sklearn标准化-【老鱼学sklearn】
在前面的一篇博文中关于计算房价中我们也大致提到了标准化的概念,也就是比如对于影响房价的参数中有面积和户型,面积的取值范围可以很广,它可以从0-500平米,而户型一般也就1-5。
标准化就是要把这两种参数的取值范围处于一个相对接近的地位,这样在进行梯度下降的计算中能够比较稳定地朝下落方向走,而不至于某个参数一调整步子迈得太大,而另一个参数一调整步子却又太小,有点像一个人的两条腿长短差距很大,走路就会不稳。
另外,Normalization在机器学习中也有叫归一化的,归一化相当于标准化的具体表现,因为取值范围都落到1中。这几个叫法都类似,基本可以认为是同一概念。
关于标准化,也可以参考吴恩达的视频(需翻墙):https://www.coursera.org/learn/machine-learning/lecture/xx3Da/gradient-descent-in-practice-i-feature-scaling
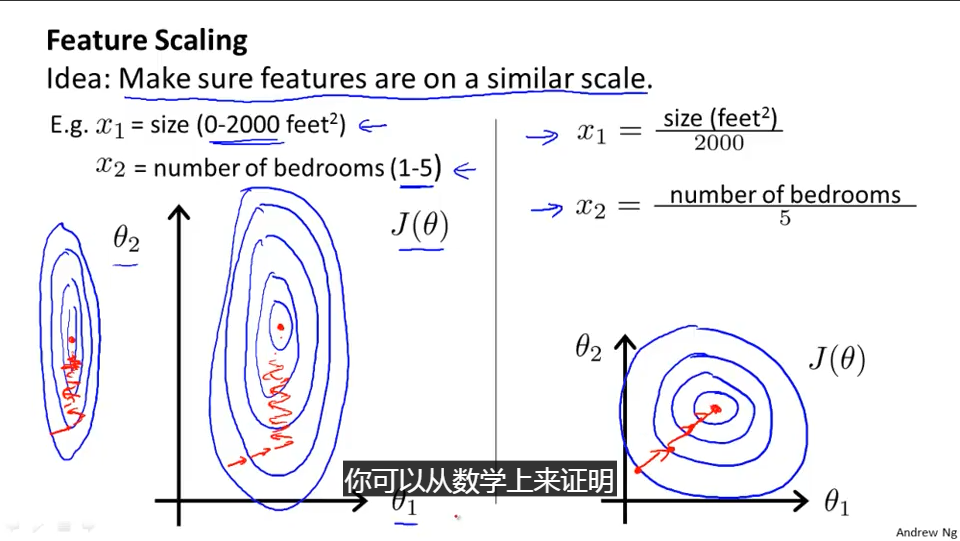
标准化的算法其实很简单,就是把值的结果映射成0到1之间,而映射规则就是除以这些值中最大范围就可以,前面讲的是基本思想,实际的计算公式推导,尤其是开始值不是从0开始如何映射,应该也不复杂,各位读者如果有兴趣自己推导下就可以。
不过sklearn提供了相关的scale方法,例子如下:
import numpy as np
from sklearn import preprocessing
a = np.array([[60, 2, 1],
[150, 3, 3],
[136, 3, 11]], dtype=np.float)
print("a=")
print(a)
print("scale(a)=")
print(preprocessing.minmax_scale(a))
输出为:
a=
[[ 60. 2. 1.]
[ 150. 3. 3.]
[ 136. 3. 11.]]
scale(a)=
[[ 0. 0. 0. ]
[ 1. 1. 0.2 ]
[ 0.84444444 1. 1. ]]
在这个例子中定义了a变量,这个变量有三列,可以看成是有三个属性,例如我们假定第一列是房子的面积,其面积有:60、150、136平米,第二列是户型,分别是2房、3房和3房,第三列是楼层,分别位于1楼、3楼和11楼。
接着就通过正则化函数之后,它们变成了比较接近的数值。
在正则化函数中,也可以直接使用scale进行正则化,例如:
import numpy as np
from sklearn import preprocessing
a = np.array([[60, 2, 1],
[150, 3, 3],
[136, 3, 11]], dtype=np.float)
print("a=")
print(a)
print("scale(a)=")
print(preprocessing.scale(a))
输出为:
a=
[[ 60. 2. 1.]
