)
目标检测是很多计算机视觉任务的基础,不论我们需要实现图像与文字的交互还是需要识别精细类别,它都提供了可靠的信息.本文对目标检测进行了整体回顾,第一部分从RCNN开始介绍基于候选区域的目标检测器,包括F ...
- Feature Pyramid Networks for Object Detection比较FPN、UNet、Conv-Deconv
https://vitalab.github.io/deep-learning/2017/04/04/feature-pyramid-network.html Feature Pyramid Netw ...
- 利用FPN构建Faster R-CNN检测
FPN就是所谓的金字塔结构的检测器,(Feature Pyramid Network) 把FPN融合到Faster rcnn中能够很大程度增加检测器对全图信息的认知, 步骤如图所示: 1.先将图像送入 ...
- 目标检测之faster-RCNN和FPN
今年(2017年第一季度),何凯明大神出了一篇文章,叫做fpn,全称是:feature pyramid network for object Detection,为什么发这篇文章,根据 我现在了解到的 ...
随机推荐
- Nessus 10.5.3 漏洞扫描器的下载安装与卸载
测试环境 Kali 2023.2 本教程使用脚本进行自动化安装.破解 文章地址:https://www.iculture.cc/software/pig=25546#wznav_7 偶然发现,特别好用 ...
- 20款VS Code实用插件推荐
前言 VS Code是一个轻量级但功能强大的源代码编辑器,轻量级指的是下载下来的VS Code其实就是一个简单的编辑器,强大指的是支持多种语言的环境插件拓展,也正是因为这种支持插件式安装环境开发让VS ...
- 《Kali渗透基础》12. 无线渗透(二)
@ 目录 1:无线协议栈 1.1:ifconfig 1.2:iwconfig 1.3:iw 1.4:iwlist 2:无线网卡配置 2.1:查看无线网卡 2.2:查看信道频率 2.3:扫描附近 AP ...
- C++ ASIO 实现异步套接字管理
Boost ASIO(Asynchronous I/O)是一个用于异步I/O操作的C++库,该框架提供了一种方便的方式来处理网络通信.多线程编程和异步操作.特别适用于网络应用程序的开发,从基本的网络通 ...
- 2023-08-30:用go语言编写。两个魔法卷轴问题。 给定一个数组arr,其中可能有正、负、0, 一个魔法卷轴可以把arr中连续的一段全变成0,你希望数组整体的累加和尽可能大。 你有两个魔法卷轴,
2023-08-30:用go语言编写.两个魔法卷轴问题. 给定一个数组arr,其中可能有正.负.0, 一个魔法卷轴可以把arr中连续的一段全变成0,你希望数组整体的累加和尽可能大. 你有两个魔法卷轴, ...
- 如何利用电商API接口来获取商品数据
要利用电商API接口来获取商品数据,我们可以按照以下步骤实现: 确定电商平台和API接口 不同的电商平台提供不同的API接口,因此我们需要确定我们要获取商品数据的电商平台,并选择相应的API接口进行调 ...
- Nomad 系列-Nomad 挂载存储卷
系列文章 Nomad 系列文章 概述 显然,如果 Nomad 要运行有状态存储,那么挂载存储卷就是必备功能. Nomad 允许用户通过多种方式将持久数据从本地或远程存储卷装载到任务环境中: 容器存储接 ...
- SICTF-2023 #Round2-WP-Crypto | Misc
Crypto 一.[签到]古典大杂烩 附件信息: 很明显可以看出来是base100,密码工具箱一把梭: SICTF{fe853b49-8730-462e-86f5-fc8e9789f077} 二.Ra ...
- UM 百度富文本编辑器自定义图片上传路径
UM 百度富文本编辑器自定义图片上传路径 因为公司要做图文编辑,选择了UM,但是直接存入Tomcat根目录下,不满足业务需求需要存入服务器上. 一.需要注意的是在um的JSP目录下已经存在了Uploa ...
- Java 21 新特性:Record Patterns
Record Patterns 第一次发布预览是在JDK 19.随后又在JDK 20中进行了完善.现在,Java 21开始正式推出该特性优化.下面我们通过一个例子来理解这个新特性. record Po ...