Coursera在线学习---第七节.支持向量机(SVM)
一、代价函数

对比逻辑回归与支持向量机代价函数。
cost1(z)=-log(1/(1+e-z)) cost0(z)=-log(1-1/(1+e-z))

二、支持向量机中求解代价函数中的C值相当于1/λ。
如果C值过大,相当于λ过小,容易过拟合
如果C值过小,相当于λ过大,容易欠拟合。

三、大间隔分类(large margin classification)
两个向量的内积等于一个向量的长度乘以另一个向量在该向量的投影长度。
如下图:v*u=||u||*p。||u||为向量u的长度,p为向量v在u向量上的投影长度。

SVM代价函数求最优解,就是在约束条件下求极值的过程。如下图所示:

也就是在参数向量Θ与样本集X内积都≥1的情况下,使得Θ的长度最小。这种情况下只要离分类间隔面最近的样本点与Θ的内积为1就满足了约束条件,然后再求使得Θ的长度最小。
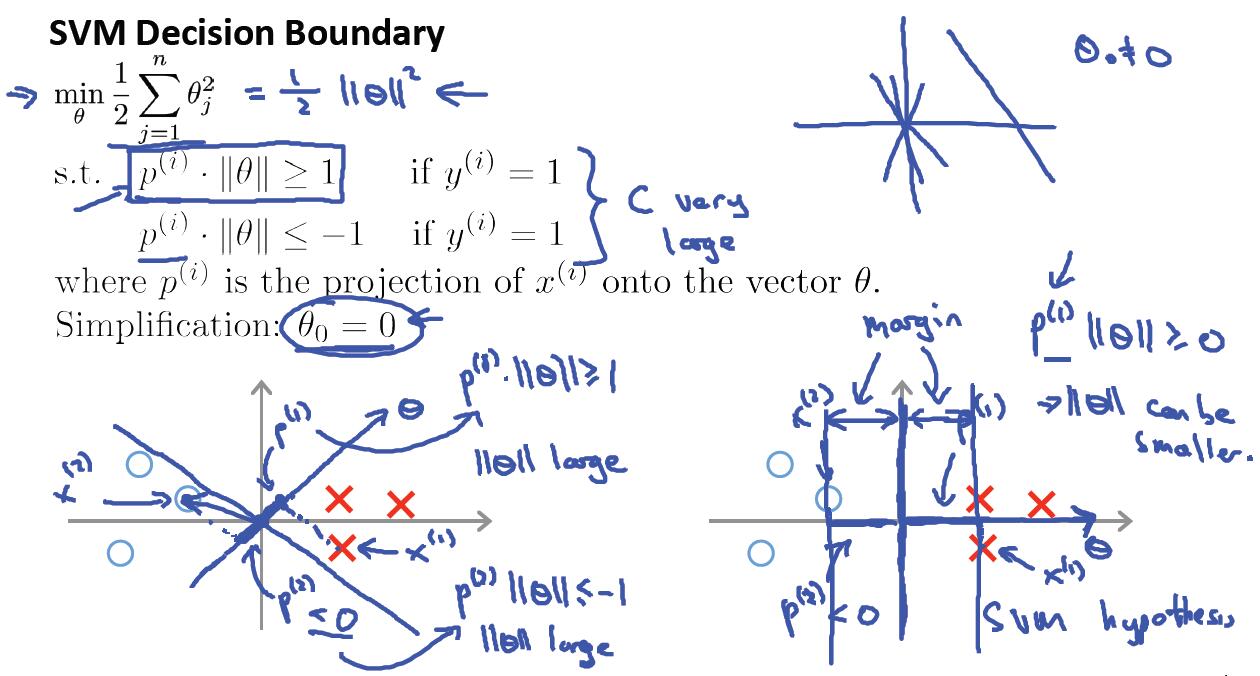
如上图所示,只有Θ的向量方向旋转到水平方向的时候,最近样本到Θ向量的投影长度才最长,这样才会使得Θ的值最小,因为二者的内积是固定为1的。而最大分类间隔面就是Θ的垂直平面,因为Θ与X组成的分类平面方程中,Θ与法向量方向是一样,法向量是垂直于平面的。
四、高斯核函数




五、高斯核函数中σ^2的选择
σ^2过大,f变化比较平滑,较慢,容易造成高偏差
σ^2过小,f变化比较大,斜率大,容易造成高方差

六、如何使用SVM?
1)可以使用现有的软件包,比如:liblinear、libsvm.但是你需要做的是:
①.选择参数C
②.选择核函数Kernel
③.选择σ^2
2)线性核函数=没有核函数,直接使用Θ0+Θ1*X1+Θ2*X2...
注:如果特征维度n比较大,而训练样本集m又比较小的情况下,就没有必要使用核函数,选择线性核函数即可。因为,如果样本很少,使用核函数的话,容易过拟合!
七、利用高斯核函数之前一定要先进行归一化处理,以防止在计算距离公式中由某一维度数值较大的特征来决定。

