3. 键值对RDD
键值对RDD是Spark中许多操作所需要的常见数据类型。除了在基础RDD类中定义的操作之外,Spark为包含键值对类型的RDD提供了一些专有的操作在PairRDDFunctions专门进行了定义。这些RDD被称为pairRDD
有很多中方式创建pairRDD,一般如果从一个普通的RDD转为pairRDD时,可以调用map()函数来实现,传递的函数需要返回键值对
val pairs = lines.map(x => (x.split(" ")(0), x))

3.1 键值对RDD的转化操作
3.1.1 转化操作列表
针对一个pairRDD的转化操作
pairRDD的转化操作(以键值对集合{(1,2),(3,4),(3,6)}为例)

针对两个pairRDD的转化操作(rdd = {(1,2),(3,4),(3,6)} other = {(3,9)})


3.1.2 聚合操作
当数据集以键值对形式组织的时候,聚合具有相同键的元素进行一些统计是很常见的操作。之前写过基础RDD上的fold(), combine(), reduce()等行动操作,pairRDD上则有相应的针对键的转化操作。Spark有一组类似的操作,可以组合具有相同键的值。这些操作返回RDD,因此它们是转化操作而不是行动操作
reduceByKey()与reduce()相当类似;它们都接收一个函数,并使用该函数对值进行合并。reduceByKey()会为数据集中的每个键进行并行的归约操作,每个归约操作都会将键相同的值合并起来。因为数据集中可能有大量的键,所以reduceByKey()没有被实现为向用户程序返回一个值的行动操作,实际上,它会返回一个由各键和对应键归约出来的结果值组成的新的RDD
foldByKey()则与fold()相当类似;它们都使用一个与RDD和合并函数中的数据类型相同的零值作为初始值。与fold()一样,foldByKey()操作所使用的合并函数对零值与另一个元素进行合并,结果仍为该元素
求均值操作:版本一
input.mapValues(x => (x, 1)).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map{ case (key, value) => (key, value._1 / value._2.toFloat) }
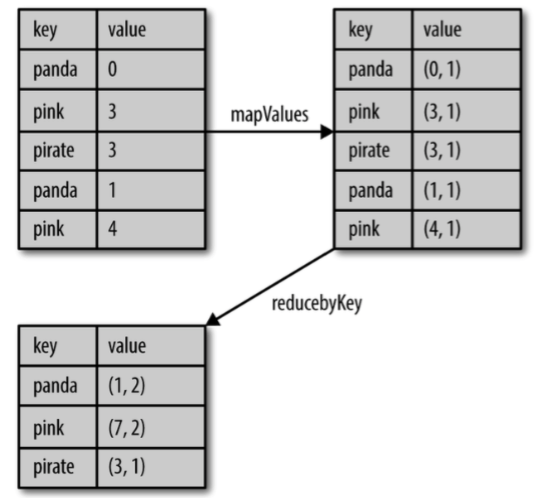
combineByKey()是最为常用的基于键进行聚合的函数。大多数基于键聚合的函数都是用它实现的。和aggregate()一样,combineByKey()可以让用户返回与输入数据的类型不同的返回值
要理解combineByKey(),要先理解它在处理数据时是如何处理每个元素的。由于combineByKey()会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同
如果这是一个新的元素,combineByKey()会使用一个叫作createCombiner()的函数来创建那个键对应的累加器的初始值。需要注意的是,这一过程会在每个分区中第一次出现各个键时发生,而不是在整个RDD中第一次出现一个键时发生
如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并
由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()方法将各个分区的结果进行合并
求均值:版本二

