吴裕雄 实战PYTHON编程(4)
import hashlib
md5 = hashlib.md5()
md5.update(b'Test String')
print(md5.hexdigest())
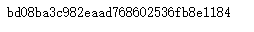
import hashlib
md5 = hashlib.md5(b'Test String').hexdigest()
print(md5)
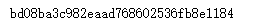
import os
import hashlib
import requests
# url = "http://opendata.epa.gov.tw/ws/Data/REWXQA/?$orderby=SiteName&$skip=0&$top=1000&format=json"
url = "https://www.baidu.com"
# 读取网页原始码
html=requests.get(url).text.encode('utf-8-sig')
# 判断网页是否更新
md5 = hashlib.md5(html).hexdigest()
if os.path.exists('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt'):
with open('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt', 'r') as f:
old_md5 = f.read()
with open('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt', 'w') as f:
f.write(md5)
else:
with open('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt', 'w') as f:
f.write(md5)
if md5 != old_md5:
print('数据已更新...')
else:
print('数据未更新,从数据库读取...')

import os
import ast
import hashlib
import sqlite3
import requests
from bs4 import BeautifulSoup
conn = sqlite3.connect('F:\\pythonBase\\pythonex\\DataBasePM25.sqlite') # 建立数据库连接
cursor = conn.cursor() # 建立 cursor 对象
# 建立一个数据表
sqlstr='''
CREATE TABLE IF NOT EXISTS TablePM25 ("no" INTEGER PRIMARY KEY AUTOINCREMENT
NOT NULL UNIQUE ,"SiteName" TEXT NOT NULL ,"PM25" INTEGER)
'''
cursor.execute(sqlstr)
url = "http://api.help.bj.cn/apis/aqilist/"
#html=requests.get(url).text.encode('utf-8-sig') # 读取网页原始码
html=requests.get(url).text.encode('iso-8859-1').decode('utf-8-sig')
# print(html)
html = html.encode('utf-8-sig')
# 判断网页是否更新
md5 = hashlib.md5(html).hexdigest()
old_md5 = ""
if os.path.exists('F:\\pythonBase\\pythonex\\ch06\\old_md5-.txt'):
with open('F:\\pythonBase\\pythonex\ch06\\old_md5-.txt', 'r') as f:
old_md5 = f.read()
with open('F:\\pythonBase\\pythonex\ch06\\old_md5-.txt', 'w') as f:
f.write(md5)
print("old_md5="+old_md5+";"+"md5="+md5) #显示新老md5码进行观察
if md5 != old_md5:
print('数据已更新...')
sp=BeautifulSoup(html,'html.parser') #解析网页内容
jsondata = ast.literal_eval(sp.text) #此时jscondata取到的是字典类型数据
# 删除数据表内容
js1=jsondata.get("aqidata") #取出字典数据中的aqidata项的值(值是列表)
conn.execute("delete from TablePM25")
conn.commit()
n=1
for city in js1: #city此时是列表js1中的第一条字典数据
CityName=city["city"] #取出city字典数据中的值为"city"的key
if(city["pm2_5"] == ""):
PM25=0
else: #如果city字典中的key对应的value为空,则PM25=0,否则,把PM25=value
PM25=int(city["pm2_5"])
print("城市:{} PM2.5={}".format(CityName,PM25)) #显示城市对应的名称与PM2.5值
# 新增一笔记录
sqlstr="insert into TablePM25 values({},'{}',{})" .format(n,CityName,PM25)
cursor.execute(sqlstr)
n+=1
conn.commit() # 主动更新
else:
print('数据未更新,从数据库读取...')