八、什么时候用Logistic Regression ,什么时候用SVM?
1)当特征维度n>=m时,例如文本分类,词的特征维度可能达到10000以上,而样本数量m可能只有几百、几千等。这个时候建议使用Logistic Regression 或者无核函数SVM。因为样本很少的情况下,这两个就足以工作的很好,况且也没有足够多的数据来拟合非常复杂的非线性函数。
2)如果特征维度n比较小(比如:n=1~1000,m=10~10000),m是中等大小的话,可以使用带高斯核函数的SVM分类算法。
3)如果n较小,而m非常非常大的情况下(比如n=500,m=50000),此时用高斯核函数会非常非常慢。这个时候我们选择增加更多的特征,使n增大,然后使用Logistic Regression 或者无核函数SVM。
注:尽管这些问题神经网络也能处理,但是相比svm而言,训练时间要长一些,svm则快的多。另外,svm的优化问题是一个凸优化问题,一个好的svm软件包总能找到全局最小值或接近它的值,而神经网络有时候会出现局部最优解的问题。
九、为什么SVM对缺失数据敏感?
这里说的缺失数据是指缺失某些特征数据,向量数据不完整。SVM没有处理缺失值的策略(决策树有)。而SVM希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。缺失特征数据将影响训练结果的好坏。
Coursera在线学习---第七节.支持向量机(SVM)的更多相关文章
- 文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论
前言: 经历过文本的特征提取,使用LibSvm工具包进行了测试,Svm算法的效果还是很好的.于是开始逐一的去了解SVM的原理. SVM 是在建立在结构风险最小化和VC维理论的基础上.所以这篇只介绍关于 ...
- Coursera在线学习---第十节.大规模机器学习(Large Scale Machine Learning)
一.如何学习大规模数据集? 在训练样本集很大的情况下,我们可以先取一小部分样本学习模型,比如m=1000,然后画出对应的学习曲线.如果根据学习曲线发现模型属于高偏差,则应在现有样本上继续调整模型,具体 ...
- Coursera在线学习---第六节.构建机器学习系统
备: High bias(高偏差) 模型会欠拟合 High variance(高方差) 模型会过拟合 正则化参数λ过大造成高偏差,λ过小造成高方差 一.利用训练好的模型做数据预测时,如果效果不好 ...
- Coursera在线学习---第五节.Logistic Regression
一.假设函数与决策边界 二.求解代价函数 这样推导后最后发现,逻辑回归参数更新公式跟线性回归参数更新方式一摸一样. 为什么线性回归采用最小二乘法作为求解代价函数,而逻辑回归却用极大似然估计求解? 解答 ...
- Coursera在线学习---第四节.过拟合问题
一.解决过拟合问题方法 1)减少特征数量 --人为筛选 --靠模型筛选 2)正则化(Regularization) 原理:可以降低参数Θ的数量级,使一些Θ值变得非常之小.这样的目的既能保证足够的特征变 ...
- VUE2.0实现购物车和地址选配功能学习第七节
第七节 卡片选中,设置默认 1.卡片选中html:<li v-for="(item,index) in filterAddress" v-bind:class="{ ...
- Coursera在线学习---第九节(1).异常数据检测(Anomaly Detection)
一.如何构建Anomaly Detection模型? 二.如何评估Anomaly Detection系统? 1)将样本分为6:2:2比例 2)利用交叉验证集计算出F1值,可以用F1值选取概率阈值ξ,选 ...
- Coursera在线学习---第一节.梯度下降法与正规方程法求解模型参数比较
一.梯度下降法 优点:即使特征变量的维度n很大,该方法依然很有效 缺点:1)需要选择学习速率α 2)需要多次迭代 二.正规方程法(Normal Equation) 该方法可以一次性求解参数Θ 优点:1 ...
- Coursera在线学习---第九节(2).推荐系统
一.基于内容的推荐系统(Content Based Recommendations) 所谓基于内容的推荐,就是知道待推荐产品的一些特征情况,将产品的这些特征作为特征变量构建模型来预测.比如,下面的电影 ...
随机推荐
- Nautilus-Share-Message: Called "net usershare info" but it failed: Failed to
See what nautilus processes are running : ps aux | grep nautilus Kill all nautilus processes you see ...
- python: error while loading shared libraries: libpython2.7.so.1.0: cannot open shared object file: No such file or directory
#vi /etc/ld.so.conf.d/python2.7.conf 加入/usr/local/python27/lib 保存退出后执行 #ldconfig
- SQL SERVER技术内幕之7 透视与逆透视
1.透视转换 透视数据(pivoting)是一种把数据从行的状态旋转为列的状态的处理,在这个过程中可能须要对值进行聚合. 每个透视转换将涉及三个逻辑处理阶段,每个阶段都有相关的元素:分组阶段处理相关的 ...
- [CF551E]GukiZ and GukiZiana
题目大意:一个长度为$n(n\leqslant5\times10^5)$的数组,有两个操作: $1\;l\;r\;x:$把区间$[l,r]$加上$x$ $2\;x:$询问$x$第一次出现和最后一次出现 ...
- CF311B Cats Transport 斜率优化DP
题面:CF311B Cats Transport 题解: 首先我们观察到山与距离其实是没有什么用的,因为对于任意一只猫,我们都可以直接算出如果有一个人要恰好接走它,需要在哪一时刻出发,我们设第i只猫对 ...
- 第一次BC
BestCoder Round #90 1001 Kblack loves flag 太弱只写了这一道水题. 首先这个题面就是,完全不知道它在说什么.开始5mins后我还完全不知道这个题想要表达什么. ...
- [LOJ 6000]搭配飞行员
link 其实就是一道二分图匹配板子,我们建立$S$,$T$为源点与汇点,然后分别将$S$连向所有正驾驶员,边权为$1$,然后将副驾驶员与$T$相连,边权为$1$,将数据中给出的$(a,b)$,将$a ...
- Centos +django+nginx
WSGI配置 #!/usr/bin/python """ WSGI config for rana project. It exposes the WSGI callab ...
- django 给前端传递HTML内容
django从view向template传递HTML字符串的时候,django默认不渲染此HTML,原因是为了防止这段字符串里面有恶意攻击的代码. 如果需要渲染这段字符串,需要在view里这样写: f ...
- SQL Server 2008设置主键为自增
环境:SQL Server 2008 问题:设置主键,将主键设为自增. 解决:点击table->选中表->design->选中需要设置主键的字段,单击右键"设置主键&quo ...