3.1.3 数据分组
如果数据已经以预期的方式提取了键,groupByKey()就会使用RDD中的键来对数据进行分组。对于一个由类型K的键和类型V的值组成的RDD,所得到的结果RDD类型会是[K, Iterable[V]]
groupBy()可以用于未成对的数据上,也可以根据除键相同以外的条件进行分组。它可以接收一个函数,对源RDD中的每个元素使用该函数,将返回结果作为键再进行分组
多个RDD分组,可以使用cogroup函数,cogroup()函数对多个共享同一个键的RDD进行分组。对两个键的类型均为K值的类型分别为V和W的RDD进行cogroup()时,得到的结果RDD类型为[(k, (Iterable[V], Iterable[W]))]。如果其中的一个RDD对于另一个中存在的某个键没有对应的记录,那么对应的迭代器则为空。cogroup()提供了为多个RDD进行数据分组的方法
3.1.4 连接
连接主要用于多个PairRDD的操作,连接方式多种多样:右外连接、左外连接、交叉连接以及内连接
普通的join操作符表示内连接,只有在两个pairRDD中都存在的键才叫输出。当一个输入对应的某个键有多个值时,生成的pairRDD会包括来自两个输入RDD的每一组相对应的纪录
leftOuterJoin()产生的pairRDD中,源RDD的每一个键都有对应的纪录。每个键相应的值是由一个源RDD中的值与一个包含第二个RDD的值的Option(在Java中为Optional)对象组成的二元组
rightOuterJoin()完全一样,只不过预期结果中的键必须出现在第二个RDD中,而二元组中的可缺失的部分则来自于源RDD而非第二个RDD
3.1.5 数据排序
sortByKey()函数接收一个叫作ascending的参数,表示我们是否想要让结果按升序排序(默认值为true)
3.2 键值对RDD的行动操作
pairRDD的行动操作(以键值对集合{(1,2),(3,4),(3,6)}为例)

3.3 键值对RDD的数据分区
Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle过程属于哪个分区和Reduce的个数
注意:
(1) 只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None
(2) 每个RDD的分区ID范围:0~numPartitions-1,决定这个值是属于哪个分区的
3.3.1 获取RDD的分区方式
可以通过使用RDD的partitioner属性来获取RDD的分区方式。它会返回一个scala.Option对象,通过get方法获取其中的值
3.3.2 Hash分区方式
HashPartitioner分区的原理:对于给定的key,计算其hashCode,并除于分区的个数取余,如果余数小于0,则用余数+分区的个数,最后返回的值就是这个key所属的分区ID

3.3.3 Range分区方式
HashPartitioner分区弊端:可能导致,每个分区中数据量的不均匀,极端情况下会导致某些分区拥有RDD的全部数据
RangePartitioner分区优势:尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的。一个分区中的元素肯定都是比另一个分区内的元素小或者大
但是分区内的元素是不能保证顺序的。简单来说就是将一定范围内的数映射到某一个分区内
RangePartitioner作用:将一定范围内的数映射到某一个分区内,在实现中,分界的算法尤为重要。用到了水塘抽样算法
3.3.4 自定义分区方式
要实现自定义的分区器,需要继承org.apache.spark.Partitioner类并实现下面三个方法
numPartitions: Int:返回创建出来的分区数
getPartition(key: Any): Int:返回给定键的分区编号(0到numPartitions-1)
equals(): Java 判断相等性的标准方法。这个方法的实现非常重要,Spark需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样Spark才可以判断两个RDD的分区方式是否相同
假设我们需要将相同后缀的数据写入相同的文件,我们通过将相同后缀的数据分区到相同的分区并保存输出来实现
使用自定义的Partitioner是很容易的:只要把它传给partitionBy()方法即可。Spark中有许多依赖于数据混洗的方法,比如join()和groupByKey(),它们也可以接收一个可选的Partitioner对象来控制输出数据的分区方式
3.3.5 分区Shuffle优化
在分布式程序中,通信的代价是很大的,因此控制数据分布式以获得最少的网络传输可以极大地提升整体性能。
Spark中所有的键值对RDD都可以进行分区。系统会根据一个针对键的函数对元素进行分组。主要有哈希分区和范围分区,当然用户也可以自定义分区函数。
通过分区可以有效提升程序性能。如下例子:
有这样一个应用,它在内存中保存着一张很大的用户信息表-也就是一个由(UserID, UserInfo)对组成的RDD,其中UserInfo包含一个该用户所订阅的主题的列表。该应用会周期性的将这张表与一个小文件进行组合,这个小文件中存着过去五分钟内发生的事件-其实就是一个由(UserID, LinkInfo)对组成的表,存放着过去五分钟内某网站各用户的访问情况。例如我们可能需要对用户访问其未订阅主题的页面的情况进行统计
解决方案一:

