[大数据]Hadoop HDFS文件系统命令集
基本格式: hadoop fs -cmd [args]
1 Query
- 显示命令的帮助信息
# hadoop fs -help [cmd]
- 查看hadoop/hdfs的用户
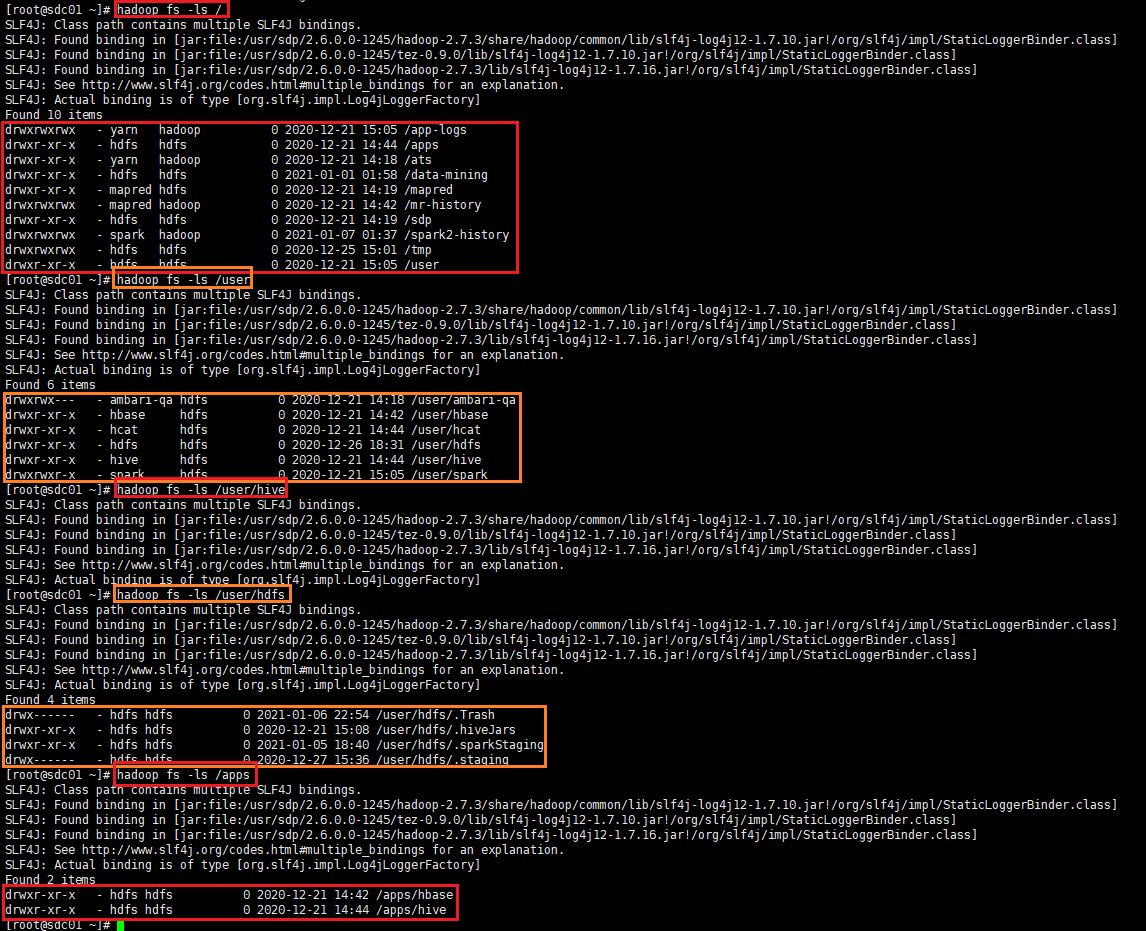
# hdfs dfs -ls /user
更改hdfs的目录权限: hdfs dfs -chwon sdc /user/sdc

- 查看HDFS文件及目录
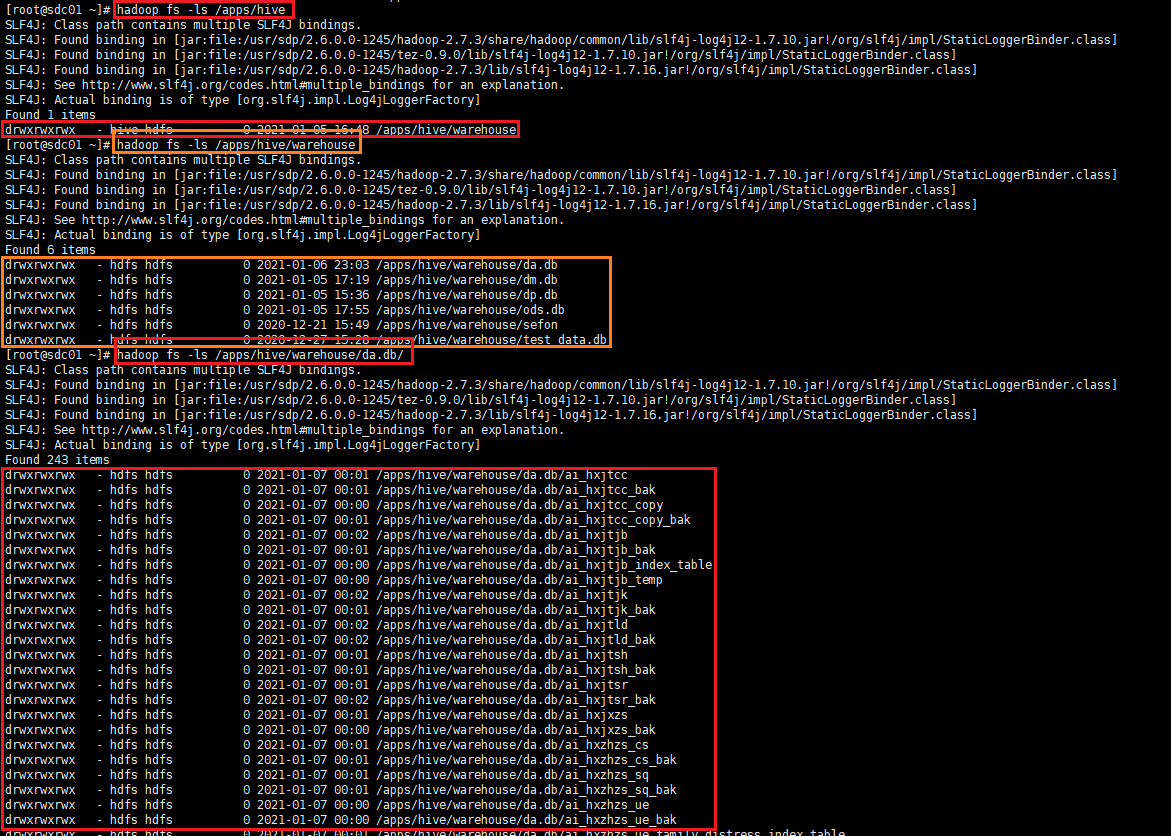
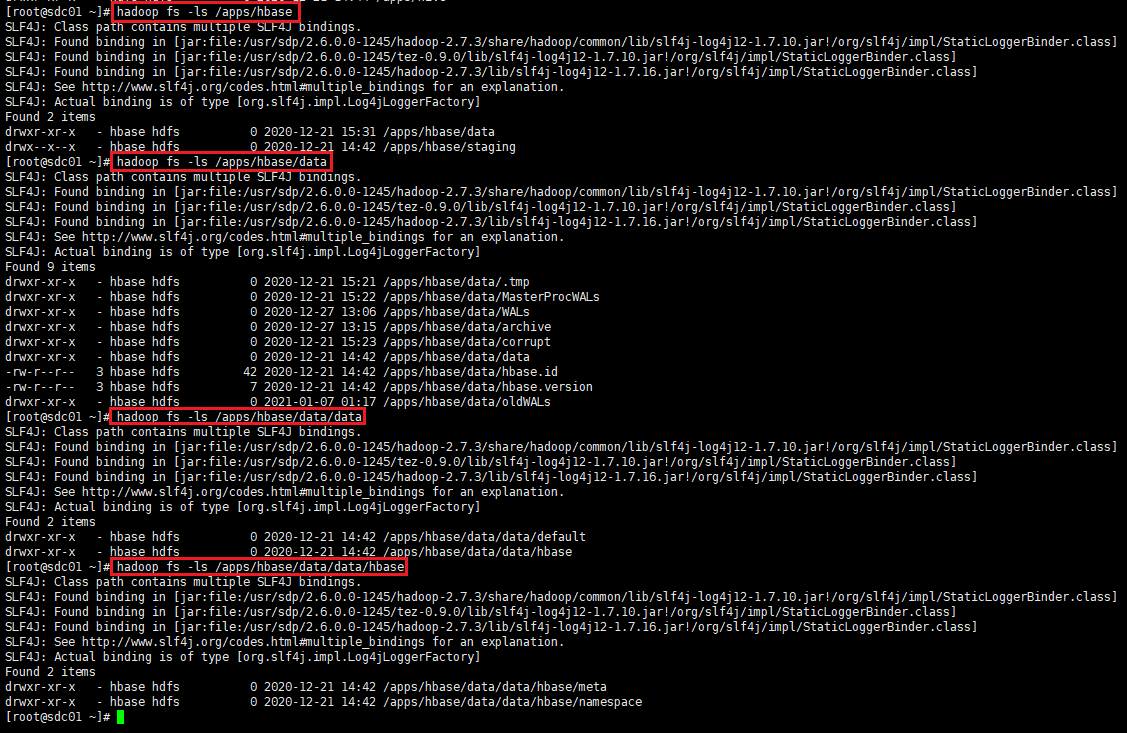
-ls(r) //显示当前目录下所有文件
# hadoop fs -ls /
# hadoop fs -ls -R /
(递归查看)
- 显示文件内容 in 终端
# hadoop fs -cat <src>
# hadoop fs -text <src>
(将文本文件或某些格式的非文本文件通过文本格式输出)
# hadoop fs -tail <hdfs file>
(在标准输出中显示文件末尾的1KB数据)
- 显示文件(目录)存储大小
# hadoop fs -du(s) <path>
//显示目录中所有文件大小
# hadoop fs -du -s <hdsf-path>
//显示hdfs对应路径下所有文件和的大小
# hadoop fs -du -h <hdsf-path>
显示hdfs对应路径下每个文件夹和文件的大小,文件的大小用方便阅读的形式表示。例如用64M代替67108864
- 显示目录中文件数量
# hadoop fs -count[-q] <path>
2 Manipulation
2.1 上传/移动/下载 [本地文件系统 ~ HDFS文件系统]
- 上传本地文件到HDFS文件系统的指定目录中
# hadoop fs -put ./local_test.txt /hdfs_test
或
#hadoop fs -copyFromLocal ./local_test.txt /hdfs_test
- 移动本地文件到HDFS文件系统的指定目录中
# hadoop fs -moveFromLocal ./local_test.txt /hdfs_test
- 下载HDFS文件系统的指定目录到本地路径下
# hadoop fs -get /hdfs_test/test.txt .
或
# hadoop fs -getToLocal /hdfs_test/test.txt .
hadoop fs -get [-ignoreCrc] //复制文件到本地,可忽略crc校验
