eclipse运行mapreduce的wordcount
1,eclipse安装hadoop插件
插件下载地址:链接: https://pan.baidu.com/s/1U4_6kLFNiKeLsGfO7ahXew 提取码: as9e
下载hadoop-eclipse-plugin-2.7.3.jar包,放入eclipse路径下(本人eclipse版本为eclipse mars,路径为C:\Users\Administrator\.p2\pool\plugins,其他版本可直接放入eclipse安装路径下的plugin)
2,安装hadoop到本地,并配置环境变量
HADOOP_HOME:C:\hadoop-2.7.2
PATH后面追加%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
3,修改hadoop配置文件hadoop-2.7.2\etc\hadoop\hadoop-env.cmd(JAVA_HOME路径中的空格会导致错误,所以此处单独处理)
set JAVA_HOME="C:\Program Files"\Java\jdk1.8.0_45
4,配置eclipse中hadoop路径
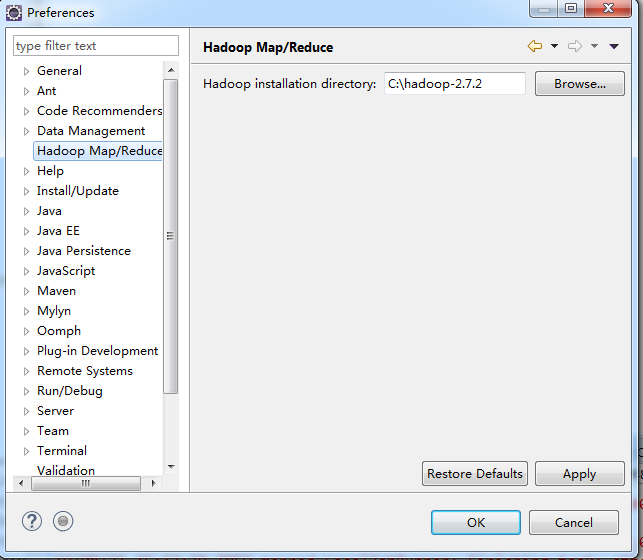
5,window-show views-other-Map/Reduce location,打开mapreduce窗口
6,点击右侧大象,在窗口中配置大数据服务器地址,若host中已配置ip映射可直接使用域名,否则填写集群ip地址
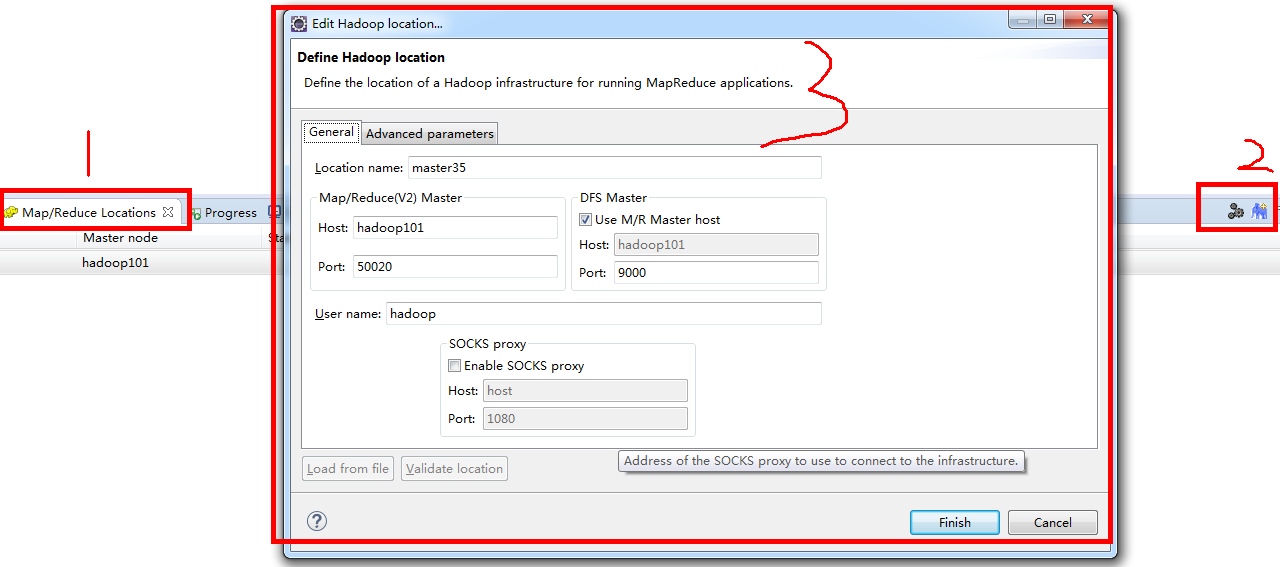
7,左侧窗口出现集群连接信息,目录应同直接在浏览器访问时相同。

8,右键,新建mapreduce项目wordcount

9,将源码中wordcount.java类复制到项目中,代码路径hadoop-2.7.7-src\hadoop-mapreduce-project\hadoop-mapreduce-client\hadoop-mapreduce-client-jobclient\src\test\java\org\apache\hadoop\mapred
源码下载地址:链接: https://pan.baidu.com/s/1yRRymdG2hyhbv-PJjj_21w 提取码: 7chz
