看MindSpore加持下,如何「炼出」首个千亿参数中文预训练语言模型?
摘要:千亿参数量的中文大规模预训练语言模型时代到来。
本文分享自华为云社区《 MindSpore开源框架加持,如何「炼出」首个千亿参数、TB级内存的中文预训练语言模型?》,原文作者:chengxiaoli。
千亿参数量的中文大规模预训练语言模型时代到来。
近段时间,中文大规模预训练语言模型圈有些热闹。26 亿参数量的「悟道 · 文源」, 270 亿参数量的 PLUG,以及昨天华为云发布的千亿级别「盘古」NLP 大模型,预训练语言模型已经成长到仅加载就需要 TB 级的内存或显存。
我们可以直观地想到,「盘古」效果理应更好,但计算量需求也更大,训练起来更困难。
然而「盘古」实际上是这样一次探索:开源框架 MindSpore,昇腾基础软硬件平台,加上超大规模中文预训练模型,意味着基础设施已然完善了。
这项工作由华为以及北京大学相关技术团队联手完成,在昇腾基础软硬件平台,以及 MindSpore 框架自动并行等黑科技的帮助下,训练出当前最大的中文预训练模型。
那么量级不断拔高的盘古大模型是如何训练出来的?接下来,让我们细致解读下「盘古」背后的关键技术。
千亿参数,TB 级内存的模型
以盘古 2000 亿为例,如果我们训练时权重都用标准的 FP32 数据格式,那么算下来,权重占的空间就达到了 750GB,训练过程中内存开销还会数倍上升。这 750GB 参数,不是放在硬盘上,也不是加载到内存中,而是需要移到昇腾Atlas训练服务器 HBM(High Bandwidth Memory 高带宽存储器)内存中,以利用昇腾Atlas训练服务器训练模型。
模型大 ,意味着数据也大,而且都需要是高质量数据。为了满足数据需求,研发团队从互联网爬取了 80 TB 文本,并最后清洗为 1TB 的中文数据集。
这样的模型与数据,已经不是我们几台服务器能加载上的了,更不用说进行训练。好在研发团队会提供 API,一般算法工程师直接调用接口就能试试效果。
可以说,目前盘古是业界首创的千亿规模中文预训练模型,其中最高参数量达 2000 亿。
超大规模自动并行,算法工程师的福音
先考虑一个问题,你想到如何训练这样的大模型了吗?
如果给你足够的计算力,你能想到如何训练这么大的模型吗?我们最常用的分布式训练方式数据并行,单独这么做肯定是不行的,因为没有哪个计算硬件能放下 800GB 的参数。那么再加上模型并行呢?又产生了新问题,我们该如何拆分如此巨大的「盘古」?硬件产品(如 NPU、GPU 等)之间的梯度流、数据流通信又是什么样的?
显然训练如此庞大的模型,远比我们想象中的复杂,需要大量的工程化操作,并保证这些操作不会或极少影响到模型最终收敛效果。
难道盘古真得靠手动并行优化?
如果手动来写分布式训练逻辑,那么需要综合考虑计算量与类型、集群带宽、拓扑结构、样本数量等等一大堆复杂的东西,然后再设计出性能比较优秀的并行切分策略,并编写大量并行切分和节点间的通信代码。如果系统环境变了,还要重新设计并修改算法,想想就觉得头大。
倘若我们用 TensorFlow 或其他类似框架,MirroredStrategy 这一系列自带的分布式策略完全用不上,看起来自行写并行策略是必不可少的。然而,盘古 真正的训练是一种软硬件协同的方式,MindSpore 计算框架、CANN 异构计算架构、昇腾基础软硬件平台整套基础设施。其中,MindSpore 提供的,就包含了至关重要的自动并行能力。
融合 5 大维度,强大的自动并行
MindSpore 自动并行提供了 5 维的并行方式:数据并行、算子级模型并行、Pipeline 模型并行、优化器模型并行和重计算,并且在图编译阶段,有机融合了 5 个维度的并行。这 5 维并行方式组合起来构成了盘古的并行策略。

a. 数据并行
数据并行是最基本,应用最广的并行方式,其将训练数据(mini-batch)切分,每台设备取得其中一份;每台设备拥有完整的模型。在训练时,每台设备经过梯度计算后,需要经过设备间的梯度同步,然后才能进行模型参数的更新。
b. 算子级模型并行