cursor=conn.execute("select * from TablePM25")
rows=cursor.fetchall()
for row in rows:
print("城市:{} PM2.5={}".format(row[1],row[2]))
conn.close() # 关闭数据库连

import os
import ast
import hashlib
import sqlite3
import requests
from bs4 import BeautifulSoup
# cur_path=os.path.dirname(__file__) # 取得目前路径
# print(cur_path)
conn = sqlite3.connect('F:\\pythonBase\\pythonex\\' + 'DataBasePM25.sqlite') # 建立数据库连接
cursor = conn.cursor() # 建立 cursor 对象
# 建立一个数据表
sqlstr='''
CREATE TABLE IF NOT EXISTS TablePM25 ("no" INTEGER PRIMARY KEY AUTOINCREMENT
NOT NULL UNIQUE ,"SiteName" TEXT NOT NULL ,"PM25" INTEGER)
'''
cursor.execute(sqlstr)
url = "http://api.help.bj.cn/apis/aqilist/"
# 读取网页原始码
# html=requests.get(url).text.encode('utf-8-sig')
html=requests.get(url).text.encode('iso-8859-1').decode('utf-8-sig')
# print(html)
html = html.encode('utf-8-sig')
print('数据已更新...')
sp=BeautifulSoup(html,'html.parser') #sp是bs4.Beautifulsoup类
# 将网页内转换为 list,list 中的元素是 dict
jsondata = ast.literal_eval(sp.text) #把sp.text字符串转为dict类型
js=jsondata.get("aqidata") #从jasondata中取出值为"aqidata"的key对应的value的列表
# 删除数据表内容
conn.execute("delete from TablePM25")
conn.commit()
#把抓到的数据逐条存到数据库
n=1
for city in js:
CityName=city["city"]
PM25=0 if city["pm2_5"] == "" else int(city["pm2_5"])
print("城市:{} PM2.5={}".format(CityName,PM25))
# 新增一条记录
sqlstr="insert into TablePM25 values({},'{}',{})" .format(n,CityName,PM25)
cursor.execute(sqlstr)
n+=1
conn.commit() # 主动更新
conn.close() # 关闭数据库连

from time import sleep
from selenium import webdriver
urls = ['http://www.baidu.com','http://www.wsbookshow.com','http://news.sina.com.cn/']
browser = webdriver.Chrome()
browser.maximize_window
for url in urls:
browser.get(url)
sleep(3)
browser.quit()
from selenium import webdriver #导入webdriver
url='http://www.wsbookshow.com/bookshow/jc/bk/cxsj/12442.html' #以此链接为例
browser=webdriver.Chrome() #生成Chrome浏览器对象(结果是打开Chrome浏览器)
browser.get(url) #在浏览器中打开url
login_form=browser.find_element_by_id("menu_1") ##查找id="menu_1"的元素
print(login_form.text) #显示元素内容
#browser.quit() #退出浏览器,退出驱动程序
username=browser.find_element_by_name("username") #查找name="username"的元素
print(username)
password=browser.find_element_by_name("pwd") #查找name="pwd"的元素
print(password)
login_form=browser.find_element_by_xpath("//input[@name='arcID']")
print(login_form)
login_form=browser.find_element_by_xpath("//div[@id='feedback_userbox']")
print(login_form)
continue_link=browser.find_element_by_link_text('新概念美语')
print(continue_link)
continue_link=browser.find_element_by_link_text('英语')
print(continue_link)
heading1=browser.find_element_by_tag_name('h1')
print(heading1)
content=browser.find_elements_by_class_name('topbanner')
print(content)
content=browser.find_elements_by_css_selector('.topsearch')
print(content)
# print(content.get_property)
print()
browser.quit() #退出浏览器,退出驱动程序

from selenium import webdriver
from time import sleep
url = 'http://www.51cto.com/'
browser = webdriver.Chrome()
browser.maximize_window
browser.get(url)
browser.find_element_by_xpath('//*[@id="login_status"]/a[1]').click() #获取“登录”元素
browser.find_element_by_xpath('//*[@id="loginform-username"]').clear()#清空输入框
browser.find_element_by_xpath('//*[@id="loginform-username"]').send_keys('oomms') #填写用户名
browser.find_element_by_xpath('//*[@id="loginform-password"]').clear() #清空输入框
browser.find_element_by_xpath('//*[@id="loginform-password"]').send_keys('abc123') #填写密码
sleep(3) #加入等待
browser.find_element_by_xpath('//*[@id="login-form"]/div[3]/input').click() #单击“登录”按钮
吴裕雄 实战PYTHON编程(4)的更多相关文章
- 吴裕雄 实战PYTHON编程(10)
import cv2 cv2.namedWindow("frame")cap = cv2.VideoCapture(0)while(cap.isOpened()): ret, im ...
