RDD编程
一、词频统计
1.读文本文件生成RDD lines
2.将一行一行的文本分割成单词 words flatmap()
3.全部转换为小写 lower()
4.去掉长度小于3的单词 filter()
5.去掉停用词
6.转换成键值对 map()
7.统计词频 reduceByKey()
8.按字母顺序排序 sortBy(f)
9.按词频排序 sortByKey()
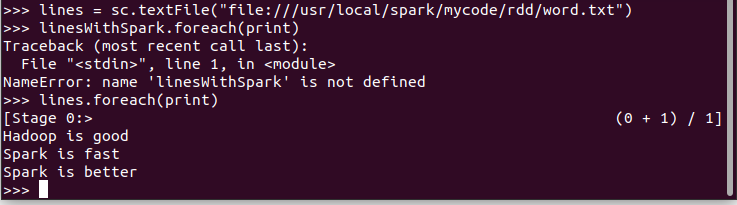
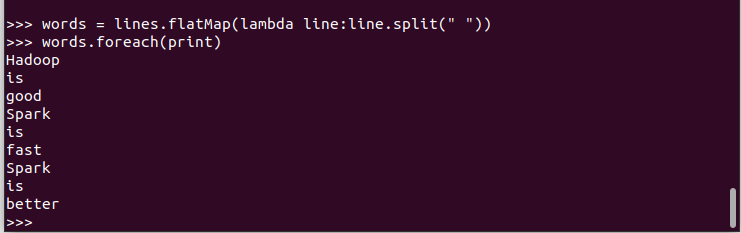



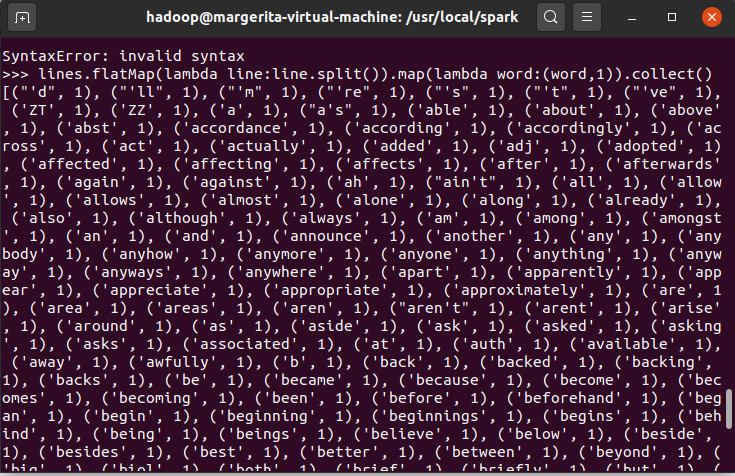
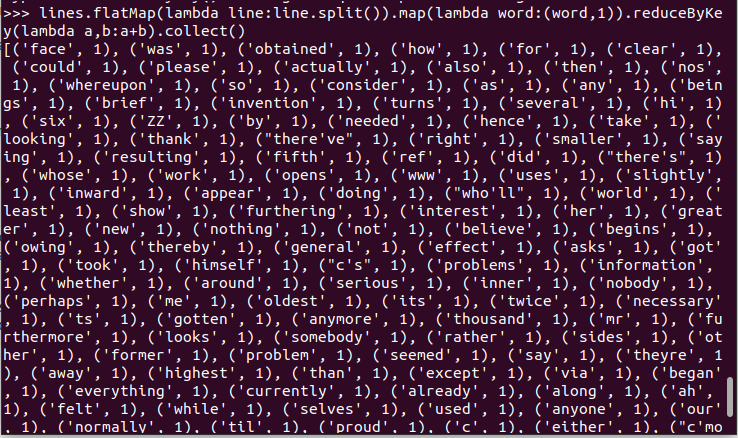


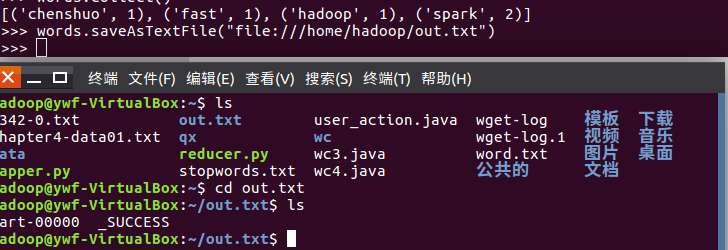
10.结果文件保存 saveAsTextFile(out_url)
words.saveAsTextFile("file:///home/hadoop/out.txt")
11.词频结果可视化charts.WordCloud()