10,将log4j.properties文件放入项目src下,文件路径hadoop-2.7.7-src\hadoop-common-project\hadoop-common\src\test\resources
11,在集群创建输入文件夹,并修改权限
hadoop fs -mkdir /hadoopTest
hadoop fs -chmod -R 777 /hadoopTest
12,右键点击hadoopTest,创建input文件夹,注意不要创建output文件夹,若有页需要删除,因为执行程序会自动创建此文件夹

13,右键上传文件,将需要统计的文本,上传到input目录
14,右键wordcount项目,点击run configuration,配置执行执行参数
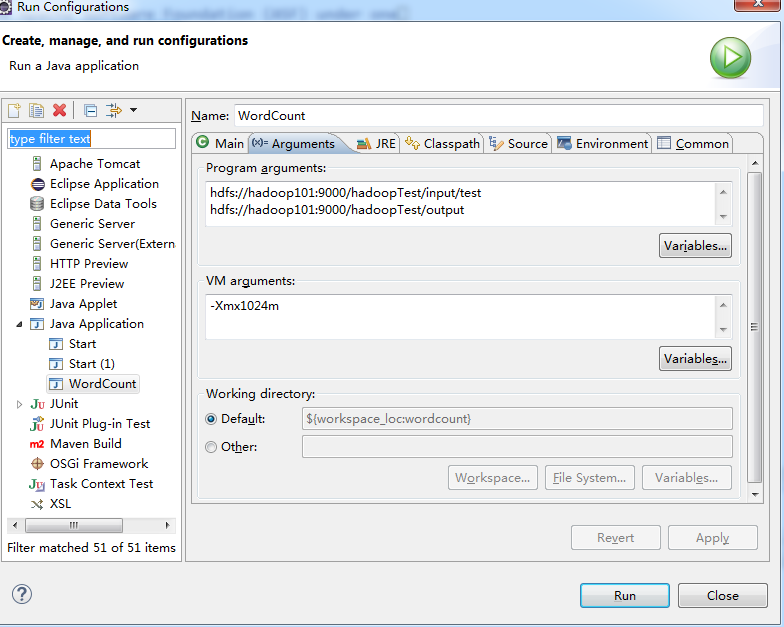
15,点击apply,再点击run按钮,执行程序,再查看dfs locations,发现多了output目录,下面有程序执行结果
16,如果程序执行报错:org.apache.hadoop.io.nativeio.NativeIO$Windwos.access0需要从源码中copy出NativeIO类,放入项目中,修改access方法,改为return0。注意,必须从源码中得到,从jar中得到的类是没有此方法的
eclipse运行mapreduce的wordcount的更多相关文章
- eclipse运行mapreduce报错Permission denied
今天用在eclipse-hadoop平台上运行map reduce(word count)出错了,错误信息为 org.apache.hadoop.security.AccessControlExcep ...
- Window7中Eclipse运行MapReduce程序报错的问题
按照文档:http://www.micmiu.com/bigdata/hadoop/hadoop2x-eclipse-mapreduce-demo/安装配置好Eclipse后,运行WordCount程 ...
- eclipse 运行 mapreduce程序报错 No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
报错信息 17/07/06 17:00:27 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Ap ...
