scrapy 之自定义命令运行所有爬虫文件
1、在spider文件夹同级目录创建commands python包
2、在包下创建command.py文件
3、从scrapy.commands包下引入ScrapyCommand
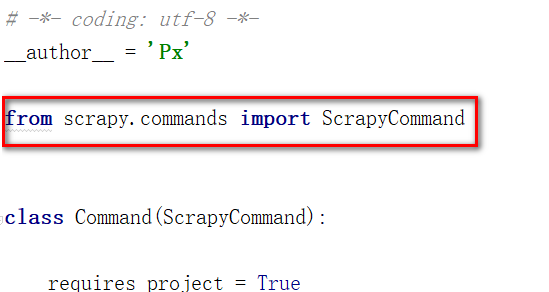
4、创建一个类,继承ScrapyCommand
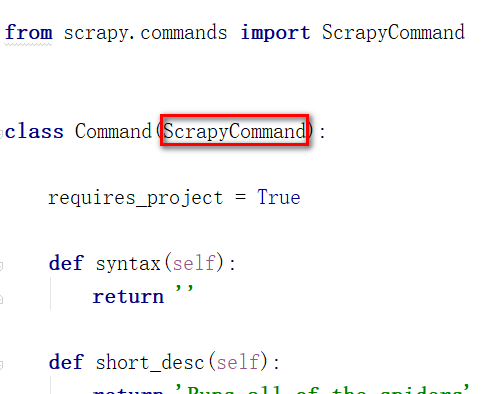
5、重新定义类变量 requires_project = True

6、重写syntax short_desc方法,syntax返回空字符串 short_desc返回描述字符串

7、重写run方法。
8、在settings.py 中添加配置 COMMANDS_MODULE = '项目名称.目录名称'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list() #通过self.crawler_process.spider.list()获得所有爬虫
for name in spider_list: #遍历所有爬虫
self.crawler_process.crawl(name, **opts.__dict__) #运行爬虫 self.crawler_process.start() #启动进程
crawler_process 来自父类 完整代码
# -*- coding: utf-8 -*-
__author__ = 'Px' from scrapy.commands import ScrapyCommand class Command(ScrapyCommand): requires_project = True def syntax(self):
return '' def short_desc(self):
return 'Runs all of the spiders' def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__) self.crawler_process.start()
scrapy 之自定义命令运行所有爬虫文件的更多相关文章
- scrapy电影天堂实战(二)创建爬虫项目
公众号原文 创建数据库 我在上一篇笔记中已经创建了数据库,具体查看<scrapy电影天堂实战(一)创建数据库>,这篇笔记创建scrapy实例,先熟悉下要用到到xpath知识 用到的xpat ...
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates: ...
- Scrapy的shell命令(转)
scrapy python MrZONT 2015年08月29日发布 ...
- scrapy框架--新建调试的main.py文件
一.原因: 由于pycharm中没有scrapy的一个模板,所有没办法直接在scrapy文件中调试,所有我们需要写一个自己的main.py文件,在文件里面调用命令行,来实现scrapy的一个调试.(在 ...
- scrapy框架的命令行解释
scrapy框架的命令解释 创建爬虫项目 scrapy startproject 项目名例子如下: scrapy startproject test1 这个时候爬虫的目录结构就已经创建完成了,目录结构 ...
- python+pytest,通过自定义命令行参数,实现浏览器兼容性跑用例
场景拓展: UI自动化可能需要指定浏览器进行测试,为了做成自定义配置浏览器,可以通过动态添加pytest的命令行参数,在执行的时候,获取命令行传入的参数,在对应的浏览器执行用例. 1.自动化用例需要支 ...
- Scrapy 框架,爬虫文件相关
Spiders 介绍 由一系列定义了一个网址或一组网址类如何被爬取的类组成 具体包括如何执行爬取任务并且如何从页面中提取结构化的数据. 简单来说就是帮助你爬取数据的地方 内部行为 #1.生成初始的Re ...
- scrapy 基础组件专题(六):自定义命令
写好自己的爬虫项目之后,可以自己定制爬虫运行的命令. 一.单爬虫 在项目的根目录下新建一个py文件,如命名为start.py,写入如下代码: from scrapy.cmdline import ex ...
随机推荐
- 存储过程中调用webservice
存储过程中调用webservice其实是在数据库中利用系统函数调用OLE. 1.查找webservice api 可得到MSSOAP.SoapClient. 2.查找API 接口可得到mssoapin ...
- 2018-2019-2 20175227张雪莹《Java程序设计》实验三 《敏捷开发与XP实践》
2018-2019-2 20175227张雪莹<Java程序设计> 实验三 <敏捷开发与XP实践> 实验报告封面 课程:Java程序设计 班级:1752班 姓名:张雪莹 学号: ...
- dialog学习
11.dialog底部弹出动画: ==== 11.dialog底部弹出动画: 点击Button调用代码 private void show() { Dialog dialog = new Dialog ...
- 知识点:Mysql 数据库索引优化实战(4)
知识点:Mysql 索引原理完全手册(1) 知识点:Mysql 索引原理完全手册(2) 知识点:Mysql 索引优化实战(3) 知识点:Mysql 数据库索引优化实战(4) 一:插入订单 业务逻辑:插 ...
- winform里面的Form1.Designer.cs
Program.cs是程序入口,也就是Main函数.Form1.cs是实现功能的代码,包括你的自定义方法和事件.Form1.Designer.cs是你的画面的设计代码,一般由系统自动生成,也可以手动修 ...
- GitHub提供服务简介
|GitHub-Funcation| |Git仓库| 一般情况下,我们可以免费建立任意个GitHub提供的Git仓库.但需要私有仓库则需要最低每月支付$7. |Organization| 这 ...
- 搭建zookeeper+kafka集群
搭建zookeeper+kafka集群 一.环境及准备 集群环境: 软件版本: 部署前操作: 关闭防火墙,关闭selinux(生产环境按需关闭或打开) 同步服务器时间,选择公网ntpd服务器或 ...
- 使用requests+BeautifulSoup爬取龙族V小说
这几天想看龙族最新版本,但是搜索半天发现 没有网站提供 下载, 我又只想下载后离线阅读(写代码已经很费眼睛了).无奈只有自己 爬取了. 这里记录一下,以后想看时,直接运行脚本 下载小说. 这里是从 ...
- Java ---- 遍历链表(递归与非递归实现)
package test; //前序遍历的递归实现与非递归实现 import java.util.Stack; public class Test { public static void main( ...
- Anatomy of a Database System学习笔记 - 查询
查询解析 解析会生成一个查询的内部展示.格式检查包含在解析过程中. 每次解析一个SELECT,步骤如下:1. 从FROM里找到表名,转换成schema.tablename.这一步需要调用目录管理器ca ...