#11.词频结果可视化charts.WordCloud()
from pyecharts.charts import WordCloud
url='D:/1342-0.txt'
with open(r'D:/stopwords.txt') as f:
stops=f.read().split()
wc=sc.textFile(url).flatMap(lambda line:line.lower().replace(',','').split()).filter(lambda word:word not in stops).filter(lambda word:len(word)>2).map(lambda word:(word,1)).reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[1],False).take(100) mywordcloud=WordCloud()
mywordcloud.add("",wc,shape='circle')
mywordcloud.render()

二、学生课程分数案例
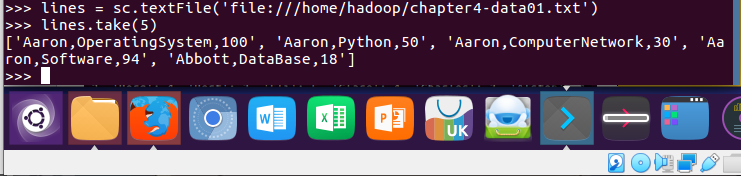
lines = sc.textFile('file:///home/hadoop/chapter4-data01.txt')
lines.take(5)
1.总共有多少学生?map(), distinct(), count()
lines.map(lambda line : line.split(',')[0]).distinct().count()

2.开设了多少门课程?
lines.map(lambda line : line.split(',')[1]).distinct().count()