算子级模型并行是对模型网络中的每个算子涉及到的张量进行切分。MindSpore 对每个算子都独立建模,每个算子可以拥有不同的切分策略。
以矩阵乘算子 MatMul(x, w)为例,x 是训练数据,w 是模型参数,两者都是二维矩阵。并行策略 ((4, 1), (1, 1)) 表示将 x 按行切 4 份,保持 w 不切,如果一共有 4 台设备,那么每台设备拥有一份 x 的切片,和完整的 w。
c.Pipeline 模型并行
Pipeline 模型并行将模型的按层分成多个 stage,再把各个 sage 映射到多台设备上。为了提高设备资源的利用率,又将 mini-batch 划分成多个 micro-batch, 这样就能够使得不同设备在同一时刻处理不同 micro-batch 的数据。
一种 Pipeline 并行方式(Gpipe) 要求反向计算要等所有设备的正向计算完成后才开始,而反向计算可能依赖于正向的输出,导致每个卡正向计算过程中累积的 activation 内存与 micro-batch 数量成正比,从而限制了 micro-batch 的数量。MindSpore 的 Pipeline 并行中,将反向提前,每个 micro-batch 计算完成后,就开始计算反向,有效降低 activation 存储时间,从而提升整体并行效率。

d. 优化器模型并行
优化器模型并行将优化器涉及到的参数和梯度切分到多台设备上。以 Adam 优化器为例,其内部可能有多份与权重同等大小的「动量」需要参与计算。在数据并行的情况下,每个卡都拥有完整的「动量」,它们在每个卡上都重复计算,造成了内存及计算的浪费。通过引入优化器并行,每个卡只保存权重及「动量」的切片,能降低每个卡的静态内存及提升计算效率。

e. 重计算
重计算 (Rematerialization) 针对正向算子的输出累计保存在内存中,导致内存峰值过大的问题,舍弃了部分正向算子的输出,而是在反向阶段用到时再重新计算一遍。这样做有效地降低了训练过程中的内存使用峰值。如下图所示,第一个内存峰值通过重计算消除,第二个内存峰值可以通过前面讲到的优化器并行消除。
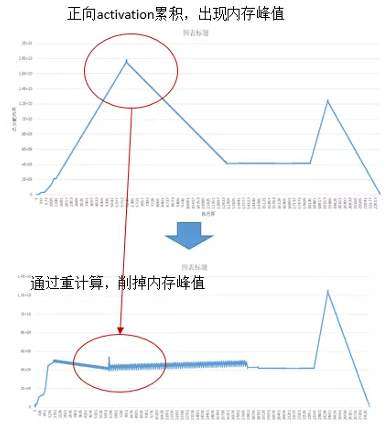
有了这 5 维的并行维度后,如何将其组合起来作用于盘古,并且如何将切分后的模型分片分配到每台设备上仍然是难题。MindSpore 自动并行,把这 5 个维度并行有机组合起来,可以实现非常高效的大模型分布式训练能力。
下图 (b) 是一典型的树形的硬件拓扑结构,其带宽随着树深度的增加而降低,并且会产生一些流量冲突。为了利用此特征,MindSpore 的目标是最大化计算通信比,将通信量大的并行方式(算子级并行)放置在服务器内部的多卡之间;将通信量较小(Pipeline 并行)的放置在同一机架内的服务器间;将数据并行(优化器并行)的部分放置在不同机架间,因为该通信可以和计算同时执行(overlap),对带宽要求较低。

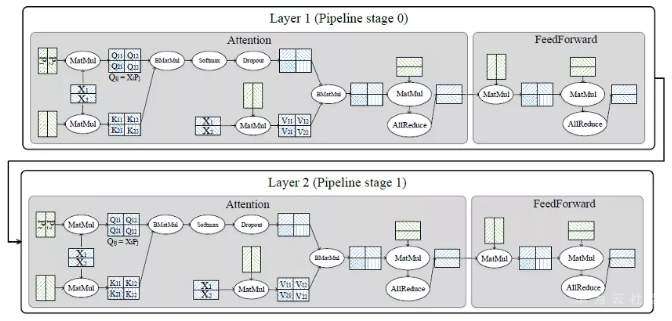
在盘古 2000 亿模型中,MindSpore 将 64 层(layer)划分为 16 个 stage,每个 stage 包含 4 层。在每层中,利用算子级并行的方式对张量进行切分。
如下图中的 Q,K,V 的参数在实际中(按列)被切了 8 份,输入张量(按行)被切了 16 份,输出张量因此被切了 128 份(8*16)。重计算配置是配置在每层内的,也就是重计算引入的多余的计算量不会超过一层的计算量。总计,MindSpore 使用了 2048 块昇腾处理器来训练盘古。
MindSpore 对外屏蔽了复杂并行实现的细节,使得用户像编写单机模型脚本那样简单。用户在单机脚本的基础上,仅通过少了配置就能实现多维度的混合并行。下图是简化版的盘古脚本,其中红色加粗字体表示的在 MindSpore 中的并行策略。将红色加粗字体去掉,则是单机脚本。

图算跨层联合优化,发挥硬件极致性能
除了跨节点间的大规模自动外,在单卡节点内,MindSpore 通过图层和算子层的跨层协同优化,来进一步发挥昇腾算力。