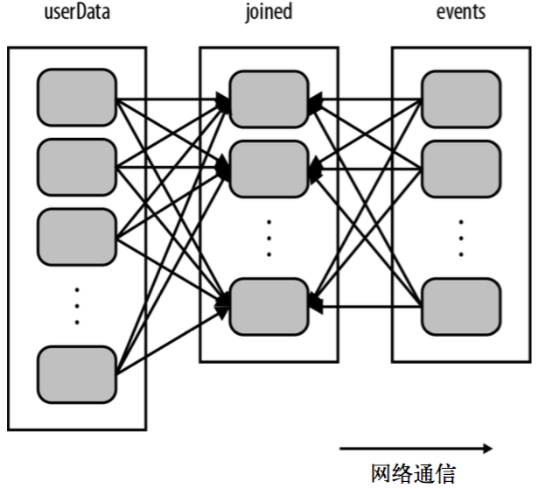
这段代码可以正常运行,但是不够高效。这是因为在每次调用processNewLogs()时都会用到join()操作,而我们对数据集是如何区分的却一无所知。默认情况下,连接操作会将两个数据集中的所有键的哈希值都求出来,将该哈希值相同的纪录通过网络传到同一台机器上,然后在那台机器上对所有键相同的纪录进行连接操作。因为userData表比每五分钟出现的访问日志表events要大的多,所以要浪费时间做很多额外工作:在每次带调用时都对userData表进行哈希值计算和跨节点数据混洗,降低了程序的执行效率。
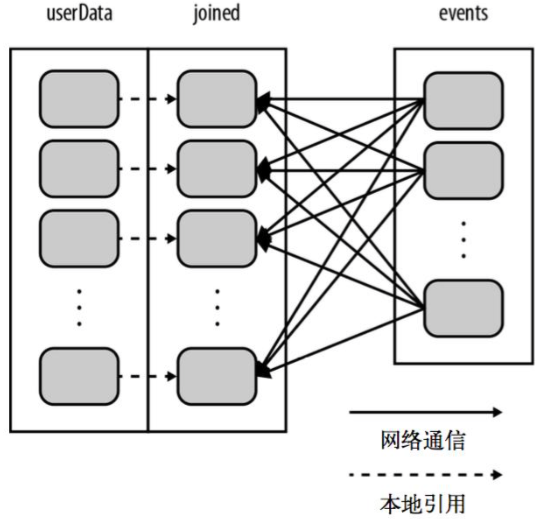
优化方法:

