语音识别端到端模型解读:FSMN及其变体模型
摘要:在很长一段时间内,语音识别领域最常用的模型是GMM-HMM。但近年来随着深度学习的发展,出现了越来越多基于神经网络的语音识别模型。
一、概述
在很长一段时间内,语音识别领域最常用的模型是GMM-HMM。但近年来随着深度学习的发展,出现了越来越多基于神经网络的语音识别模型。在各种神经网络类型中,RNN因其能捕捉序列数据的前后依赖信息而在声学模型中被广泛采用。用得最多的RNN模型包括LSTM、GRU等。但RNN在每一个时刻的计算都需要上一个时刻的输出作为输入,因此只能串行计算,速度很慢。
除此之外,相比于FNN等网络结构,RNN的训练易受梯度消失的影响,收敛得更慢,且需要更多的计算资源。前馈序列记忆神经网络(Feedforward Sequential Memory Networks, FSMN)[1][2]的提出,就是为了既能保留RNN对序列前后依赖关系的建模能力,又能加快模型的计算速度,降低计算复杂度。而之后提出的cFSMN[3]、DFSMN[4]和Pyramidal FSMN[5],都是在FSMN的基础上,进一步做出了改进和优化。FSMN、cFSMN和DFSMN都是中科大张仕良博士的工作,Pyramidal FSMN则是云从科技在2018年刷榜Librispeech数据集时提出的模型。
二、FSMN
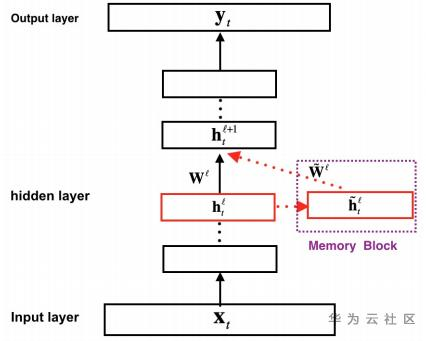
图1. FSMN模型结构
FSMN从本质上来说是一个前馈全连接网络(FNN),创新之处在于其隐藏层中增加了一个记忆模块(memory block)。记忆模块的作用是把每个隐藏状态的前后单元一并编码进来,从而实现对序列前后关系的捕捉。具体的计算流程如下:假设输入序列为,其中表示t时刻的输入数据,记对应的第层隐藏层状态为,则记忆模块的输出为:
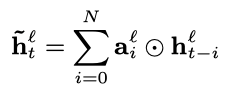
其中,表示逐元素相乘,是需要学习的系数参数。这是单向的FSMN,因为只考虑了t时刻过去的信息,若要考虑未来的信息,只需把t时刻之后的隐藏状态也用同样的方式进行添加,双向FSMN的计算公式如下:
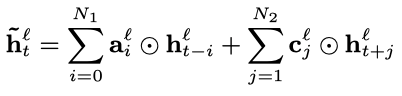
其中,表示考虑过去信息的阶数,表示考虑未来信息的阶数。记忆模块的输出可以视作t时刻的上下文的信息,与t时刻的隐藏层输出一起送入下一隐藏层。下一隐藏层的计算方式为:
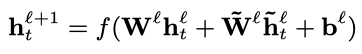
FSMN也可以与注意力机制相结合,此时记忆模块的参数以及输出的计算方式为:
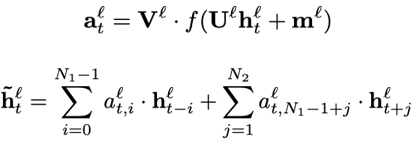
三、cFSMN
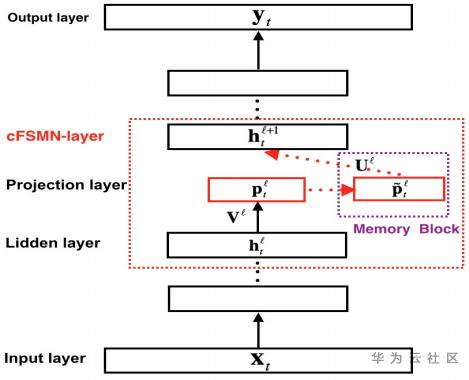
图2. cFSMN模型结构
为了进一步简化模型,压缩模型大小,提高训练和推理速度,cFSMN对FSMN主要做了两个改进:
- 通过对权重矩阵进行低秩矩阵分解,将隐藏层拆成两层;
- 在cFSMN层的计算中进行降维操作,并只把记忆模块的输出送入下一层,当前帧的隐藏状态不再直接送入下一层。
