scrapy学习

安装依赖
基础运用

在item中定义一个类(scrapy.Item)来保存 类似于django

yield返回两种东西,一种是在items中定义好的类 一种是新的请求
css选择器选取的标签
如果要保存到数据库 或者对数据进行一些处理 在pipeline中进行操作
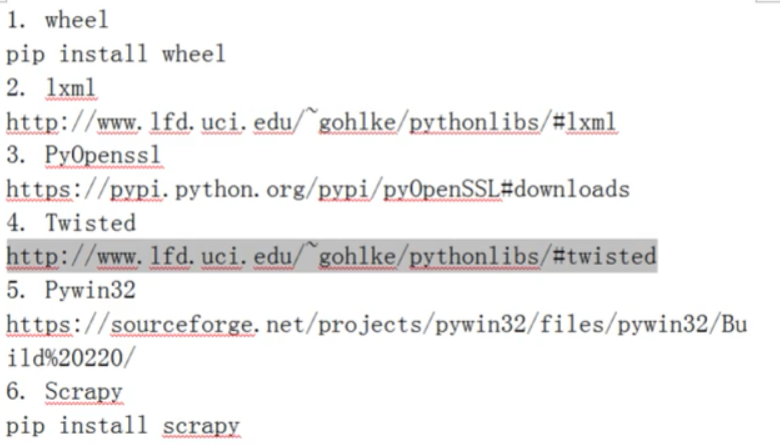
处理可以返回两种值
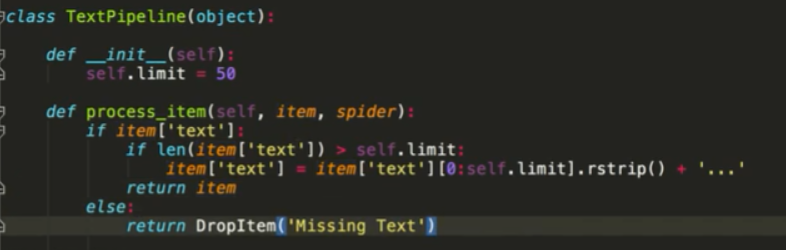
如果要存入数据库
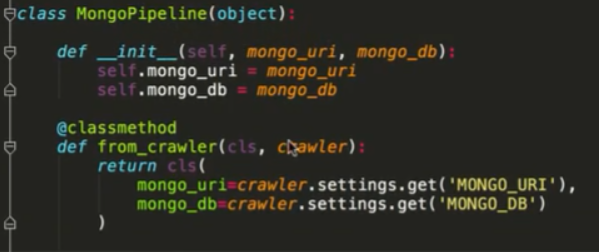

要记得修改pipeline设置

命令行命令
scrapy createproject projectName [dir]
开始新项目
scrapy genspider name url
创建爬虫
scrapy crawl name
执行对应爬虫命令 在class ClassName(scrapy.Spider)中定义类属性name
scrapy crawl [name] -o xxxx.json(.jl .csv .pickle .marshal ftp://user:pass@ftp.example.com/path/xxx.csv)
scrapy check 检查是否有错
scrapy list 查看所有爬虫
scrapy学习的更多相关文章
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- Scrapy学习篇(七)之Item Pipeline
在之前的Scrapy学习篇(四)之数据的存储的章节中,我们其实已经使用了Item Pipeline,那一章节主要的目的是形成一个笼统的认识,知道scrapy能干些什么,但是,为了形成一个更加全面的体系 ...
- Scrapy:学习笔记(2)——Scrapy项目
Scrapy:学习笔记(2)——Scrapy项目 1.创建项目 创建一个Scrapy项目,并将其命名为“demo” scrapy startproject demo cd demo 稍等片刻后,Scr ...
- Scrapy:学习笔记(1)——XPath
Scrapy:学习笔记(1)——XPath 1.快速开始 XPath是一种可以快速在HTML文档中选择并抽取元素.属性和文本的方法. 在Chrome,打开开发者工具,可以使用$x工具函数来使用XPat ...
- scrapy学习(完全版)
scrapy1.6中文文档 scrapy1.6中文文档 scrapy中文文档 Scrapy框架 下载页面 解析页面 并发 深度 安装 scrapy学习教程 如果安装了anconda,可以在anacon ...
- python爬虫之Scrapy学习
在爬虫的路上,学习scrapy是一个必不可少的环节.也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习.开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学 ...
- 转载一个不错的Scrapy学习博客笔记
背景: 最近在学习网络爬虫Scrapy,官网是 http://scrapy.org 官方描述:Scrapy is a fast high-level screen scraping and web c ...
- Scrapy学习篇(十一)之设置随机User-Agent
大多数情况下,网站都会根据我们的请求头信息来区分你是不是一个爬虫程序,如果一旦识别出这是一个爬虫程序,很容易就会拒绝我们的请求,因此我们需要给我们的爬虫手动添加请求头信息,来模拟浏览器的行为,但是当我 ...
- Scrapy学习篇(九)之文件与图片下载
Media Pipeline Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 item pipelines . 这些pipeline有些共同的方 ...
- Scrapy学习笔记(5)-CrawlSpider+sqlalchemy实战
基础知识 class scrapy.spiders.CrawlSpider 这是抓取一般网页最常用的类,除了从Spider继承过来的属性外,其提供了一个新的属性rules,它提供了一种简单的机制,能够 ...
随机推荐
- 转载:img是什么元素?置换元素?
转载: https://blog.csdn.net/kingliguo/article/details/52643594 img是什么元素? 应是行内元素,判断一个元素是行内元素,还是块元素,无非就是 ...
- HTML5网页点击分享到whatsapp
一.在网页头部加入分享标题和url,代码如下: <meta name="whatsapp:url" class="share_url" content=& ...
- 初识Haskell 三:函数function
对Discrete Mathematics Using a Computer的第一章Introduction to Haskell进行总结.环境Windows 函数毫无疑问是函数式语言的核心. 在Ha ...
- Python进阶6---序列化与反序列化
序列化与反序列化*** 为什么要序列化 ? 定义 pickle库 #序列化实例 import pickle lst = 'a b c'.split() with open('test.txt','wb ...
- 原型设计的工具-----Axure RP
原型设计的工具-----Axure RP 1.原型设计的工具 目前能用于原型设计的工具有很多,其中有七种比较好. (1) Axure RP (2) Mockplus (3) Jus ...
- python调用openstack的api,create_instance的程序解析
python调用openstack的api,create_instance的程序解析 2017年10月17日 15:27:24 CloudXli 阅读数:848 版权声明:本文为博主原创文章,未经 ...
- mysql left join 优化
参考 https://www.cnblogs.com/zedosu/p/6555981.html
- [pip]upgrade outdated pip package on windows / 在windows上更新所有过时的pip包
首先更新pip自身: python -m pip install -U pip 查询过期包: pip list --outdated --format=columns Package Version ...
- Nginx-反向代理实现
Nginx 反向代理操作案例 Nginx反向代理的组件模块 upstream模块介绍->点我< http_proxy_module模块介绍->点我< 环境准备 1)四台服务器都 ...
- nexus5 root
LG nexus5 安装新的lineage 14.1系统卡刷 supersuV2.82失败,开机卡动画界面. 改回刷入2016年11月下的cm 13 的包,三清后卡刷supersuV2.82,成功.