Python数据科学手册-机器学习: 支持向量机
support vector machine SVM
是非常强大、 灵活的有监督学习算法, 可以用于分类和回归。
贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签。是属于 生成分类 方法。
判别分类:不再为每类数据建模,而是用一条分割线 或者 流形体 将各种类型分开。
原始数据:
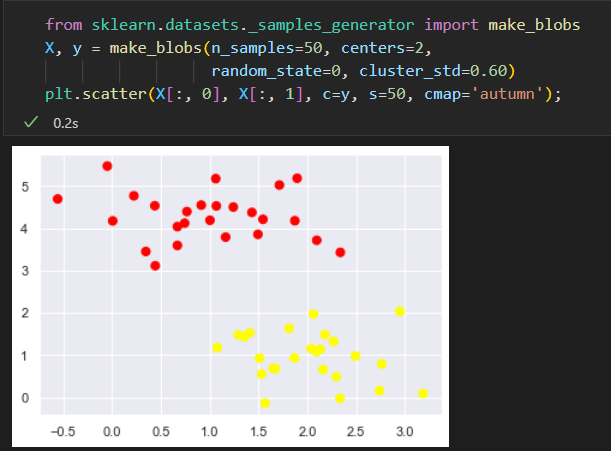
线性判别分类器 尝试 化一条 将数据 分成 俩部分的直线,这样就构成了一个分类模型。
可以发现不止一条直线可以将它们完美分割。
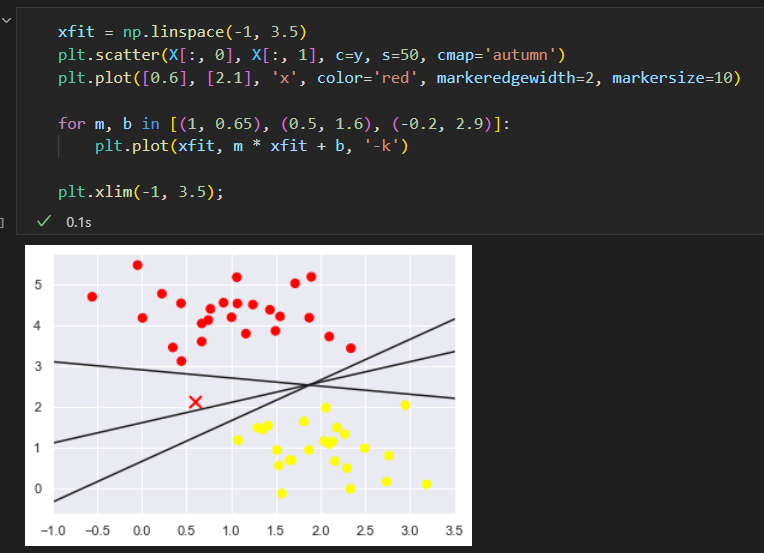
不同的分割线,会让新数据分配到不同的标签。
支持向量机:边界最大化
不是画一条细线来区分,而是画一条到最近点 边界 、有宽度 的线条。
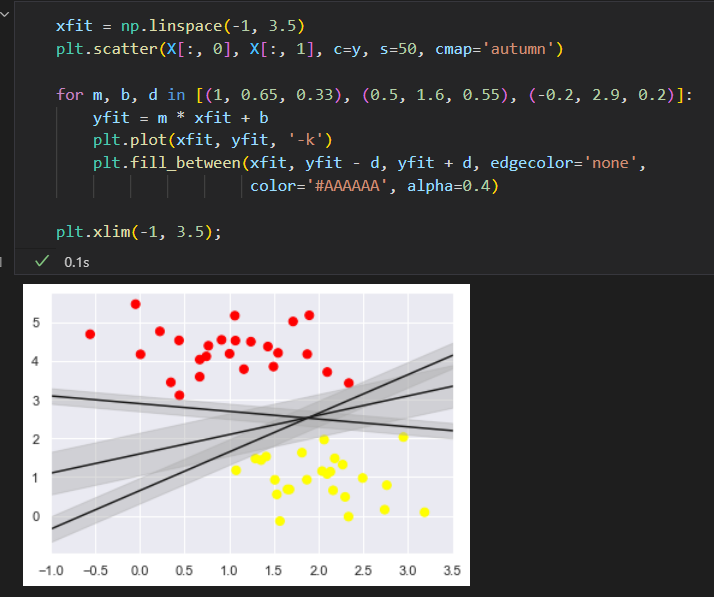
在支持向量机中,选择边界最大的那条线,是模型最优解。 边界最大化评估器。
拟合支持向量机
训练一个SVM模型,用一个线性核函数。并将参数C设置为一个很大的数。
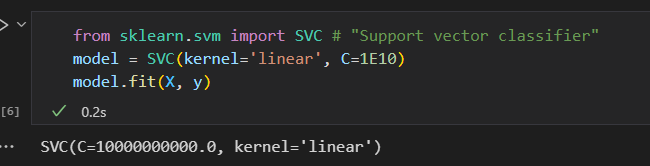
创建一个辅助函数画出SVM的决策边界。
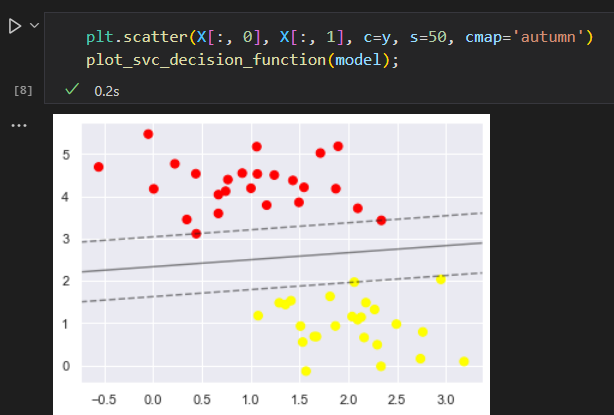