cFSMN层的具体计算步骤为:通过一个低秩线性变换将上一层的输出进行降维,得到的低维向量输入记忆模块,记忆模块的计算类似于FSMN,只是多加一个当前帧的低维向量来引入对齐信息。最后把记忆模块的输出进行一次仿射变换和一次非线性变换,作为当前层的输出。参照图2,每个步骤的计算公式如下:
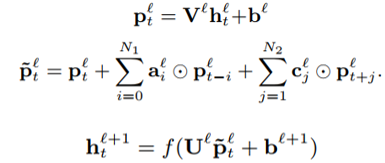
在Switchboard任务上,cFSMN可以在错误率低于FSMN的同时,模型大小缩减至FSMN模型的三分之一。
四、DFSMN
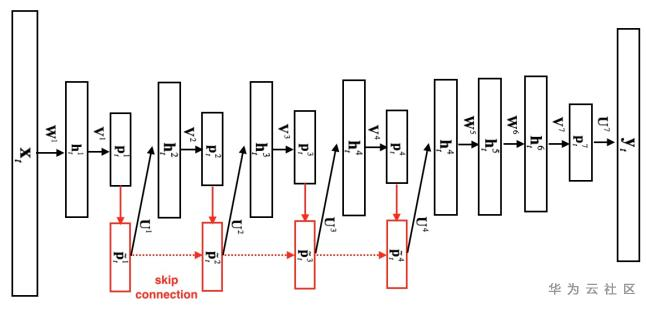
图3. DFSMN模型结构
顾名思义,DeepFSMN (DFSMN)的目的是希望构建一个更深的cFSMN网络结构。但通过直接堆叠cFSMN层很容易在训练时遇到梯度消失的情况,受残差网络(Residual Network)和高速网络(Highway Network)的启发,DFSMN在不同层的记忆模块之间添加了skip connection。同时,由于语音信号的相邻帧之间存在重叠和信息冗余,DFSMN仿照空洞卷积在记忆模块中引入了步幅因子(stride factor)。参照图3,第层记忆模块的计算方式为:
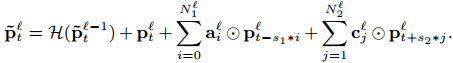
其中,表示skip connection操作,论文中选择的是恒等映射(identity mapping)。和分别是记忆模块在处理过去信息和未来信息时使用的步幅大小。
四、Pyramidal FSMN
Pyramidal FSMN(pFSMN)认为之前的FSMN系列模型的一个缺点是,底层和顶层的网络层都会去提取长期上下文信息,这就造成了重复操作。pFSMN提出了金字塔型的记忆模块,越深的网络层提取越高级的特征,即底层网络层提取音素信息,而顶层网络层提取语义信息和句法信息。这种金字塔结构可以同时提高精度、减少模型参数量。pFSMN减少了DSFMN中使用的skip connection的数量,只在记忆模块的维度发生变化时才进行skip connection操作。记忆模块的计算方式为:
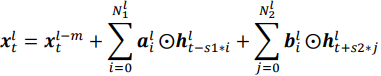
除了引入金字塔结构,pFSMN的另外两个改进是:
- 借鉴图像处理的方法,在FSMN层之前加入一个6层Residual CNN模块,用于提取更为鲁棒的语音特征,并通过降采样减少特征维度。
- 采用交叉熵损失(CE loss)和LF-MMI损失的加权平均来作为模型训练时使用的损失函数。引入CE loss的原因是训练序列数据时很容易出现过拟合的情况,CE loss相当于起到一个正则化的效果。
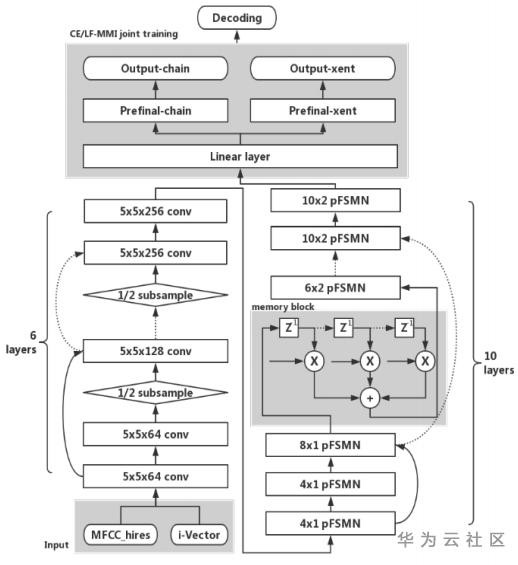
图4. Pyramidal FSMN模型结构
参考文献:
[1] Zhang S, Jiang H, Wei S, et al. Feedforward sequential memory neural networks without recurrent feedback[J]. arXiv preprint arXiv:1510.02693, 2015.
