python实例:爬取caoliu图片,同时下载到指定的文件夹内
本脚本主要实现爬取caoliu某图片板块,前3页当天更新的帖子的所有图片,同时把图片下载到对应帖子名创建的文件夹中
爬虫主要通过python xpath来实现,同时脚本内包含,创建文件夹,分割数据,下载等操作
首先,我们分析下caoliu某图片板块的资源链接

贴子对应的页面元素

展开元素,可以看到帖子的实际地址,所以我们第一步就是把地址都给扒下来
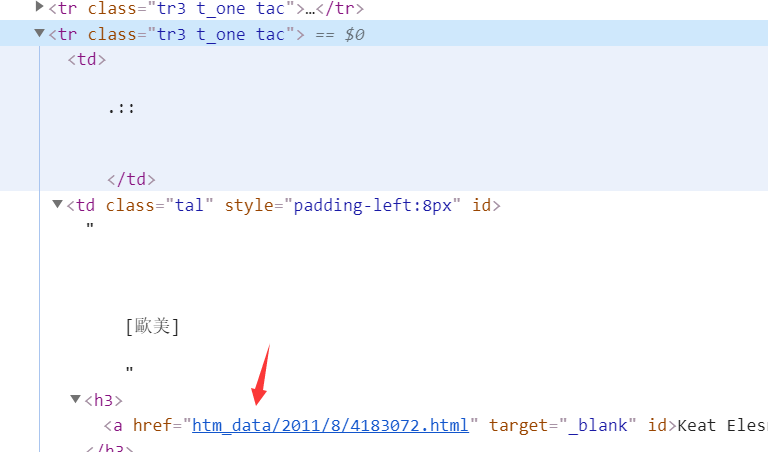
AA里包含了caoliu某图片板块前3页的地址,创建lit空集来收集爬取来的帖子地址
def stepa (AA):
lit=[]
for url in AA:
response = requests.get(url=url, headers=headers, timeout=100000)
wb_data = response.text.encode('iso-8859-1').decode('gbk')#caoliu的编码格式需要对返回值重新转码
# 将页面转换成文档树
html = etree.HTML(wb_data)
a = html.xpath('//td[@class="tal"]//@href')#帖子地址xpath
lit.append(a)
return(lit)
alllink = stepa(AA)
alllink=alllink[0]
执行后的结果

我们获得帖子地址后,获取的帖子地址如上图,所以需要对地址进行处理,同时屏蔽掉站务贴
BB是需要屏蔽掉的站务贴集合,alllink是上一步骤获取的图贴集合,创建循环,从alllink集合里每次取一个链接,if用于跳过账务贴
def stepb(alllink,headers,BB):
for url in alllink:
#print(url)
if "read" in url:
continue
elif url in BB:
continue
else:
url='https://cl.hexie.xyz/'+url
print(url)
response = requests.get(url, headers=headers)
response=response.text.encode('iso-8859-1').decode('gbk')
html = etree.HTML(response)
b = html.xpath('//div[@class="tpc_content do_not_catch"]//@ess-data')#图片地址xpath
title = html.xpath('/html/head/title/text()')#帖子名称xpath
title=title[0]
title=title[:-27]#去掉帖子名称后面共同的和影响创建文件夹的部分
print(title)
因为获取的链接”htm_data/2011/8/4182612.html“需要重新拼接
拼接步骤”url='https://cl.hexie.xyz/'+url“
后面的步骤就是访问拼接好的url,获取帖子内的图片地址,我们分析下图片资源的元素信息
图片地址存放在"tpc_content do_not_catch"class内,所以xpath可写成”
//div[@class="tpc_content do_not_catch"]//@ess-data“
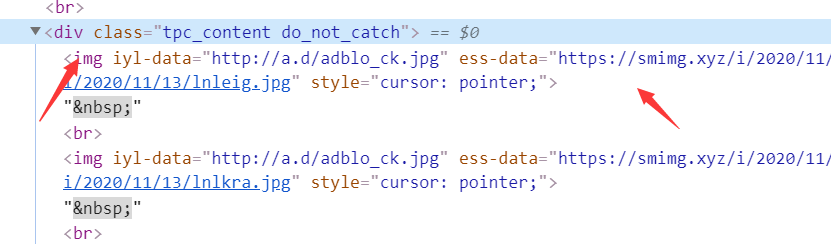
如此,图片地址就获取到了
接下来,就是通过地址,下载图片资源到本地
创建文件夹参考:https://www.cnblogs.com/becks/p/13977943.html
下载图片到本地参考:https://www.cnblogs.com/becks/p/13978612.html
附上整个脚本
# -*-coding:utf8-*-
# encoding:utf-8
# 本脚本用于爬取草榴图片板块(新时代的我们)最近3天的所有帖子的所有图片,每一个帖子创建独立的文件夹,图片下载到文件夹中
import requests
from lxml import etree
import os
import sys
import re
import random
from urllib import request
import io #sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
#解决vscode窗口输出乱码的问题,需要import io 和import sys headers = {
'authority': 'cl.hexie.xyz',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': '__cfduid=d9b8dda581516351a1d9d388362ac222c1603542964',