一些点正好在边界线上,这些点是拟合的关键支持点。被称为支持向量
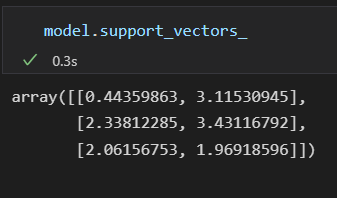
支持向量的左边存放在分类器的support_vectors_ 属性中。
说明:任何在正确分类一侧远离边界线的点都不影响拟合结果。 因为这些点不会对拟合模型的损失函数产生任何影响,只要它们没跨越边界线,位置和数量就都无关紧要。
超越线性边界:核函数 SVM模型
将SVM模型 与 核函数 组合使用。功能会非常强大。
为了应用核函数,引入一些非线性可分数据。
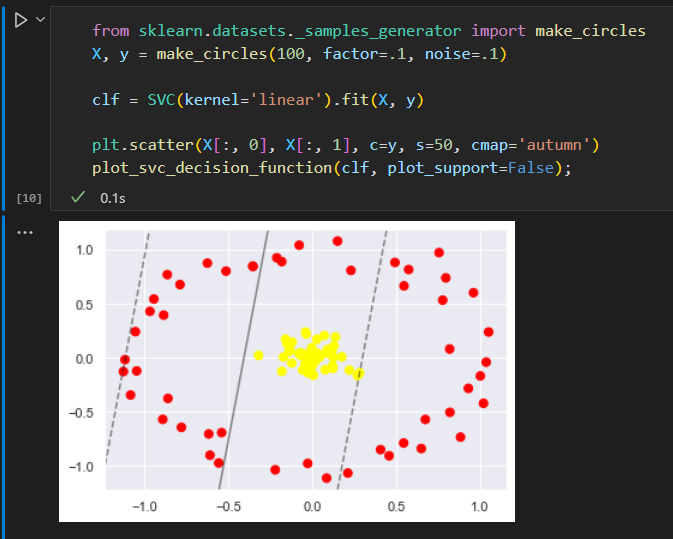
前面学到过,把数据投影到高维空间。从而使线性分割器派上用场。
一个简单的投影方法就是计算一个以 数据圆圈 为中心的径向基函数:
用三维图来可视化新增的维度
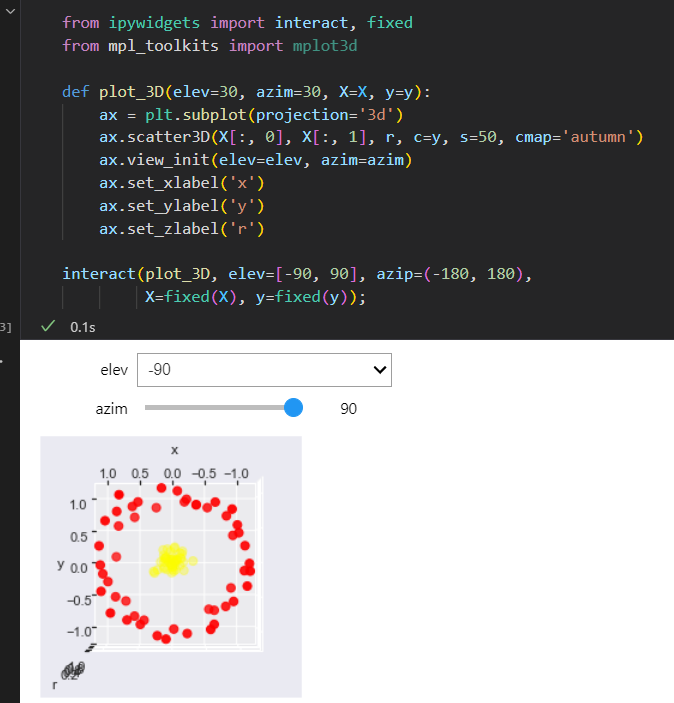
增加新的维度后,数据变成了线性可分状态,
通常选择基函数比较困难,我们需要让模型自动 指出 最合适的基函数。
一种 策略是计算基函数在数据集 上每个点的 变换结果,让SVM算法从所有结果中筛选出最优解。
这种基函数变换方式被称为 核变换
问题是:当N不断增大的时候,就会出现维度灾难。计算量巨大,
由于核函数技巧提供的小程序可以隐式计算 核变换数据的拟合。
在Scikit-Learn里面,我们可以应用核函数化的SVM模型,将线性核转变为 RBF (径向基函数)核。 设置kernel模型超参数即可。