[2] Zhang S, Liu C, Jiang H, et al. Feedforward sequential memory networks: A new structure to learn long-term dependency[J]. arXiv preprint arXiv:1512.08301, 2015.
[3] Zhang S, Jiang H, Xiong S, et al. Compact Feedforward Sequential Memory Networks for Large Vocabulary Continuous Speech Recognition[C]//Interspeech. 2016: 3389-3393.
[4] Zhang S, Lei M, Yan Z, et al. Deep-fsmn for large vocabulary continuous speech recognition[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018: 5869-5873.
[5] Yang X, Li J, Zhou X. A novel pyramidal-FSMN architecture with lattice-free MMI for speech recognition[J]. arXiv preprint arXiv:1810.11352, 2018.
语音识别端到端模型解读:FSMN及其变体模型的更多相关文章
- 点云配准的端到端深度神经网络:ICCV2019论文解读
点云配准的端到端深度神经网络:ICCV2019论文解读 DeepVCP: An End-to-End Deep Neural Network for Point Cloud Registration ...
- 端到端文本识别CRNN论文解读
CRNN 论文: An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Applica ...
- 基于TORCS和Torch7实现端到端连续动作自动驾驶深度强化学习模型(A3C)的训练
基于TORCS(C++)和Torch7(lua)实现自动驾驶端到端深度强化学习模型(A3C-连续动作)的训练 先占坑,后续内容有空慢慢往里填 训练系统框架 先占坑,后续内容有空慢慢往里填 训练系统核心 ...
- 学习笔记(22)- plato-训练端到端的模型
原始文档 Train an end-to-end model To get started we can train a very simple model using Ludwig (feel fr ...
- C#开发BIMFACE系列30 服务端API之模型对比1:发起模型对比
系列目录 [已更新最新开发文章,点击查看详细] 在实际项目中,由于需求变更经常需要对模型文件进行修改.为了便于用户了解模型在修改前后发生的变化,BIMFACE提供了模型在线对比功能,可以利用在 ...
- C#开发BIMFACE系列31 服务端API之模型对比2:获取模型对比状态
系列目录 [已更新最新开发文章,点击查看详细] 在上一篇<C#开发BIMFACE系列30 服务端API之模型对比1:发起模型对比>中发起了2个模型对比,由于模型对比是在BIMFAC ...