hadoop fs -getmerge //将源目录中的所有文件排序合并到1个本地文件中。若文件不存在时会自动创建;若文件存在时会覆盖里面的内容
hadoop fs -getmerge -nl //加上-nl后,合并到local file中的hdfs文件之间会空出一行
- 移动HDFS文件系统的指定目录到本地文件中
# hadoop fs -moveToLocal <hdfs-src> <localdst>
2.2 数据操纵
- 拷贝/移动/删除 文件(夹)
# hadoop fs -cp /test/test.txt /test1
-cp <src-dir> <dst-dir>
(支持同时复制多个文件到目标目录)
# hadoop distcp hdfs://master1:8020/foo/bar hdfs://master2:8020/bar/foo
(两个haddop hdfs集群之间拷贝数据)
# hadoop fs -rm /test1/test.txt
[删除文件]
# hadoop fs -rm -r /test1/
[删除文件夹]
# hadoop fs -mv /test/test.txt /test1
-mv <src-dir> <dest-dir>
2.3 目录操纵
- 创建文件目录
# hadoop fs -mkdir /test
(在根目录创建一个目录test)
3 补充: Hive的支持
hive内亦支持 dfs 命令.
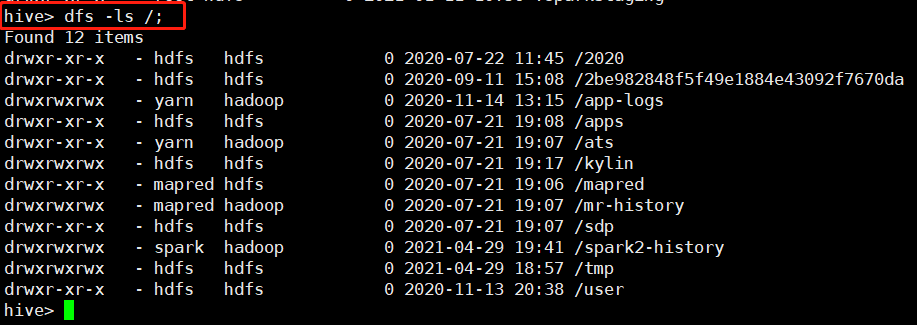
# hive> dfs -ls /;
Found 12 items
drwxr-xr-x - hdfs hdfs 0 2020-07-22 11:45 /2020
drwxr-xr-x - hdfs hdfs 0 2020-09-11 15:08 /2be982848f5f49e1884e43092f7670da
drwxrwxrwx - yarn hadoop 0 2020-11-14 13:15 /app-logs
drwxr-xr-x - hdfs hdfs 0 2020-07-21 19:08 /apps
drwxr-xr-x - yarn hadoop 0 2020-07-21 19:07 /ats
drwxrwxrwx - hdfs hdfs 0 2020-07-21 19:17 /kylin
drwxr-xr-x - mapred hdfs 0 2020-07-21 19:06 /mapred
drwxrwxrwx - mapred hadoop 0 2020-07-21 19:07 /mr-history