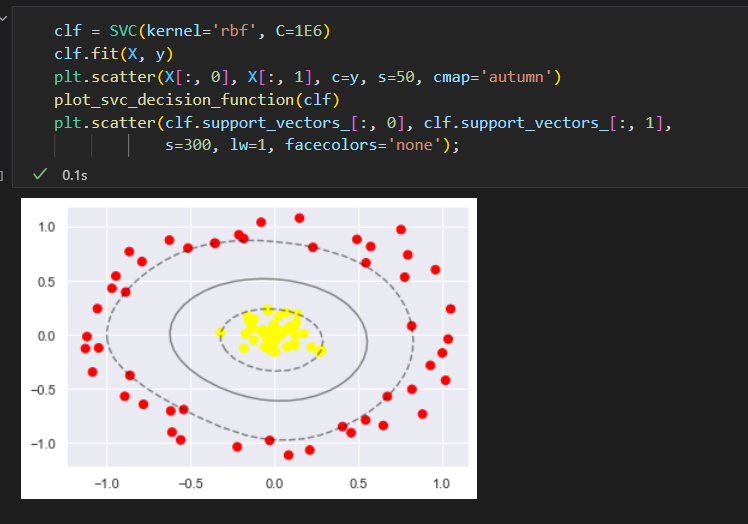
SVM优化:软化边界
如果数据有重叠,SVM实现了一些修正因子来“软化”边界,为了取得更好的拟合效果,允许一些点位于边界线之内。
边界线的硬度可以通过超参数进行控制,通常是C,
如果C很大,边界就会很硬,数据点便不能在边界内生存,
如果C比较小,边界就会较软,有一些数据点就可以穿越边界线。
案例:人脸识别
支持向量机总结
优点:
- 模型依赖的支持向量比较少,说明它们都是非常精致的模型,消耗内存少。
- 一旦模型训练完成,预测阶段速度非常快
- 由于模型只收边界线附近 的 点的影响,因此它们对于高维数据的学习效果非常好
- 与核函数方法的配合 极具通用性,能够适用不同类型的数据
缺点: - 随着样本量N的不断增加,最差的训练时间复杂度会达到O[N^3] .大样本学习的计算成本高
- 训练效果非常依赖于边界软化参数C的选择是否合理,这需要通过交叉检验自行搜索
Python数据科学手册-机器学习: 支持向量机的更多相关文章
- Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型 朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集.因为运行速度快,可调参数少.是一个快速粗糙的分类基本方案. naive Bayes classifiers 贝 ...