- C#开发BIMFACE系列32 服务端API之模型对比3:批量获取模型对比状态
系列目录 [已更新最新开发文章,点击查看详细] 在<C#开发BIMFACE系列31 服务端API之模型对比2:获取模型对比状态>中介绍了根据对比ID,获取一笔记录的对比状态.由于模 ...
- C#开发BIMFACE系列41 服务端API之模型对比
BIMFACE二次开发系列目录 [已更新最新开发文章,点击查看详细] 在建筑施工图审查系统中,设计单位提交设计完成的模型/图纸,审查专家审查模型/图纸.审查过程中如果发现不符合规范的地方,则流 ...
- 【OCR技术系列之七】端到端不定长文字识别CRNN算法详解
在以前的OCR任务中,识别过程分为两步:单字切割和分类任务.我们一般都会讲一连串文字的文本文件先利用投影法切割出单个字体,在送入CNN里进行文字分类.但是此法已经有点过时了,现在更流行的是基于深度学习 ...
- 探索专有领域的端到端ASR解决之道
摘要:本文从<Shallow-Fusion End-to-End Contextual Biasing>入手,探索解决专有领域的端到端ASR. 本文分享自华为云社区<语境偏移如何解决 ...
随机推荐
- VSCode使用JavaScript刷LeetCode配置教程(亲试可以!)
账号秘密都对,但是缺登录不成功的问题 诀窍可能是: 在属性设置中把LeetCode版本改成cn.点击LeetCode配置,修改Endpoint配置项,改成leetcode-cn,再次尝试登陆即可. 大 ...
- KubeEdge v1.15.0发布!新增5大特性
本文分享自华为云社区<KubeEdge v1.15.0发布!新增Windows 边缘节点支持,基于物模型的设备管理,DMI 数据面支持等功能>,作者:云容器大未来 . 北京时间2023年1 ...
- 20.2 OpenSSL 非对称RSA加解密算法
RSA算法是一种非对称加密算法,由三位数学家Rivest.Shamir和Adleman共同发明,以他们三人的名字首字母命名.RSA算法的安全性基于大数分解问题,即对于一个非常大的合数,将其分解为两个质 ...
- django 国际化
参考文档: https://docs.djangoproject.com/zh-hans/2.2/topics/i18n/translation/ https://blog.csdn.net/qq_3 ...
- java——1.变量和数据类型
变量和数据类型 字符.字节.位之间的关系 1.字符:人类可以阅读的文本内容最小单位 字符编码:utf-8,gbk 2.字节:1字符=2字节:1字符=4字节 3.位:1字节=8位 位指的是二进制位, ...
- 在centos7上使用 docker安装mongodb挂载宿主机以及创建其数据库的用户名和密码(最新版本)
前言 因为博主在使用docker安装mongodb并挂载时,发现在网上搜了好多都是以前版本的mongodb,并且按照他们操作总是在进入mongodb出问题,博主搞了好久终于弄好了,故写下博客,供有需要 ...
- 技术向:一文读懂卷积神经网络CNN(转)
目录(?)[-] 卷积神经网络 神经网络 卷积神经网络 1 局部感知 2 参数共享 3 多卷积核 4 Down-pooling 5 多层卷积 ImageNet-2010网络结构 DeepID网络结构 ...
- 一篇文章让你理解:什么是Spring???
背景 市场上,随便一个Java工程师的招牌要求上,都可以看到SSM.Spring.SpringMVC...类似字样.这玩意到底是个啥? 这是中邮消费招聘的岗位要求,可以看到第3点: 3.熟悉Strut ...
- c#中命令模式详解
基本介绍: 命令模式,顾名思义就是将命令抽象化,然后将请求者和接收者通过命令进行绑定. 而命令的请求者只管下达命令,命令的接收者只管执行命令. 从而实现了解耦,请求者和接受者二者相对独立. ...
- EventBus 简明教程
简介 EventBus 是一个用于 Android 和 Java 编程的 事件发布/订阅框架.使用 EventBus 进行事件传递,事件的发布和订阅就被充分解耦合,这使得编程人员从传统而原始的事件传递 ...