drwxr-xr-x - hdfs hdfs 0 2020-07-21 19:07 /sdp
drwxrwxrwx - spark hadoop 0 2021-04-29 19:41 /spark2-history
drwxrwxrwx - hdfs hdfs 0 2021-04-29 18:57 /tmp
drwxr-xr-x - hdfs hdfs 0 2020-11-13 20:38 /user
X 参考文献
- HDFS fs命令 - 博客园
- hadoop HDFS常用文件操作命令 - 博客园
- hadoop distcp使用 - CSDN
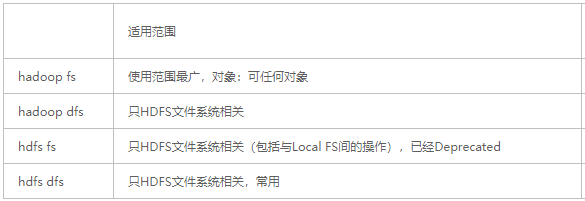
- HADOOP之HADOOP FS和HDFS DFS、HDFS FS三者区别 - 博客园
[大数据]Hadoop HDFS文件系统命令集的更多相关文章
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
- 我要进大厂之大数据Hadoop HDFS知识点(2)
01 我们一起学大数据 老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点! ...
- 大数据 - hadoop - HDFS+Zookeeper实现高可用
高可用(Hign Availability,HA) 一.概念 作用:用于解决负载均衡和故障转移(Failover)问题. 问题描述:一个NameNode挂掉,如何启动另一个NameNode.怎样让两个 ...
- 大数据Hadoop——HDFS Shell操作
一.查询目录下的文件 1.查询根目录下的文件 Hadoop fs -ls / 2.查询文件夹下的文件 Hadoop fs -ls /input 二.创建文件夹 hadoop fs -mkdir /文件 ...
- 大数据hadoop入门学习之集群环境搭建集合
目录: 1.基本工作准备 1.虚拟机准备 2.java 虚拟机-jdk环境配置 3.ssh无密码登录 2.hadoop的安装与配置 3.hbase安装与配置(集成安装zookeeper) 4.zook ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
随机推荐
- software engineering homework 1
1. 回顾你过去将近3年的学习经历 当初你报考的时候,是真正喜欢计算机这个专业吗? 你现在后悔选择了这个专业吗? 你认为你现在最喜欢的领域是什么(可以是计算机的也可以是其它领域)? 答:一开始感觉编程 ...