- 使用Eclipse编译运行MapReduce程序 Hadoop2.6.0_Ubuntu/CentOS
使用Eclipse编译运行MapReduce程序 Hadoop2.6.0_Ubuntu/CentOS 2014-10-10 (updated: 2016-05-22) 64246 153 本教程介绍 ...
- hadoop2.2使用手册2:如何运行自带wordcount
问题导读:1.hadoop2.x自带wordcount在什么位置?2.运行wordcount程序,需要做哪些准备? 此篇是在hadoop2完全分布式最新高可靠安装文档 hadoop2.X使用手册1:通 ...
- eclipse运行WordCount
1) 可以完全参考http://www.cnblogs.com/archimedes/p/4539751.html在eclipse下创建MapReduce工程,创建了MR工程,并完成WordCount ...
- Eclipse运行wordcount步骤
Eclipse运行wordcount步骤 第一步:建立工程,导入代码. 第二步:建立文件写入数据(以空格分开),并上传到hdfs上. 1.创建文件并写入数据: 2.上传hdfs 在hadoop权限下就 ...
- 暑假周进度报告(三)-------版本过高后续问题处理,eclipse编译运行MapReduce以及Hadoop学习
问题一:Hadoop版本太高 卸载Hadoop3.2.0 我改安装了Hadoop 2.7.7 如果没有权限下载.可以采用如下方式: 卸载完成以后返回原目录即可 后面的jdk卸载也可以采用这种方式. 按 ...
- 基于 Eclipse 的 MapReduce 开发环境搭建
文 / vincentzh 原文连接:http://www.cnblogs.com/vincentzh/p/6055850.html 上周末本来要写这篇的,结果没想到上周末自己环境都没有搭起来,运行起 ...
随机推荐
- 后端数据中含有html标签和css样式,前端如何转译展示样式效果。
后端含有html标签和css样式的数据: domain="<span style='color:red'>www.baidu.com</span>" (vu ...
- 【题解】士兵训练-C++
题目DescriptionN个士兵排成一队进行军事训练,每个士兵的等级用1…K范围内的数来表示,长官每隔1小时就随便说出M个等级a1,a2…am(1≤ai≤K,M个等级中允许有重复),如果这M个等级组 ...
- 03_每周 5 使用 tar 命令备份/var/log 下的所有日志文件
]# vim /root/logbak.shtar -czf log-`date +%Y%m%d`.tar.gz /var/log ]# crontab -e -u root00 03 * * 5 / ...
- 1626:【例 2】Hankson 的趣味题
1626:[例 2]Hankson 的趣味题题解 [题目描述] Hanks 博士是 BT(Bio-Tech,生物技术)领域的知名专家,他的儿子名叫 Hankson.现在,刚刚放学回家的 Hankson ...
- 虚拟机安装WIN7教程
1.去下载win7原装镜像,推荐去官方网站下载:https://msdn.itellyou.cn/ 也可以直接使用Win7系统和激活工具链接:https://pan.baidu.com/s/1SJSE ...
- Qtcreator中printf()/fprintf()不显示问题处理方法
此处只介绍解决办法,有兴趣的朋友可以分析原因. [问题] 使用Qtcreator开发项目中,printf()的诊断信息,在“应用程序输出”窗口不显示. [解决方法] 1.printf()不显示解决示例 ...
- 【spring源码分析】IOC容器初始化——查漏补缺(二)
前言:在[spring源码分析]IOC容器初始化(八)中多次提到了前置处理与后置处理,本篇文章针对此问题进行分析.Spring对前置处理或后置处理主要通过BeanPostProcessor进行实现. ...
- HTTP之实体和编码
1. Content-Length: 实体的大小 Content-Length 首部指示出报文中实体主体的字节大小.这个大小是包含了所有内容编码的,比如,对文本文件进行了 gzip 压缩的话,Cont ...
- hadoop1.2.1安装配置
原文地址 环境:ubuntu13 使用的用户为普通用户.如:用户ru jdk安装略 1.安装ssh (1) sudo apt-get install openssh-server (2)配置ssh面密 ...
- java time
package cn.itcast_04; import java.text.SimpleDateFormat; import java.util.Date; public ...