HDFS的读写流程——宏观与微观
HDFS的读写流程——宏观与微观
HDFS:分布式文件系统,负责存放数据
分布式文件系统:就是将我们的数据放到多台电脑上存储。
写数据:就是将客户端上的数据上传到HDFS
宏观过程
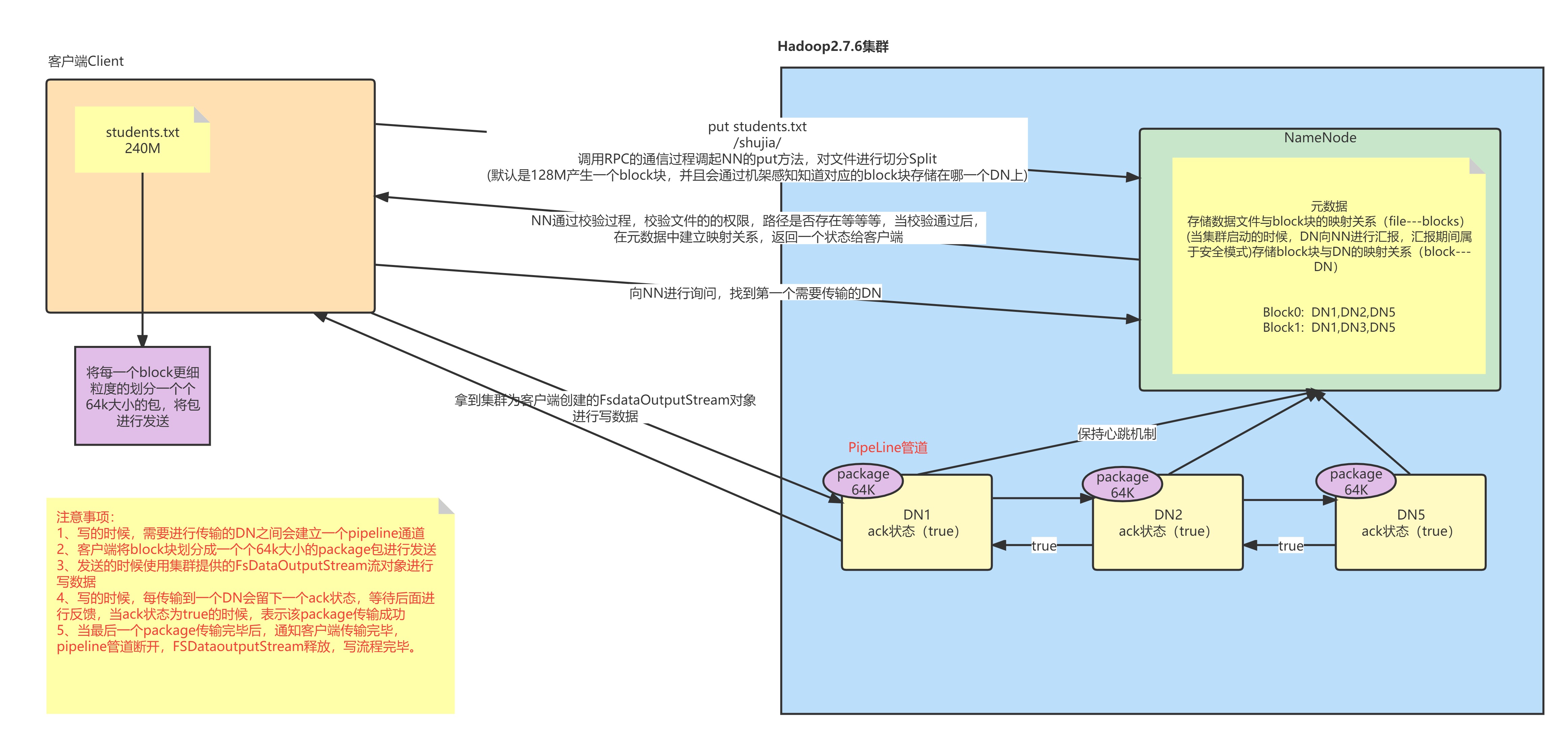
客户端向HDFS发送读写数据请求
hdfs dfs -put student.txt /shujia/ 客户端发送命令将student.txt文件上传到/shujia/目录下
Filesystem通过rpc调用namenode的put方法
- NN(NameNode)首先检查是否有足够的空间权限等条件来创建这个文件,或者这个路径是否已经存在,有权限会针对这个文件创建一个空的Entry对象,并提示返回成功状态给DFS。没有权限会直接抛出对应的异常,给与客户端错误提示信息
如果DFS接收到成功的状态,会创建一个FSDataOutputStream的对象给客户端使用
客户端要向NN询问第一个Block块存放的位置(通过机架感知策略)
需要将客户端与DN(DataNode)节点通过管道(pipeline)的方式建立连接,DN节点之间也是通过这种方式连接
客户端会按照块对文件进行切分,但是按照packet的方式来发送数据。默认一个packet的大小是64K,一个块128M就有2048个packet