在构建userData时调用了partitionBy(),Spark就知道了该RDD是根据键的哈希值来分区的,这样在调用join()时,Spark就会利用到这一点。具体来说,当调用userData.join(events)时,Spark只会对events进行数据混洗操作,将events中特定UserID的纪录发送到userData的对应分区所在的那台机器上。这样,需要通过网络传输的数据就大大减少了,程序运行速度也可以显著提升了
3.3.6 基于分区进行操作
基于分区对数据进行操作可以让我们避免为每个数据元素进行重复的配置工作。诸如打开数据库连接或创建随机数生成器等操作,都是我们应当尽量避免为每个元素都配置一次的工作。Spark提供基于分区的mapPartition和foreachPartition,让我们的部分代码只对RDD的每个分区运行一次,这样可以帮助降低这些操作的代价
3.3.7 从分区中获益的操作
能够从数据分区中获得性能提升的操作有cogroup()、groupWith()、join()、leftOuterJoin()、rightOuterJoin()、groupByKey()、reduceByKey()、combineByKey()以及lookup()等
3. 键值对RDD的更多相关文章
- Spark 键值对RDD操作
键值对的RDD操作与基本RDD操作一样,只是操作的元素由基本类型改为二元组. 概述 键值对RDD是Spark操作中最常用的RDD,它是很多程序的构成要素,因为他们提供了并行操作各个键或跨界点重新进行数 ...
- 5.2 RDD编程---键值对RDD
一.键值对RDD的创建 1.从文件中加载 2.通过并行集合(数组)创建RDD 二.常用的键值对RDD转换操作 1.reduceByKey(func) 功能:使用func函数合并具有相同键的值 2.gr ...
- Learning Spark 第四章——键值对处理
本章主要介绍Spark如何处理键值对.K-V RDDs通常用于聚集操作,使用相同的key聚集或者对不同的RDD进行聚集.部分情况下,需要将spark中的数据记录转换为键值对然后进行聚集处理.我们也会对 ...
- Spark中的键值对操作-scala
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- Spark中的键值对操作
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- Spark学习之键值对操作总结
键值对 RDD 是 Spark 中许多操作所需要的常见数据类型.键值对 RDD 通常用来进行聚合计算.我们一般要先通过一些初始 ETL(抽取.转化.装载)操作来将数据转化为键值对形式.键值对 RDD ...
- 【Spark 深入学习 07】RDD编程之旅基础篇03-键值对RDD
--------------------- 本节内容: · 键值对RDD出现背景 · 键值对RDD转化操作实例 · 键值对RDD行动操作实例 · 键值对RDD数据分区 · 参考资料 --------- ...
- Spark学习笔记——键值对操作
键值对 RDD是 Spark 中许多操作所需要的常见数据类型 键值对 RDD 通常用来进行聚合计算.我们一般要先通过一些初始 ETL(抽取.转化.装载)操作来将数据转化为键值对形式. Spark 为包 ...
- Spark学习笔记3:键值对操作
键值对RDD通常用来进行聚合计算,Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为pair RDD.pair RDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口. S ...
随机推荐
- 记录一次SpringBoot实现AOP编程
需求 最近碰到一个问题,需要对关键操作的入参和返回值进行记录,并不是使用log记录,而是插入到数据库中. 思路:如果采用硬编码,在每个操作后都添加,会产生大量重复代码.因而打算使用自定义注解,通过AO ...
- fluent计算输出时均值
/ ****************************************************************************** * Created on : 2017 ...
- Symfony之入门学习
最近因业务需要,主要针对Edusoho进行二次开发.但是对于Symfony,我并不熟悉,我所了解的是,它的那套与我在Java中常用的开发模式MVC,本质上并不多大差异,就是所使用的语言不一样而已.下面 ...
- 原生js实现浏览器全屏和退出全屏
全屏模式 //W3C if (docElm.requestFullscreen) { docElm.requestFullscreen(); } //FireFox else if (docElm.m ...
- Deep High-Resolution Representation Learning for Human Pose Estimation
Deep High-Resolution Representation Learning for Human Pose Estimation 2019-08-30 22:05:59 Paper: CV ...
- On-line fusion of trackers for single-object tracking
On-line fusion of trackers for single-object tracking Pattern Recognition, 2018 - Elsevier 2019-08-1 ...
- MySQL事务隔离级别(一)
本文实验的测试环境:Windows 10+cmd+MySQL5.6.36+InnoDB 一.事务的基本要素(ACID) 1.原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做 ...
- 数据库sql优化总结之3--SQL优化总结
SQL是每个Java程序员必回的一项技能, 对于项目中的各种复杂业务, 你是否能写出高效率, 简洁的SQL对于项目的运行效率和稳定性是有非常大的作用的. 通过个人的理解和网上的资料总结了一下常见的S ...
- windows正常,linux报错:'PHPExcel_Reader_excel2007' not found
原因:因为在linux下,大小写敏感 我的文件夹命名是大写,在window小写可以访问到,但是在linux就大小写敏感导致没找到文件没导入成功 导入文件的路径(错误)import('phpexcel. ...
- jdbc调用存储过程获取多个结果集
jdbc调用存储过程获取多个结果集 2017年07月26日 21:20:22 Kenny-Liu 阅读数:1486 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.cs ...