大数据之路week07--day06 (Sqoop 将关系数据库(oracle、mysql、postgresql等)数据与hadoop数据进行转换的工具)
为了方便后面的学习,在学习Hive的过程中先学习一个工具,那就是Sqoop,你会往后机会发现sqoop是我们在学习大数据框架的最简单的框架了。
版本:(两个版本完全不兼容,sqoop1使用最多)
sqoop1:1.4.x
sqoop2:1.99.x
同类产品
DataX:阿里顶级数据交换工具
注意,这里的导入和导出是相对于Hadoop来说的 !!!!!
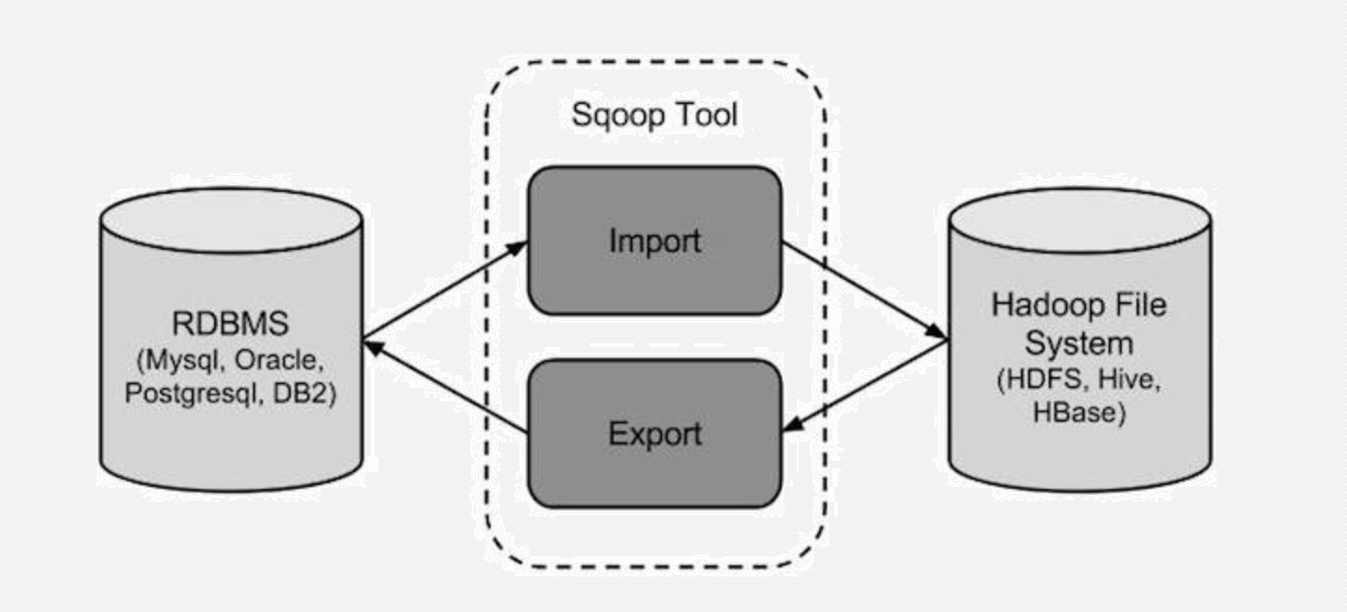

数据导入到Hadoop中的HDFS中:

把HDFS中的数据导出来到关系数据库中去:

大数据之路week07--day06 (Sqoop 将关系数据库(oracle、mysql、postgresql等)数据与hadoop数据进行转换的工具)的更多相关文章
- 大数据之路week07--day06 (Sqoop 的使用)
Sqoop的使用一(将数据库中的表数据上传到HDFS) 首先我们先准备数据 1.没有主键的数据(下面介绍有主键和没有主键的使用区别) -- MySQL dump 10.13 Distrib 5.1.7 ...
- 大数据之路week07--day07 (Sqoop 从mysql增量导入到HDFS)
我们之前导入的都是全量导入,一次性全部导入,但是实际开发并不是这样,例如web端进行用户注册,mysql就增加了一条数据,但是HDFS中的数据并没有进行更新,但是又再全部导入一次又完全没有必要. 所以 ...
- 大数据之路week07--day06 (Sqoop 的安装及配置)
Sqoop 的安装配置比较简单. 提供安装需要的安装包和连接mysql的驱动的百度云链接: 链接:https://pan.baidu.com/s/1pdFj0u2lZVFasgoSyhz-yQ 提取码 ...
- 大数据之路week07--day06 (Sqoop 在从HDFS中导出到关系型数据库时的一些问题)
问题一: 在上传过程中遇到这种问题: ERROR tool.ExportTool: Encountered IOException running export job: java.io.IOExce ...
- 配置ogg从Oracle到PostgreSQL的同步复制json数据
标签:goldengate postgresql oracle json 测试环境说明 Oracle:Windows 8.1 + Oracle 12.2.0.1.0 + GoldenGate 12.3 ...
- 大数据框架开发基础之Sqoop(1) 入门
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle , ...
- 使用Sqoop从mysql向hdfs或者hive导入数据时出现的一些错误
1.原表没有设置主键,出现错误提示: ERROR tool.ImportTool: Error during import: No primary key could be found for tab ...
- Sqoop的使用(Mysql To HBase)
最近需要将mysql的数据整合到HBase中,原本使用MapReduce,自己制作job将mysql的数据导入, 查阅资料过程中,发现了开源工具sqoop(关系性数据库与HDFS,HBASE,HIVE ...
- 胖子哥的大数据之路(11)-我看Intel&&Cloudera的合作
一.引言 5月8日,作为受邀嘉宾,参加了Intel与Cloudera在北京中国大饭店新闻发布会,两家公司宣布战略合作,该消息成为继Intel宣布放弃大数据平台之后的另外一个热点新闻.对于Intel的放 ...
随机推荐
- 微设计基础架构(MDI)
微设计基础架构(MDI) 了解微设计基础架构(MDI)的概念,它们如何帮助开发,以及它们与DevOps和微服务等技术的关系. 技术决策既困难又严肃,可以决定项目的成败.如何找到合适的技术栈?“微设计基 ...
- LeetCode 686. 重复叠加字符串匹配(Repeated String Match)
686. 重复叠加字符串匹配 686. Repeated String Match 题目描述 给定两个字符串 A 和 B,寻找重复叠加字符串 A 的最小次数,使得字符串 B 成为叠加后的字符串 A 的 ...
- 通过命令窗口导入导出oracle数据库到dmp文件
通过命令窗口导入导出oracle数据库到dmp文件 很多时候我们需要备份Oracle的数据库,然后将数据导入其他数据库,因为有大文本字段会导致insert无法完全导出,只能导出为dmp文件,前提是wi ...
- UML概念模型
UML概念模型 UML(Unified Modeling Language):统一建模语言,为面向对象开发系统的产品进行说明.可视化.和编制文档的标准语言 面向对象程序设计 面向对象基本概念:对象.类 ...
- 44 容器(三)——ArrayList索引相关方法
方法都比较简单,这里列出来即可: add(index,ele) //忘制定下标插入元素 add(ele) addAll(Collection <C> c) 泛型必须与调用add的泛型保持一 ...
- 【HC89S003F4开发板】 10汇编指令
HC89S003F4开发板汇编指令 一.数据传递类指令 MOV.MOVC.MOVX 1.MOV,用于片内数据存储器中的数据传递指令中. 2.MOVC是与ROM之间的数据传送,而MOVX是与外部RAM数 ...
- Linux 进程间通信(管道、共享内存、消息队列、信号量)
进程通信 : 不同进程之间传播或交换信息 为什么要进程通信呢? 协同运行,项目模块化 通信原理 : 给多个进程提供一个都能访问到的缓冲区. 根据使用场景,我们能划分为以下几种通信 ...
- 【LEETCODE】48、867. Transpose Matrix
package y2019.Algorithm.array; /** * @ProjectName: cutter-point * @Package: y2019.Algorithm.array * ...
- (六) Docker 部署 Redis 高可用集群 (sentinel 哨兵模式)
参考并感谢 官方文档 https://hub.docker.com/_/redis GitHub https://github.com/antirez/redis happyJared https:/ ...
- python实现scp功能
最近公司有一个需求,需要把服务器A上的任务放到服务器B上,因为B上有HTTP,并且可以被外网访问,但是直接通过shell的scp,每次都需要输入密码.这里用python简单实现一下 直接上代码: im ...