客户端通过pipeline管道使用FDSOutputStream对象将数据输出
- 客户端首先将一个packet包发送给node1,同时给予node1一个ack状态
- node1接收数据后会将数据继续传递给node2,同时给与node2一个ack状态
- 同理,node2会传给node3,同时给node3一个ack状态
- node3将这个packet接收完成后会响应这个ack状态,给node2说我的状态为true。
- node2会响应node1,node2的ack状态为true。
- node1会响应客户端,node1的ack状态为true
如果客户端接收到成功的状态,说明这个packet发送成功了。客户端会一直发送,直到当前块的所有packet发完。
如果客户端接收到最后一个packet的成功状态,说明当前block块传输完成,管道就会撤销,客户端会将这个传递完成的消息给NN,然后询问NN第二个块的存放位置,依次类推。
当所有的block块传输完成后,NN在Entry中存储的所有File与Block与DN的映射关系都会关闭。
注意:客户端与要存放block块的DN节点进行连接,然后DN与它的副本节点建立管道连接。DataNode中的节点是可以相互通信的,也就是说客户端在DN1上保存block0,然后在DN4、DN6上保存这个块的副本。那么管道连接就是 客户端-->DN1-->DN4-->DN6(双向箭头,这里打不出来)
流程图
微观过程
在说微观过程之前我们要考虑两个问题:一是客户端怎么知道packet传输完毕的,二是如果在传输过程中packet丢了,例如断电怎么办。
那么如何保证packet发送的工程中不出错呢
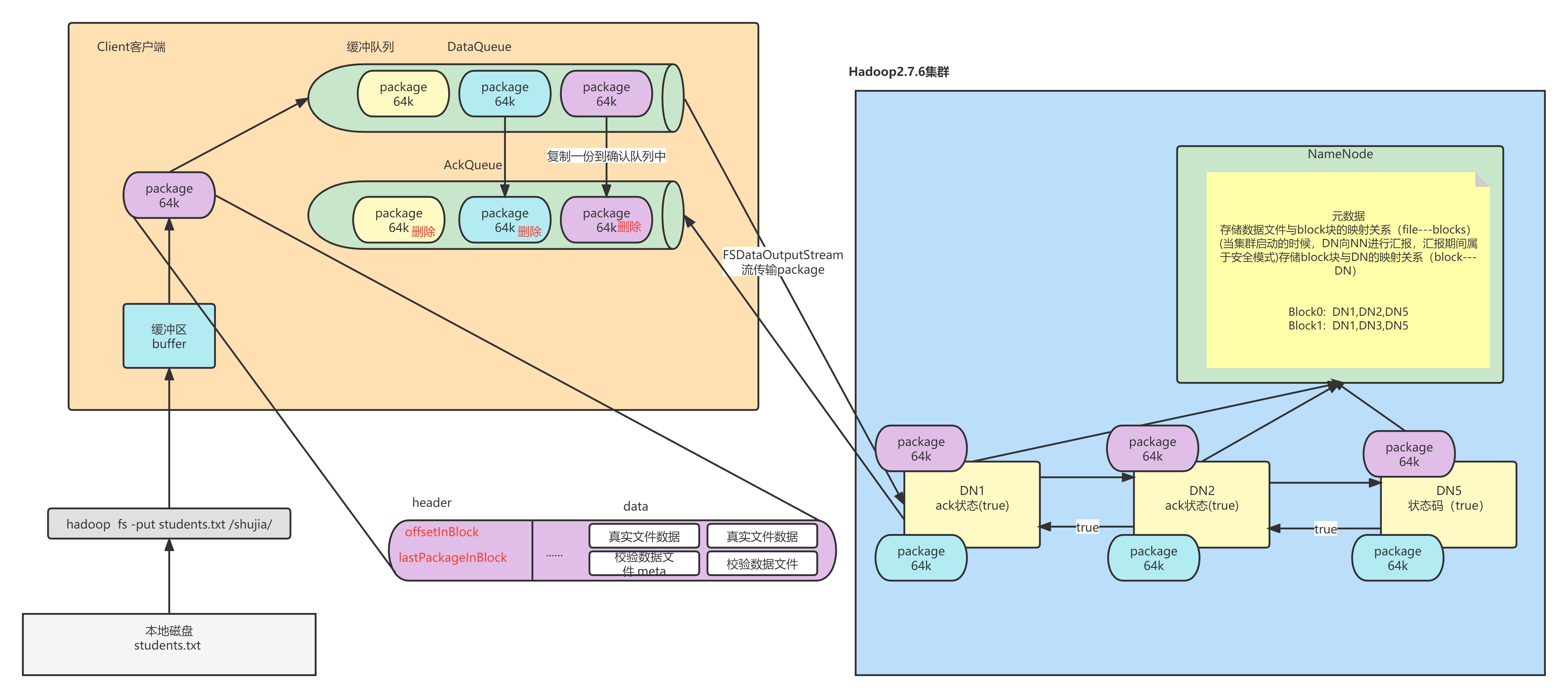
客户端首先将自己的数据以流的方式读取到缓存中
然后将缓存中的数据以chunk(512B)和checksum(4B)的方式放入到packet中(64K)
- chunk:checksum=128:1
- checksum:在数据处理和数据通信领域中,用于校验目的的一组数据项的和
- packet中的数据分为两类:一类是实际数据包,一类是header包
一个数据包的组成结构
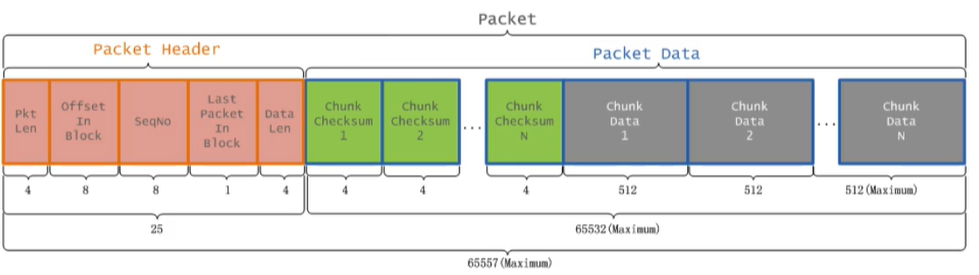
offsetInBlock:packet在block中的偏移量
LastPacketInBlock:是否是一个Block块的最后一个packet,通过这个参数就可以解决前面的第一个问题
我们生成packet的速度肯定比我们将packet发送到DN上的速度要快,那么客户端就会产生很多的packet包,这时客户端会将多余的packet放入缓冲队列DataQueue。然后调用FSDataOutputStream的对象从缓冲队列调取packet写入DN。