- 吴裕雄 实战PYTHON编程(9)
import cv2 cv2.namedWindow("ShowImage1")cv2.namedWindow("ShowImage2")image1 = cv ...
- 吴裕雄 实战PYTHON编程(8)
import pandas as pd df = pd.DataFrame( {"林大明":[65,92,78,83,70], "陈聪明":[90,72,76, ...
- 吴裕雄 实战PYTHON编程(7)
import os from win32com import client word = client.gencache.EnsureDispatch('Word.Application')word. ...
- 吴裕雄 实战PYTHON编程(6)
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['Simhei']plt.rcParams['axes.unicode ...
- 吴裕雄 实战PYTHON编程(5)
text = '中华'print(type(text))#<class 'str'>text1 = text.encode('gbk')print(type(text1))#<cla ...
- 吴裕雄 实战python编程(3)
import requests from bs4 import BeautifulSoup url = 'http://www.baidu.com'html = requests.get(url)sp ...
- 吴裕雄 实战python编程(2)
from urllib.parse import urlparse url = 'http://www.pm25x.com/city/beijing.htm'o = urlparse(url)prin ...
- 吴裕雄 实战python编程(1)
import sqlite3 conn = sqlite3.connect('E:\\test.sqlite') # 建立数据库联接cursor = conn.cursor() # 建立 cursor ...
随机推荐
- Bluez相关的各种tools的使用
7.1 Bccmd Bccmd是用来和CSR的芯片进行BCCMD(Bluecore command protocol)通讯的一个工具.BCCMD并非蓝牙协议栈的标准,而是CSR芯片的专属 ...
- ubuntu 14.04 git clone 出现 fatal: Unable to find remote helper for 'https'
当你编译安装git时因为没有安装(lib)curl-devel所以导致git clone 和 git push 都会出现这个错误 如果你安装了(lib)curl-devel,然后重新编译安装git就没 ...
- 1.环境搭建-mysql+tomcat+myeclipse安装并配置
一.安装mysql数据库并配置 下载地址:https://pan.baidu.com/s/1OJ3ggda7Cthl4GCxWKbTng 密码:sd6b 1.打开安装程序
- HUD 1175 连连看
连连看 Time Limit : 20000/10000ms (Java/Other) Memory Limit : 65536/32768K (Java/Other) Total Submiss ...
- jquery的load()事件和ajax中load()方法的区别
load事件 当图像加载时,改变 div 元素的文本: $("img").load(function(){ $("div").text("Image ...
- Web安全测试指南--会话管理
会话复杂度: 5.3.2.会话预测: 5.3.3.会话定置: 5.3.4.CSRF: 5.3.5.会话注销: 5.3.6.会话超时:
- word2vec 的理解
1.CBOW 模型 CBOW模型包括输入层.投影层.输出层.模型是根据上下文来预测当前词,由输入层到投影层的示意图如下: 这里是对输入层的4个上下文词向量求和得到的当前词向量,实际应用中,上下文窗口大 ...
- 管理11gRAC基本命令 (转载)
在 Oracle Clusterware 11g 第 2 版 (11.2) 中,有许多子程序和命令已不再使用: crs_stat crs_register crs_unregiste ...
- node多进程
内容: 1.多进程与多线程 2.node中多进程相关模块的使用 1.多进程与多线程 多线程:性能高:复杂.考验程序员 多进程:性能略低:简单.对程序员要求低 Node.js中默认:单进程.单线程,但是 ...
- 〈Android 群英传-神兵利器〉第7章一个的寂寞与一群人的狂欢
|---第7章一个的寂寞与一群人的狂欢 |---7.1如何解决问题 |---Chrome浏览器 |---Chrome开发者工具 |---Chrome插件(Json-Handle:Json格式化查看工具 ...