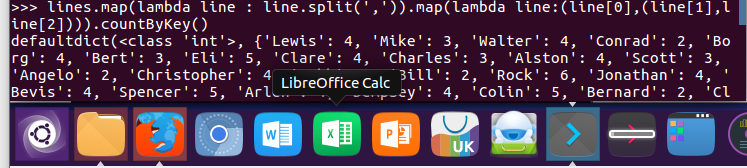
3.每个学生选修了多少门课?map(), countByKey()
lines.map(lambda line : line.split(',')).map(lambda line:(line[0],(line[1],line[2]))).countByKey()
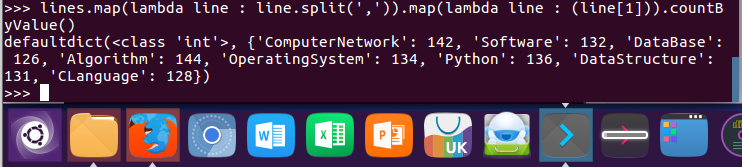
4.每门课程有多少个学生选?map(), countByValue()
lines.map(lambda line : line.split(',')).map(lambda line : (line[1])).countByValue()
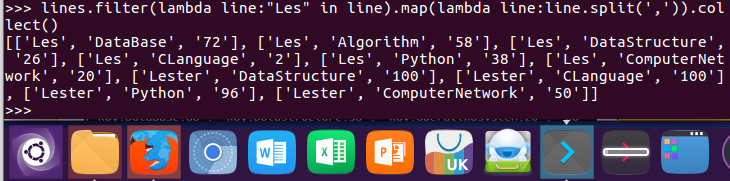
5.Les选修了几门课?每门课多少分?filter(), map() RDD
lines.filter(lambda line:"Les" in line).map(lambda line:line.split(',')).collect()
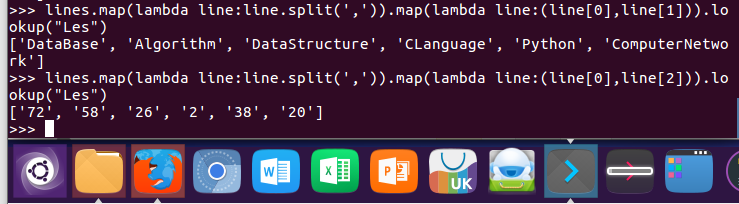
6.Les选修了几门课?每门课多少分?map(),lookup() list
lines.map(lambda line:line.split(',')).map(lambda line:(line[0],line[1])).lookup("Les")
lines.map(lambda line:line.split(',')).map(lambda line:(line[0],line[2])).lookup("Les")
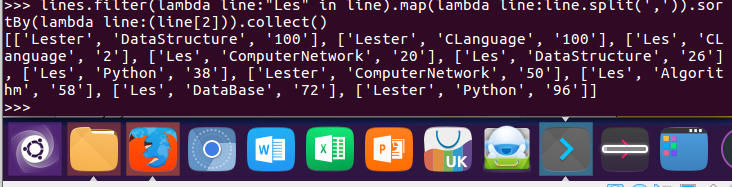
7.Les的成绩按分数大小排序。filter(), map(), sortBy()
lines.filter(lambda line:"Les" in line).map(lambda line:line.split(',')).sortBy(lambda line:(line[2])).collect()
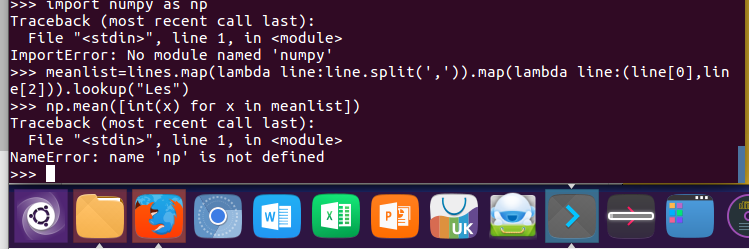
8.Les的平均分。map(),lookup(),mean()
import numpy as np
meanlist=lines.map(lambda line:line.split(',')).map(lambda line:(line[0],line[2])).lookup("Les")
np.mean([int(x) for x in meanlist])
9.生成(课程,分数)RDD,观察keys(),values()
lines = sc.textFile('file:///home/hadoop/chapter4-data01.txt')
words = lines.map(lambda line:line.split(',')).map(lambda line:(line[1],line[2]))
words.keys().take(5)
words.values().take(5)
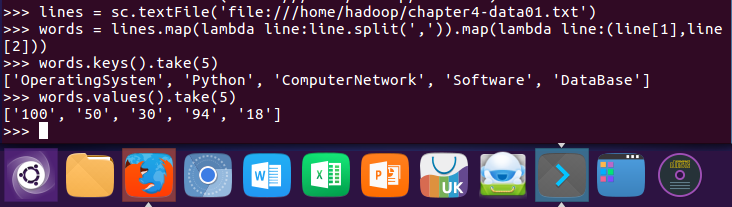
10.每个分数+5分。mapValues(func)
words.mapValues(lambda x:int(x)+5).foreach(print)
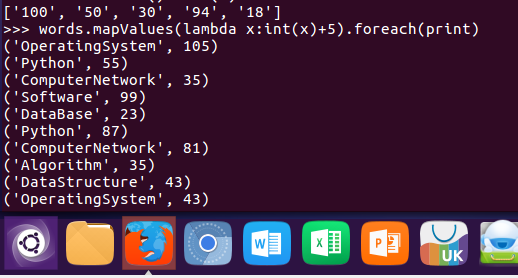
11.求每门课的选修人数及所有人的总分。combineByKey()
course = words.combineByKey(lambda v:(int(v),1),lambda c,v:(c[0]+int(v),c[1]+1),lambda c1,c2:(c1[0]+c2[0],c1[1]+c2[1]))
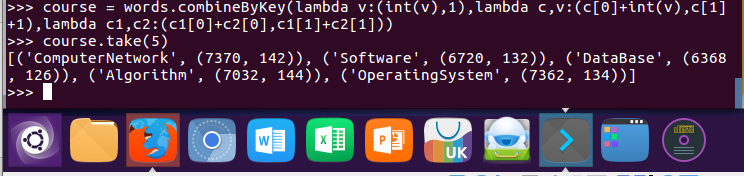
12.求每门课的选修人数及平均分,精确到2位小数。map(),round()
course.map(lambda x:(x[0],x[1][1],round(x[1][0]/x[1][1],2))).collect()
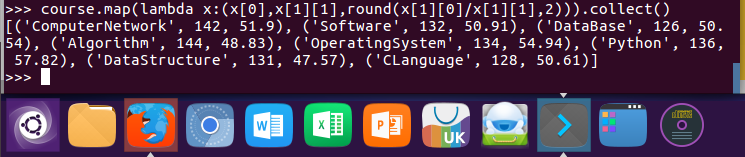
13.求每门课的选修人数及平均分。用reduceByKey()实现,并比较与combineByKey()的异同。
lines.map(lambda line:line.split(',')).map(lambda x:(x[1],(int(x[2]),1))).reduceByKey(lambda a,b:(a[0]+b[0],a[1]+b[1])).foreach(print)

14.结果可视化。charts,Bar()
from pyecharts.charts import Bar
from pyecharts import options as opts bar = Bar()
bar.add_xaxis(cs.keys().collect())
bar.add_yaxis('avg',cs.map(lambda x:x[2]).collect())
#bar.set_global_opts(title_opts=opts.TitleOpts(title="各课程",subtitle="平均分"),xaxis_opts=opts.AxisOpts(axislabel_opt=opts.LabelOpts(rotate=30)))
bar.set_global_opts() bar.render_notebook()
X轴设置斜体的方法忘记了不会写