在取出的时候会将packet复制一份放入AckQueue,这类似于另一个缓冲队列。当客户端接收到packet写入完成的信息后(ack=true)会删除AckQueue缓冲区的对应packet。这样即使断电,正在传输中的packet丢失,由于AckQueue中对应的packet没有删除,说明这个packet没有传输成功,就会重新传输这个包,这样就解决了我们前面提到的第二个问题。
读数据
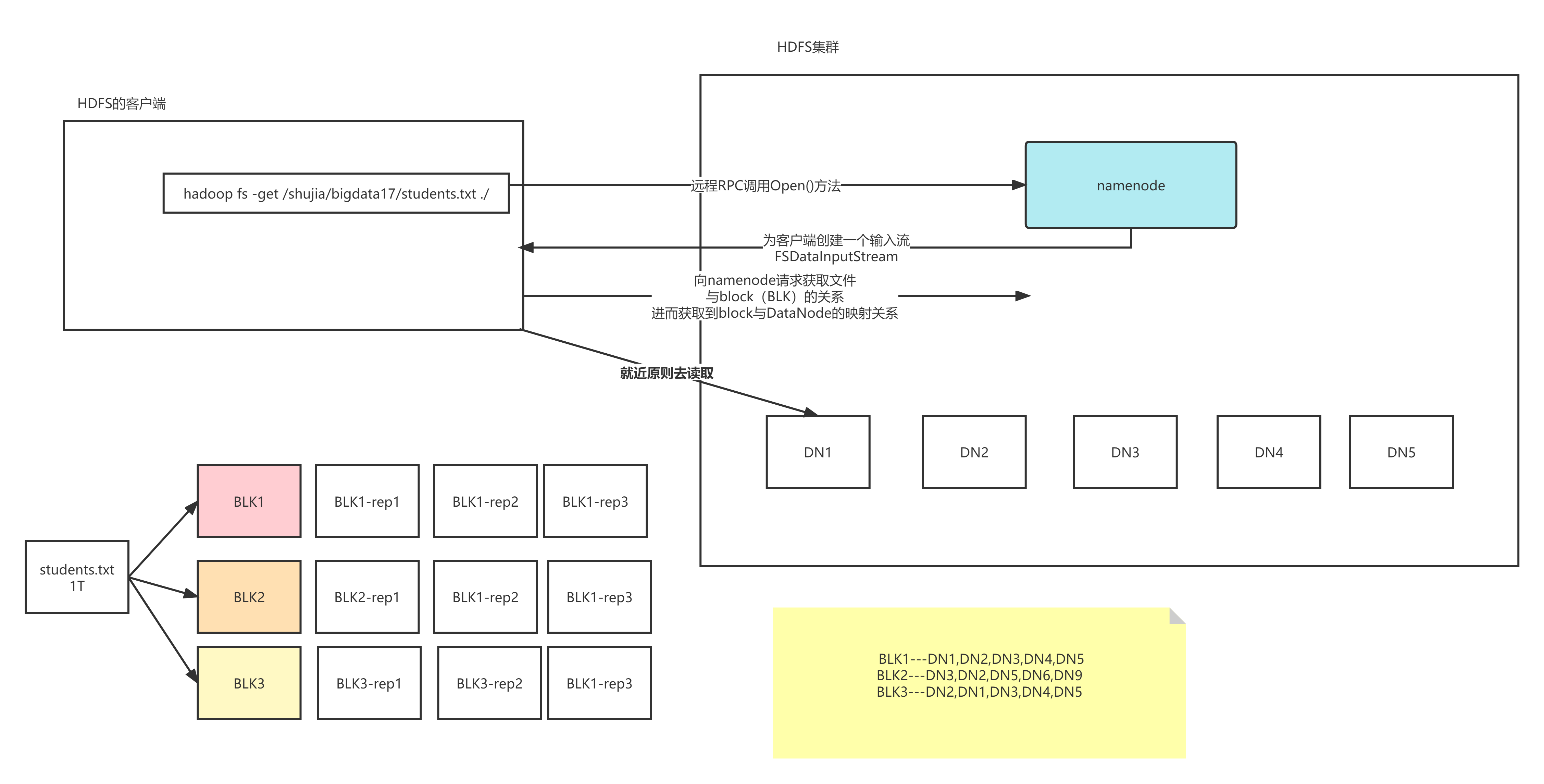
前面的都是从客户端往DN写数据,现在讨论读数据的过程
- 首先客户端发送请求到DFS,申请读某一个文件
- DFS去NN查找这个文件的元数据信息
- DFS创建FSDataInputStream对象,客户端通过这个对象读取数据
- 客户端获取文件的第一个block块信息,返回DN1 DN2 DN4
- 客户端直接就近原则选择存放块的DN1
- 依次类推其他block块的信息,知道最后一个块,将所有的block块合并成一个文件
- 关闭FSDataInputStream
流程图
HDFS的读写流程——宏观与微观的更多相关文章
- HDFS04 HDFS的读写流程
HDFS的读写流程(面试重点) 目录 HDFS的读写流程(面试重点) HDFS写数据流程 网络拓扑-节点距离计算 机架感知(副本存储节点的选择) HDFS的读数据流程 HDFS写数据流程 客服端把D: ...