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
- Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis 主成分分析是一个快速灵活的数据降维无监督方法, 可视化一个包含200个数据点的二维数据集 x 和 y有线性关系,无监督学习希望探索x值 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点. 简单线性回归 将数据拟合成一条直线. y = ax + b , a 是斜率, b是直线截距 原始数据如下: 使用LinearRegr ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
- Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后.通过对训练数据进行学习.对比模型对 已知 数据的预测值和实际值 的差异. 错误的模型验证方法. 用同一套数据训练 和 评 ...
随机推荐
- org/apache/poi/POIXMLTypeLoader或者java.lang.NoSuchFieldError: RETURN_NULL_AND_BLANK
原因是之前我的poi和ooxml版本有点低, 解决方案 将两者版本提高,我是将两者的版本都提高到了3.15
- JDBC:批处理
1.批处理: 当要执行某条SQL语句很多次时.例如,批量添加数据:使用批处理的效率要高的多. 2.如何实现批处理 实践: package com.dgd.test; import java.io.Fi ...
- putchar与getchar
#include <stdio.h>#include <stdlib.h>void myputs(char*p) //此处的*号是标志,标志这P是一个指针{ if(p==NUL ...
- Identity Server 4资源拥有者密码认证控制访问API
基于上一篇文章中的代码进行继续延伸,只需要小小的改动即可,不明白的地方可以先看看本人上一篇文章及源码: Identity Server 4客户端认证控制访问API 一.QuickStartIdenti ...
- c# 添加指定扩展名的系统右键菜单(Windows11以前)
在上篇文章c# 添加系统右键菜单(Windows11以前)中我们说了怎么在文件夹上增加一个菜单项,但是我们可能还需要给某个单独的扩展名添加右键菜单. 这里我们不用常见的扩展名来做,我们新做一个.jx的 ...
- CSDN垃圾的没有底线!
平时写代码,经常需要百度. 今天我输入搜索关键词"access sql字符串转日期"进行百度搜索: 然后点开第一条: 这个加粗的标题可以点的,再点开: 这个内容跟我的搜索关键词有什 ...
- 字符编码和字符集和编码引出的问题_FileReader读取GBK格式的文件
字符编码 计算机中鵆的信息都是用二进制数表示的,而我们在屏幕上看到的数字.英文.标点符号.汉子等字符都是二进制数转换之后的结果.按照某种规则,将字符存储到计算机中,称为编码.反之,将存储在计算机中的二 ...
- Random的概述和基本使用与生成指定范围的随机数
Random类用来生成随机数字,使用起来需要三个步骤 1.导包 import java.util.Random; 2.创建 Random random = new Random();//小括号中留空即 ...
- 1000-ms-HashMap 线程安全安全问题
问题: HashMap是否是线程安全 详解 http://www.importnew.com/21396.html 有源码分析 和代码性能比较 CHM性能最好 HashMap不是线程安全的:Hasht ...
- C#中引用类型的变量做为参数在方法调用时加不加 ref 关键字的不同之处
一直以为对于引用类型做为参数在方法调用时加不加 ref 关键字是没有区别的.但是今天一调试踪了一下变量内存情况才发现大有不同. 直接上代码,结论是:以下代码是使用了 ref 关键字的版本.它输出1 ...