} path = os.path.abspath(os.path.dirname(sys.argv[0])) AA=[
"https://cl.和谐.xyz/thread0806.php?fid=8",
#"https://cl.和谐.xyz/thread0806.php?fid=8&search=&page=2",
#"https://cl.和谐.xyz/thread0806.php?fid=8&search=&page=3"
] #AA里包含最新前3页列表链接 BB=["htm_data/1109/8/594739.html",
"htm_data/1803/8/3018643.html",
"htm_data/0706/8/36794.html",
"htm_data/1106/8/524775.html",
"htm_data/2011/8/344500.html"] #BB里面包含需要跳过的帖子,这部分帖子是站务贴,里面没资源 #第1步,获取每一页所有的帖子地址,地址格式“https://cl.和谐.xyz/htm_data/2011/8/4182841.html”
def stepa (AA):
lit=[]
for url in AA:
response = requests.get(url=url, headers=headers, timeout=100000)
wb_data = response.text.encode('iso-8859-1').decode('gbk')#草榴的编码格式需要对返回值重新转码
# 将页面转换成文档树
html = etree.HTML(wb_data)
a = html.xpath('//td[@class="tal"]//@href')#帖子地址xpath
lit.append(a)
return(lit)
alllink = stepa(AA)
alllink=alllink[0] #第2步,获取每一篇帖子里所有图片的地址,地址格式“https://和谐.xyz/i/2020/11/15/sedlrk.jpg"
def stepb(alllink,headers,BB):
for url in alllink:
#print(url)
if "read" in url:
continue
elif url in BB:
continue
else:
url='https://cl.和谐.xyz/'+url
print(url)
response = requests.get(url, headers=headers)
response=response.text.encode('iso-8859-1').decode('gbk')
html = etree.HTML(response)
b = html.xpath('//div[@class="tpc_content do_not_catch"]//@ess-data')#图片地址xpath
title = html.xpath('/html/head/title/text()')#帖子名称xpath
title=title[0]
title=title[:-27]#去掉帖子名称后面共同的和影响创建文件夹的部分
print(title) path2 = r'D://tu'
os.mkdir(path2 + './'+str(title))
#以上两行即在d盘tu目录下创建名称为变量title的文件夹 for c in b:
print("loading"+" " +c)
pic_name = random.randint(0,100)#图片名称随机命令 r = requests.get(c,stream=True,headers=headers)
time = r.elapsed.total_seconds()#获取响应时间
if time > 1000:
continue
else:
with open(path2 + './'+str(title) +'./'+str(pic_name) +'.jpg', 'wb') as fd:
for chunk in r.iter_content():
fd.write(chunk)
#从87行开始即下载的脚本,把图片下载到上文创建的指定文件夹中 stepb(alllink,headers,BB) #第3步:提示爬取完成
def over():
print("ok")
over()
嘿嘿

python实例:爬取caoliu图片,同时下载到指定的文件夹内的更多相关文章
- Python:爬取网站图片并保存至本地
Python:爬取网页图片并保存至本地 python3爬取网页中的图片到本地的过程如下: 1.爬取网页 2.获取图片地址 3.爬取图片内容并保存到本地 实例:爬取百度贴吧首页图片. 代码如下: imp ...