- HDFS文件读写流程
一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访问.大量 ...
- 【Hadoop】二、HDFS文件读写流程
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
- HDFS文件读写流程 (转)
文件读取的过程如下: 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求: Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namen ...
- HDFS的读写流程
1.2. 客户端向NameNode发起创建文件的请求,在NameNode上创建一个文件名,并且返回一个输出流 3.客户端向输出流发起写入数据的请求 4.输出流向NameNode请求写数据,NameNo ...
- Hadoop---HDFS读写流程
Hadoop---HDFS HDFS 性能详解 HDFS 天生是为大规模数据存储与计算服务的,而对大规模数据的处理目前还有没比较稳妥的解决方案. HDFS 将将要存储的大文件进行分割,分割到既定的存储 ...
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- 【转】HDFS读写流程
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现. 特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性流式数据访问 ...
- 超详细的HDFS读写流程详解(最容易理解的方式)
HDFS采用的是master/slaves这种主从的结构模型管理数据,这种结构模型主要由四个部分组成,分别是Client(客户端).Namenode(名称节点).Datanode(数据节点)和Seco ...
随机推荐
- 竟然还有人说ArrayList是2倍扩容,今天带你手撕ArrayList源码
ArrayList是我们开发中最常用到的集合,但是很多人对它的源码并不了解,导致面试时,面试官问的稍微深入的问题,就无法作答,今天我们一起来探究一下ArrayList源码. 1. 简介 ArrayLi ...
- 判断语句、if嵌套
判断语句 上一篇我们使用了一下if语句当然我们不止这些 我们上一个只是判断出如果满足条件会执行,那么我们想一想如果不能满足该会怎么样! 当然 还有一种语句叫做if else 他的语法格式是: if ( ...
- Centos7 中安装Elasticsearch
1.下载安装包 1.1 下载elasticsearch 7.13.3 curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/e ...
- Jmeter(五十三) - 从入门到精通高级篇 - 懒人教你在Linux系统中安装Jmeter(详解教程)
1.简介 我们绝大多数使用的都是Windows操作系统,因此在Windows系统上安装JMeter已经成了家常便饭,而且安装也相对简单,但是服务器为了安全.灵活小巧,特别是前几年的勒索病毒,现在绝大多 ...
- Winforms选择文件夹、文件
更新记录: 2022年5月28日 初始记录 选择文件夹 if (this.folderBrowserDialog1.ShowDialog() == DialogResult.OK) { //获得用户选 ...
- 解决maven依赖冲突,这篇就够了!
一.前言 什么是依赖冲突 依赖冲突是指项目依赖的某一个jar包,有多个不同的版本,因而造成了包版本冲突. 依赖冲突的原因 我们在maven项目的pom中 一般会引用许许多多的dependency.例如 ...
- 面试突击60:什么情况会导致 MySQL 索引失效?
为了验证 MySQL 中哪些情况下会导致索引失效,我们可以借助 explain 执行计划来分析索引失效的具体场景. explain 使用如下,只需要在查询的 SQL 前面添加上 explain 关键字 ...
- linux系统健康检查脚本
#!/bin/bash echo "You are logged in as `whoami`"; if [ `whoami` != root ]; then echo " ...
- .NET ORM框架HiSql实战-第一章-集成HiSql
一.引言 做.Net这么多年,出现了很多很多ORM框架,比如Dapper,Sqlsugar,Freesql等等.在之前的项目中,用到的ORM框架也大多数是这几个老牌的框架. 不过最近园子关于.NET ...
- 全国土壤阳离子交换量CEC空间分布数据
数据下载链接:百度云下载链接 土壤阳离子交换量,简称CEC,是指土壤胶体所能吸附各种阳离子的总量.土壤阳离子交换量 cation exchange capacity 即CEC 是指土壤胶体所能吸附各 ...