pyquery 学习
pyquery 是python仿照jQuery的严格实现,语法与jQuery几乎完全相同,所以对于学过前端的朋友们可以立马上手,没学过的小朋友也别灰心,我们马上就能了解到pyquery的强大.
1 安装
pip install pyquery
2 官方文档
http://pyquery.readthedocs.io/
3 学习代码html代码
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
4 字符串初始化
html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
# 格式化html文本,获取'$对象
doc=pq(html) # doc ---> '$'
#获取html文本下所有的li标签
print(doc('li'))
结果

5 URL初始化
from pyquery import PyQuery as pq
#直接获取网页源码
doc=pq(url='https://www.baidu.com')
title=doc(':submit').attr.value
print(title)
结果

6 文件初始化
from pyquery import PyQuery as pq
#读取文件
doc = pq(filename='demo.html')
print(doc('li'))
结果

7 基于css选择器
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
#找id=container标签下 所有class=list标签下的 所有的li标签
print(doc('#container .list li'))
结果

8 查找元素
子元素(不找孙子)
(链式寻找,doc($)找到的标签对象可以继续查找)
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
#先获取所有的class=list 标签
items = doc('.list')
#再获取所有的li标签
lis=items('li')
print(lis)
结果

#获取当前标签的所有子标签
lis=items.children()
print(type(lis))
print(lis)
结果

父元素(不找爷爷)
html = '''
<html>
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</html>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
#获取当前标签的父级别标签(不取爷爷标签)
container = items.parent()
print(type(container))
print(container)
结果

9 遍历
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
#寻找class=items-0并且class=active的标签
li = doc('.item-0.active')
print(li)
结果

10 获取文本
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">我们一起high high</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
#定位到 a标签
a = doc('.item-0.active a')
print(a)
#输出文本使用.text()
print(a.text())
结果
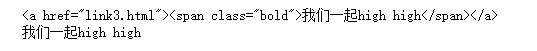
11 获取HTML
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
#获取对应 标签下的 html数据
print(li.html())
结果

12 DOM操作
addClass、removeClass
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
#给选定标签删除 class='active'
li.removeClass('active')
print(li)
#给选定标签添加 class='active'
li.addClass('active')
print(li)
结果

attr、css
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
#添加属性 name=link
li.attr('name', 'link')
print(li)
#添加css font-size=14px
li.css('font-size', '14px')
print(li)
结果

remove
html = '''
<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
#find 找到指定标签,remove 移除
wrap.find('p').remove()
print(wrap.text())
结果
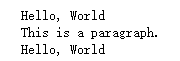
其他DOM方法
13 伪类选择器
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
# 获取第一个li 标签
li = doc('li:first-child')
print(li)
#获取最后一个li 标签
li = doc('li:last-child')
print(li)
#获取第2个li 标签
li = doc('li:nth-child(2)')
print(li)
#获取索引>2 的li 标签
li = doc('li:gt(2)')
print(li)
#获取偶数 的li标签
li = doc('li:nth-child(2n)')
print(li)
#获取文本包含second的 li标签
li = doc('li:contains(second)')
print(li)
结果

更多CSS选择器可以查看 http://www.w3school.com.cn/css/index.asp
pyquery 学习的更多相关文章
- python爬虫之pyquery学习
相关内容: pyquery的介绍 pyquery的使用 安装模块 导入模块 解析对象初始化 css选择器 在选定元素之后的元素再选取 元素的文本.属性等内容的获取 pyquery执行DOM操作.css ...
- pyquery学习笔记
很早就听说了pyquery的强大.写了个简单的测试程序实验下. 思路是找个动态网页,先用PhantomJS加载,然后用PYQUERY解析. 1.随便找了个带表格的股票网页,里面有大量的股票数据,测试的 ...
- python之pyquery 学习
pyquery是jQuery的Python实现,可以用以解析HTML网页的内容.官网文档:http://pythonhosted.org/pyquery/ 下载:https://pypi.python ...
- 学习PyQuery库
学习PyQuery库 好了,又是学习的时光啦,今天学习pyquery 来进行网页解析 常规导入模块(PyQuery库中的pyquery类) from pyquery import PyQuery as ...
- 学习使用pyquery解析器爬小说
一.背景:个人喜欢在网上看小说,但是,在浏览器中阅读小说不是很方便,喜欢找到小说的txt版下载到手机上阅读,但是有些小说不太好找txt版本,考虑自己从网页上爬一爬,自己搞定小说的txt版本.正好学习一 ...
- 爬虫学习笔记(六)PyQuery模块
PyQuery模块也是一个解析html的一个模块,它和Beautiful Soup用起来差不多,它是jquery实现的,和jquery语法差不多,会用jquery的人用起来就比较方便了. Pyquer ...
- python爬虫神器PyQuery的使用方法
你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有了一些 ...
- Pyquery API中文版
Pyquery的用法与jQuery相同,可以直接参考jQuery API学习.
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
随机推荐
- netty的编解码器理解(转)
一.简介 在网络应用中需要实现某种编解码器,将原始字节数据与自定义的消息对象进行互相转换.网络中都是以字节码的数据形式来传输数据的,服务器编码数据后发送到客户端,客户端需要对数据进行解码. 编解码器由 ...
- java并发之CyclicBarrier
一.CyclicBarrier简述 一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point).在涉及一组固定大小的线程的程序中,这些线程必须不时地互 ...
- mvn -DskipTests和-Dmaven.test.skip=true区别
在使用mvn package进行编译.打包时,Maven会执行src/test/java中的JUnit测试用例,有时为了跳过测试,会使用参数-DskipTests和-Dmaven.test.skip= ...
- nake_api_protect 请求保护器——防止请求被恶意刷
github : https://github.com/xjnotxj/wechat_interaction_auth -- nake_api_protect 接口请求保护器,根据 频率 + 次数 的 ...
- sessionStorage的保存和获取
保存一组数组,需要转换为字符串格式: var arr = [1,2,3]; var str = JSON.stringify(arr); window.sessionStorage.setItem(' ...
- 移动网站用backbone还是angular?
移动网站用backbone还是angular? 作者:戴嘉华链接:https://www.zhihu.com/question/21871888/answer/26130922来源:知乎著作权归作者所 ...
- python读文件的三个方法read()、readline()、readlines()详解
文件 runoob.txt 的内容如下: 1:www.runoob.com2:www.runoob.com3:www.runoob.com4:www.runoob.com5:www.runoob.co ...
- BZOJ4944 泳池 解题报告
题目描述 有一个 \(n\) 行无穷列的海域,每个格子有 \(q\) 的概率安全, \(1-q\) 的概率不安全.从中框出一个面积最大的矩形,满足以下两个条件: (1)矩形内的格子均安全: (2)矩形 ...
- bzoj 1064 假面舞会 图论??+dfs
有两种情况需要考虑 1.链:可以发现对最终的k没有影响 2.环:如果是真环(即1->2->3->4->1),可以看出所有可行解一定是该环的因数 假环呢??(1->2-&g ...
- BZOJ_3573_[Hnoi2014]米特运输_树形DP+hash
BZOJ_3573_[Hnoi2014]米特运输_树形DP+hash 题意: 给你一棵树每个点有一个权值,要求修改最少的权值,使得每个节点的权值等于其儿子的权值和且儿子的权值都相等. 分析: 首先我们 ...