RDD编程的更多相关文章
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
- Spark菜鸟学习营Day1 从Java到RDD编程
Spark菜鸟学习营Day1 从Java到RDD编程 菜鸟训练营主要的目标是帮助大家从零开始,初步掌握Spark程序的开发. Spark的编程模型是一步一步发展过来的,今天主要带大家走一下这段路,让我 ...
- Spark学习笔记2:RDD编程
通过一个简单的单词计数的例子来开始介绍RDD编程. import org.apache.spark.{SparkConf, SparkContext} object word { def main(a ...
- Spark编程模型(RDD编程模型)
Spark编程模型(RDD编程模型) 下图给出了rdd 编程模型,并将下例中用 到的四个算子映射到四种算子类型.spark 程序工作在两个空间中:spark rdd空间和 scala原生数据空间.在原 ...
- 02、体验Spark shell下RDD编程
02.体验Spark shell下RDD编程 1.Spark RDD介绍 RDD是Resilient Distributed Dataset,中文翻译是弹性分布式数据集.该类是Spark是核心类成员之 ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- 5.1 RDD编程
一.RDD编程基础 1.创建 spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URL作为参数,这个URL可以是: 本地文件系统的地址 分布式文件系统HDFS的地址 ...
- 2. RDD编程
2.1 编程模型 在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换.经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,act ...
- spark实验(四)--RDD编程(1)
一.实验目的 (1)熟悉 Spark 的 RDD 基本操作及键值对操作: (2)熟悉使用 RDD 编程解决实际具体问题的方法. 二.实验平台 操作系统:centos6.4 Spark 版本:1.5.0 ...
- 第2章 RDD编程(2.3)
第2章 RDD编程(2.3) 2.3 TransFormation 基本RDD Pair类型RDD (伪集合操作 交.并.补.笛卡尔积都支持) 2.3.1 map(func) 返回一个新的RDD,该 ...
随机推荐
- 【BOOK】数据存储--MongoDB
MongoDB存储 1.链接MongoDB 指定数据库 指定集合 import pymongo ## 连接数据库 client = pymongo.MongoClient( ...
- pands 编码知识
一,pandas功能 1,基于numpy , 分析结构化数据. 二,常用基础知识编码练习 包括数据类型,数据操作,比如索引,分片 ,分组聚合 ,排序 过滤等等数分常见操作代码 # coding=utf ...
- python_基础_习题集(10.25更新)
一.文件 1.利用文件充当数据库编写用户登录.注册功能 文件名称:userinfo.txt 基础要求: 用户注册功能>>>:文件内添加用户数据(用户名.密码等) 用户登录功能> ...
- andriod app更新
对于安卓用户来说,手机应用市场说满天飞可是一点都不夸张,比如小米,魅族,百度,360,机锋,应用宝等等,当我们想上线一款新版本APP时,先不说渠道打包的麻烦,单纯指上传APP到各大应用市场的工作量就已 ...
- Java-如何打包下载成.zip文件
打包下载成.zip文件 项目背景 公司使用vue + SpringBoot实现批量下载功能 今天在调试批量下载这个功能.打包成.zip文件时,在返回给前端浏览器出现报错信息: 后端报错: ERROR ...
- Codeforces Round #776 (Div
Codeforces Round #776 (Div. 3) CodeForces - 1650D Twist the Permutation 给定你数组a:1 2 3 ... n,一共有n次操作,每 ...
- mybatis_01 初运行
maven坐标 <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</ ...
- 通过Jenkins在远程服务器上执行shell脚本
1.Jenkins安装Publish over SSH插件 下载安装Publish over SSH插件 2.配置服务器相关信息 要先在jenkins所在的机器上生成秘钥.生成方式为: ssh-key ...
- jmeter分布式压测配置
首选 压力机A,压力机B,压力机C, 压力机A作为控制台 压力机B,压力机C作为分布式的测试机 压力机Aip:172.16.23.69, 压力机Bip:192.168.184.128 压力机 ...
- 生态学建模:增强回归树(BRT)预测短鳍鳗生存分布和影响因素|附代码数据
全文下载链接: http://tecdat.cn/?p=22482 最近我们被客户要求撰写关于增强回归树(BRT)的研究报告,包括一些图形和统计输出. 在本文中,在R中拟合BRT(提升回归树)模型.我 ...