- python 3 爬取百度图片
python 3 爬取百度图片 学习了:https://blog.csdn.net/X_JS612/article/details/78149627
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- Python简单爬取Amazon图片-其他网站相应修改链接和正则
简单爬取Amazon图片信息 这是一个简单的模板,如果需要爬取其他网站图片信息,更改URL和正则表达式即可 1 import requests 2 import re 3 import os 4 de ...
- Python爬虫爬取网页图片
没想到python是如此强大,令人着迷,以前看见图片总是一张一张复制粘贴,现在好了,学会python就可以用程序将一张张图片,保存下来. 今天逛贴吧看见好多美图,可是图片有点多,不想一张一张地复制粘贴 ...
- python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本. 工具:python3.7+selenium+任意一款编辑器 前期准备:可 ...
- Python实例---爬取下载喜马拉雅音频文件
PyCharm下python爬虫准备 打开pycharm 点击设置 点击项目解释器,再点击右边+号 搜索相关库并添加,例如:requests 喜马拉雅全网递归下载 打开谷歌/火狐浏览器,按F12打开开 ...
- 【Python】爬取网站图片
import requests import bs4 import urllib.request import urllib import os hdr = {'User-Agent': 'Mozil ...
- python保存爬取的图片
用爬虫抓取图片的保存 保存图片 request=urllib2.Request(randNumberUrl,data,headers) picture=opener.open(request).rea ...
随机推荐
- Kotlin:【初始化】主构造函数、在主构造函数里定义属性、次构造函数、默认参数、初始化块、初始化顺序
- XposedAPI pg walkthrough Intermediate
nmap ┌──(root㉿kali)-[~/lab] └─# nmap -p- -A 192.168.226.134 Starting Nmap 7.94SVN ( https://nmap.org ...
- golang轻量级版本管理工具g安装使用
使用 g 可以在 windows 上切换使用不同版本的 golang GitHub仓库地址 https://github.com/voidint/g GitHub下载连接 https://github ...
- 理解ID3决策树
决策树是一个树形结构,类似下面这样: 上图除了根节点外,有三个叶子节点和一个非叶子节点. 在解决分类问题的决策树中,叶子节点就表示所有的分类,比如这里的分类就有3种:无聊时阅读的邮件.需及时处理的邮件 ...
- [WC2014] 紫荆花之恋 题解
啊啊啊啊啊啊啊啊啊啊啊我终于改完啦啊啊啊啊啊啊啊. 因为没有在最开始的时候将所有点设置为已经重构的,所以直接 \(R15-R70\) 间卡了两三天. 似乎也是我第一次大规模使用指针了. 这道题假如只有 ...
- swiper8.x在vue中的wtf
首先我是想开启鼠标滚动的效果,在官网上发现如下说法 引入就引入吧,引入路径还不说,在网上看其他教程发现路径是 引入完了,怎么办呢,又不会了,官网没有教程,网上的教程全是关于vue-awesome-sw ...
- autMan奥特曼机器人-自建autMan插件市场
一.自建市场配置 配置参数 二.上架设置 设置哪些插件上架,哪些不上架 三.检测是否成功 怎样检查是否成功了?订阅一下自己,然后看应用市场上是否显示 四.用户怎样购买插件 用户想买自建市场作者的插件, ...
- 读论文-电子商务产品推荐的序列推荐系统综述与分类(A Survey and Taxonomy of Sequential Recommender Systems for E-commerce Product Recommendation)
前言 今天读的这篇文章是于2023年发表在"SN Computer Science"上的一篇论文,这篇文章主要对序列推荐系统进行了全面的调查和分类,特别是在电子商务领域的应用.文章 ...
- 【论文随笔】深度推荐系统的自动化_一项调查(Automl for deep recommender systems_ A survey)
前言 今天读的论文为一篇于2021年1月发表在ACM Transactions on Information Systems的论文,本文是一篇关于深度推荐系统自动化机器学习(AutoML)的综述,由R ...
- Windows 提权-UAC 绕过
本文通过 Google 翻译 UAC-Bypass – Windows Privilege Escalation 这篇文章所产生,本人仅是对机器翻译中部分表达别扭的字词进行了校正及个别注释补充. 导航 ...