在传统的 NN 网络中,不同算子承载的计算量和计算复杂度也各不相同。如 LayerNorm 由 11 个基本算子组成,而 Add 则只有 1 个基本算子。这种基于用户角度的算子定义,通常是无法充分发挥硬件资源计算能力的。因为计算量过大、过复杂的算子,通常很难生成切分较好的高性能算子。从而降低设备利用率;而计算量过小的算子,由于计算无法有效隐藏数据搬移开销,也可能会造成计算的空等时延,从而降低设备利用率。
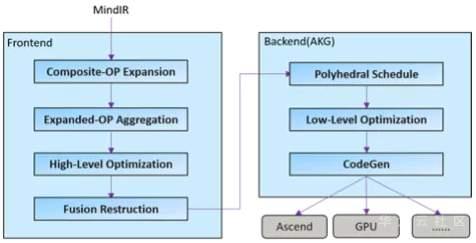
为了提升硬件利用率,MindSpore 使用了图算融合优化技术,通过图层和算子层联合优化,并将「用户使用角度的易用性算子」进行重组融合,然后转换为「硬件执行角度的高性能算子」,从而充分提升硬件资源利用率,进而提升整网执行性能。具体优化流程如下图所示:
以 LayerNorm 算子为例,通过算子拆分和重组,11 个小算子,组成了 1 个单算子和 2 个融合算子。这些重组后的算子可以生成更加高性能的算子,从而大大降低了整体网络运行时间。

在盘古模型中,图算融合帮助整体训练时间减少了 20% 以上。除此之外,对于其它 NLP、CV 等任务,图算融合在优化性能方面都有不错的表现。
总结:训练超大模型的完美体现
即使给我们足够的算力,超大模型的训练还是异常复杂,远比想象中的困难。对于我们一般算法工程师来说,针对某个任务,上亿参数量已经算大的了,但是并不会感到训练上会有什么困难,因为各个深度学习框架直接调用数据并行接口就能搞定。
但是如果模型继续增大到百亿级、千亿级甚至万亿级,并行与优化策略的复杂度猛然上升,算法工程师一点点地编写与优化代码可太难了。MindSpore 通过自动并行,把计算逻辑和并行逻辑解耦,单卡串行代码自动实现分布式并行,从而使得算法科学家将精力都解放到模型本身上。
为了从预训练获取更多的知识, GPT-3 与盘古这样的模型会越来越大,毕竟到现在我们还没看到大模型预训练效果的极限在哪。届时,这类模型对基础设施的需求会更大,并行与优化策略也会更加复杂。只有拥有足够优秀的基础设施,大规模预训练的效果才会更好,从而在知识问答、知识检索、知识推理、阅读理解等场景发挥更大作用,实现智慧客服、营销、文案生成等商业价值。
大规模计算集群及软硬件协同优化,这次在盘古的训练上得到了充分的完美体现。正如开发团队所言,「基于 Mindspore 和昇腾基础软硬件平台在千亿参数模型上的实践也是一次探索,大模型的分布式训练、超参调优、数据集组成、模型结构适应性等都存在太多的未知。现在,盘古模型效果很好,刷新了 clue 版第一,这意味着第一次基于国内软硬件协同优化,以及超大规模分布式训练,结果是令人振奋的,我们自己也具有了足够强的基础设施。」
当然,也诚如以上所言,盘古只是对超大规模分布式训练、超大规模中文预训练模型的一次探索,未来还需要更多的研究工作者投入到通用智能与大规模分布式计算的研究工作中。
看MindSpore加持下,如何「炼出」首个千亿参数中文预训练语言模型?的更多相关文章
- 巧用 .NET 中的「合并运算符」获得 URL 中的参数
获取 URL 中的 GET 参数,无论用什么语言开发网站,几乎是必须会用到的代码.但获取 URL 参数经常需要注意一点就是要先判断是否有这个参数存在,如果存在则取出,如果不存在则用另一个值.这个运算称 ...
- 解决 VS Code「Code Runner」插件运行 python 时的中文乱码问题
描述 这里整理了两种 VS Code「Code Runner」插件运行 python 时乱码的解决方案.至于设置「Auto Guess Encoding」为 true 的操作这里就不多描述了. 乱码截 ...
- NLP领域的ImageNet时代到来:词嵌入「已死」,语言模型当立
http://3g.163.com/all/article/DM995J240511AQHO.html 选自the Gradient 作者:Sebastian Ruder 机器之心编译 计算机视觉领域 ...
