Scrapy - CrawlSpider爬虫
crawlSpider 爬虫
思路:
从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数。
1. 创建项目
scrapy startproject myspiderproject
2. 创建crawlSpider 爬虫
scrapy genspider -t crawl 爬虫名 爬取网站域名
3. 启动爬虫
scrapy crawl 爬虫名 # 会打印日志 scrapy crawl 爬虫名 --nolog
crawlSpider 的参数解析:
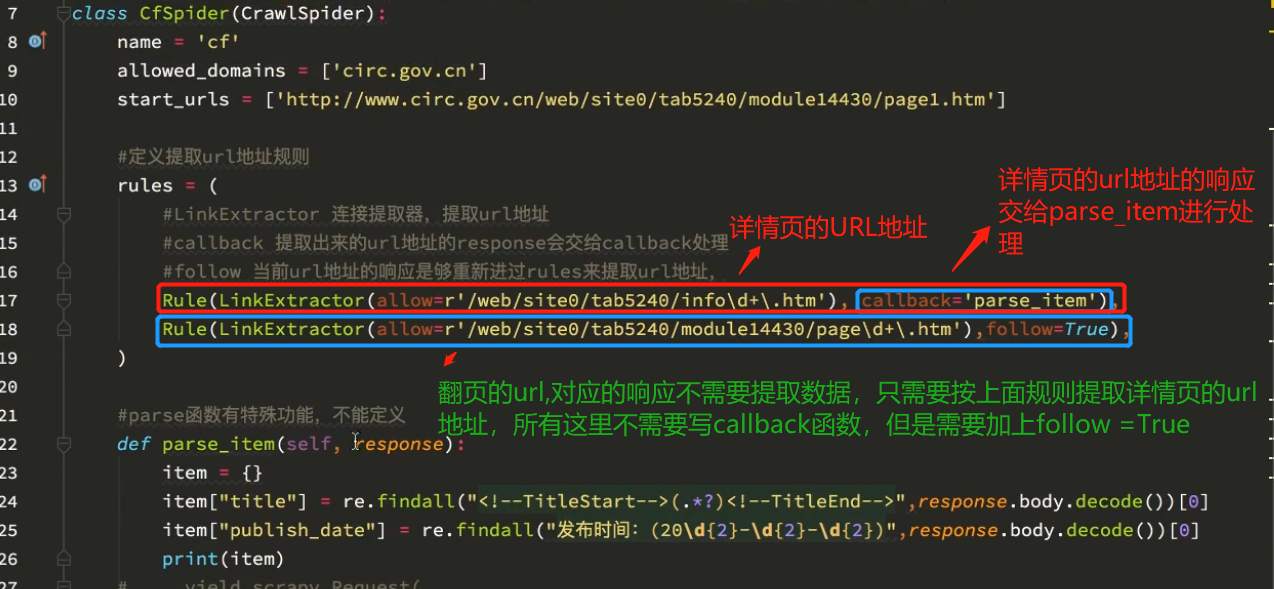
案例
需求:爬取csdn上面所有的博客专家及其文章的文章 Url地址:http://blog.csdn.net/experts.html 。
分析:

使用crawlSpider 的注意点:

补充知识点:

Scrapy - CrawlSpider爬虫的更多相关文章
- scrapy 中crawlspider 爬虫
爬取目标网站: http://www.chinanews.com/rss/rss_2.html 获取url后进入另一个页面进行数据提取 检查网页: 爬虫该页数据的逻辑: Crawlspider爬虫类: ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- scrapy -->CrawlSpider 介绍
scrapy -->CrawlSpider 介绍 1.首先,通过crawl 模板新建爬虫: scrapy genspider -t crawl lagou www.lagou.com 创建出来的 ...
- crawlspider爬虫:定义url规则
spider爬虫,适合meta传参的爬虫(列表页,详情页都有数据要爬取的时候) crawlspider爬虫,适合不用meta传参的爬虫 scrapy genspider -t crawl it it. ...
- 创建CrawlSpider爬虫简要步骤
创建CrawlSpider爬虫简要步骤: 1. 创建项目文件: e.g: scrapy startproject douyu (douyu为项目名自定义) 2. 进入项目文件: e.g: cd dou ...
- 爬虫(十八):Scrapy框架(五) Scrapy通用爬虫
1. Scrapy通用爬虫 通过Scrapy,我们可以轻松地完成一个站点爬虫的编写.但如果抓取的站点量非常大,比如爬取各大媒体的新闻信息,多个Spider则可能包含很多重复代码. 如果我们将各个站点的 ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
随机推荐
- Bootstrap3基础 img-thumbnail 给图片加一个圆角的边框
内容 参数 OS Windows 10 x64 browser Firefox 65.0.2 framework Bootstrap 3.3.7 editor ...
- Android 系统(64)---Android中m、mm、mmm、mma、mmma的区别【转】
本文转载自:https://blog.csdn.net/zhangbijun1230/article/details/80196379 Android中m.mm.mmm.mma.mmma的区别 m ...
- S.M.A.R.T.记录几块ssd硬盘
1.闪迪至尊超级速(Extreme pro) 2.三星sm961 (m2接口) 3.intel 750 (pice接口) ps: 因为sm961,intel750都是nvme协议,网上大部分软件测试都 ...
- X-Pack for the Elastic Stack [6.2] » Securing the Elastic Stack »Setting Up User Authentication
https://www.elastic.co/guide/en/x-pack/current/setting-up-authentication.html Active Directory User ...
- 怎样建立你自己的MASM导入库
by Iczelion (翻译:花心萝卜yqzq@163.net) 9.5.2000 这篇短文是讲述关于建立MASM导入库(import libraries)技巧,我假设你已经知道什么是导入库.在下面 ...
- 修改控制台为Consolas字体
windows下控制台字体修改为Consolas字体比较好看,修改步骤如下: 临时修改 命令行cmd命令进入控制台,输入chcp 437命令,执行. 右键点击标题栏进入属性,修改字体为Consolas ...
- Visual Question Answering with Memory-Augmented Networks
Visual Question Answering with Memory-Augmented Networks 2018-05-15 20:15:03 Motivation: 虽然 VQA 已经取得 ...
- 【SQL】【Join基础】了解sql中的join用法,看这一篇就够了
转自: https://www.cnblogs.com/reaptomorrow-flydream/p/8145610.html SQL JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之 ...
- Oracle存储过程的异常处理
1.为了提高存储过程的健壮性,避免运行错误,当建立存储过程时应包含异常处理部分. 2.异常(EXCEPTION)是一种PL/SQL标识符,包括预定义异常.非预定义异常和自定义异常: 3.预定义异常是指 ...
- “ORA-06550: 第 1 行, 第 7 列”解决方法
将本机能正常运行的维修生产日志代码发布到公司内测环境里无法正常运行,报错如下: execute() - pls–QuartzJob.java–quartzjob 开始执行! java.sql.SQLE ...