- 复习笔记,javadoc生成文档总结
1.处理数字时候的内存溢出问题 //在处理大数字时候注意内存溢出问题 int i=10_0000_0000; //jdk7 中数字之间可以加入下划线不影响输出 ...
- elasticsearch第一天
启动 elasticsearch -d不能用以root用户启动 外网可访问在elasticsearch.yml中添加配置http.host: 0.0.0.0network.host: 0.0.0.0d ...
- 2003031118-李伟-Python数据分析第三周作业-第一次作业
项目 NumPy数值计算基础 博客名称 2003031118-李伟-Python数据分析第三周作业-第一次作业 课程班级博客链接 https://edu.cnblogs.com/campus/pexy ...
- Java的mybatis随笔
什么是mybatis mybatis是一个优秀的持久层框架,它支持定制化 SQL.存储过程以及高级映射.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyBatis 可 ...
- vue echarts 多个图表自适应
<template> <div :id="id" :style="{width: `${width}`, height: `${height}`}&qu ...
- 在VMWare里安装Win11虚机
1. 安装win11有最低硬件要求 64位CPU双核,内存4G,硬盘64G,受信任的平台模块(TPM)2.0,支持UEFI安全启动 2. VMware新建虚机的设置 1)创建64位虚拟机,CPU设置为 ...
- 导出生成word
用XML做就很简单了.Word从2003开始支持XML格式,大致的思路是先用office2003或者2007编辑好word的样式,然后另存为xml,将xml翻译为FreeMarker模板(后缀为.ft ...
- 实验十 团队作业7:团队项目用户验收&Beta冲刺
项目 内容 课程班级博客链接 2018级卓越班 这个作业要求链接 实验十 团队名称 零基础619 团队成员分工描述 任务1:亚楠,桂婷任务2:团队合作任务3:团队合作任务4:荣娟,鑫 团队的课程学习目 ...
- 关于windows cmd 控制台输出中文
由于中文在window 输出总是优乱码可能性 ,先建cmd.reg 负责下面内容 ,双击运行即可. Windows Registry Editor Version 5.00 [HKEY_CURR ...