- ERNIE:知识图谱结合BERT才是「有文化」的语言模型
自然语言表征模型最近受到非常多的关注,很多研究者将其视为 NLP 最重要的研究方向之一.例如在大规模语料库上预训练的 BERT,它可以从纯文本中很好地捕捉丰富的语义模式,经过微调后可以持续改善不同 N ...
- Windows 10 如何使用「系统还原」功能备份系统状态和配置
https://www.sysgeek.cn/windows-10-system-restore/ 在 Windows 10 系统中,「系统还原」功能旨在创建配置快照,并在检测到系统更改时将其工作状态 ...
- Linux 小知识翻译 - 「路径设置」
这次聊聊路径的使用,这里的路径是「命令搜索路径」的简称. 在Linux上执行命令的时候,本来是需要命令的所在位置的绝对路径的,就像「/usr/bin/passwd」这样. 但是,对于经常使用的命令,如 ...
- 「C语言」Windows+EclipseCDT下的C语言开发环境准备
之前写过一篇 「C语言」在Windows平台搭建C语言开发环境的多种方式 ,讨论了如何在Windows下用DEV C++.EclipseCDT.VisualStudio.Sublime Test.Cl ...
- 快成物流科技 x mPaaS | 小程序容器加持下的技术架构“提质增效”
导言 从 2017 年开始,GMTC"移动技术大会"就更名为"大前端技术大会".发展至今,混合开发.原生开发.前端开发等概念正在深度融合,组成"大 ...
- B 站崩了,总结下「高可用」和「异地多活」
你好,我是悟空. 一.背景 不用想象一种异常场景了,这就真实发生了:B 站晚上 11 点突然挂了,网站主页直接报 404. 手机 APP 端数据加载不出来. 23:30 分,B 站做了降级页面,将 4 ...
- 如何对抗 WhatsApp「蓝色双勾」-- 3 个方法让你偷偷看讯息
WhatsApp 强制推出新功能「蓝色双勾 (✔✔)」 ,让对方知道你已经看过讯息.一众用户反应极大,因为以后不能再藉口说未看到讯息而不回覆.究竟以后 WhatsApp 是否真的「更难用」? 幸好还有 ...
随机推荐
- sql优化的方法总结
1.对查询进行优化,应该尽量避免全表扫描,首先应考虑在where和order by涉及的列上建立索引 2.应尽量避免在where子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表 ...
- 如何使用DALL-E 3
如何使用 DALL-E 3:OpenAI 图像生成指南 DALL-E 3 是 OpenAI 图像生成器的高级版本,它可以理解自然语言提示来创建详细图像. 它克服了以前版本的方形图像限制,现在支持各种宽 ...
- Windows没有足够信息,不能验证该证书",是因为该证书的颁发者
Windows没有足够信息,不能验证该证书",无法验证该证书的颁发者 解决方案之一: 1.win+R:打开运行 2.输入 gpedit.msc,确定,打开组策略 3.选择:计算机配置---管 ...
- 04-23: dataclasses使用方法
vehicle_seeds: List[int] = dataclasses.field(default_factory=list) dataclasses 模块提供了一种简洁的方式来定义Python ...
- 高精度加法(C语言实现)
高精度加法(C语言实现) 介绍 众所周知,整数在C和C++中以int ,long,long long三种不同大小的数据存储,数据大小最大可达2^64,但是在实际使用中,我们仍不可避免的会遇到爆long ...
- Ubuntu 20.04 开启局域网唤醒(WoL)
打开主板相关设置 创建 systemd 自启动设置文件 vim /etc/systemd/system/wol@.service 放入以下内容: [Unit] Description=Wake-on- ...
- ArmSoM-W3应用开发之安装docker
1. 简介 RK3588从入门到精通系列专题 开发板:ArmSoM-W3 Kernel:5.10.160 OS:Debian11 本⽂介绍ArmSoM-W3在Debian11下如何安装使用docker ...
- 文心一言 VS 讯飞星火 VS chatgpt (142)-- 算法导论12.1 2题
二.用go语言,二叉搜索树性质与最小堆性质(见 6.1 节)之间有什么不同?能使用最小堆性质在 O(n)时间内按序输出一棵有 n 个结点树的关键字吗?可以的话,请说明如何做,否则解释理由. 文心一言: ...
- json数组根据某属性去重
数据: let arry = [ {name: "张三", age: 23, work: '计算机'}, {name: "王五", age: 29, work: ...
- 数据可视化工具 ,不会写 SQL 代码也能做数据分析
数据可视化工具可以帮助人们以直观.易于理解的方式展现和分析数据.这些工具使得即使不会写 SQL 代码的人也能进行数据分析,并从中获得有价值的信息和见解. 本文将详细介绍几种常用的数据可视化工具及其功能 ...