[ 150. 3. 3.]
[ 136. 3. 11.]]
scale(a)=
[[-1.39936232 -1.41421356 -0.9258201 ]
[ 0.87670892 0.70710678 -0.46291005]
[ 0.5226534 0.70710678 1.38873015]]
这个函数也能把各个属性的数据大小调整到比较一致的范围之内。
下面我们来看下正则化对机器学习性能的影响。
这里提一下机器学习的性能,在计算机系统中关于性能是指计算机的运行速度是否快速,而在机器学习中性能是指机器学习的效果如何,也就是类似预测的准确度是否高,得分是否高。
这里我们用一个例子来对比对数据进行正则化前后的预测得分高低情况:
首先创建用于分类的数据:
from sklearn.datasets.samples_generator import make_classification
# 生成300个数据,有2个特征,random_state设置了一个随机数的种子,这样每次运行都能得到相同的数据集
X, y = make_classification(n_samples=300, n_features=2, n_redundant=0, n_informative=2, random_state=89, n_clusters_per_class=1, scale=100)
print(X)
输出的数据为:
[[ 68.29536774 -49.00310223]
[ 122.44132212 -51.78441945]
[ 25.01641248 -111.93797795]
[-110.32508254 52.9854327 ]
[ 112.36845122 -77.57517306]
[ 146.53631135 -107.44971166]
[ 127.33837644 -117.57349528]
[ 185.96222021 -90.25085534]
[ 141.10711953 -112.51420661]
这里y值的输出类似为:
0 1 0 1 1 0 1 0 0 1 1 1 0 1 0 0 0 0 0 1 0 0 1 1 1 1 1 0 1 0 0 0 0 1 1 1 1
0 1 1 0]
也就是有两个分类,分别为0和1。
我们把X和y的数据在图形上观察一下,这里X有两列相关数据,同时用y值作为分类颜色进行显示,相关添加的代码片段为:
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
显示出的图形为:
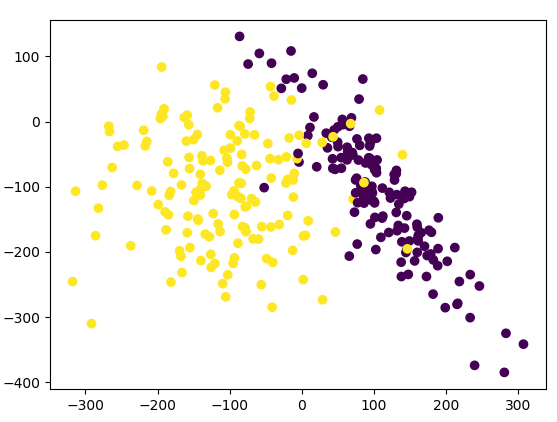
下面我们对其中的数据分割成训练集和测试集,并用SVC(Support Vector Classifier,支持向量机)算法进行训练并计算其得分,全部的代码为:
from sklearn.datasets.samples_generator import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
# 生成300个数据,有2个特征,random_state设置了一个随机数的种子,这样每次运行都能得到相同的数据集
X, y = make_classification(n_samples=300, n_features=2, n_redundant=0, n_informative=2, random_state=89, n_clusters_per_class=1, scale=100)
# 把数据集分割成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 创建SVC算法模型
model = SVC()
# 对训练数据进行训练
model.fit(X_train, y_train)
# 测试结果得分
print(model.score(X_test, y_test))
输出为:
0.455555555556
也就是在未进行正则化时模型的得分为45分。
下面我们来看下对原始数据进行正则化之后的模型得分情况:
from sklearn.datasets.samples_generator import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn import preprocessing
# 生成300个数据,有2个特征,random_state设置了一个随机数的种子,这样每次运行都能得到相同的数据集
X, y = make_classification(n_samples=300, n_features=2, n_redundant=0, n_informative=2, random_state=89, n_clusters_per_class=1, scale=100)
# 正则化数据
X = preprocessing.scale(X)
# 把数据集分割成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 创建SVC算法模型
model = SVC()
# 对训练数据进行训练
model.fit(X_train, y_train)
# 测试结果得分
print(model.score(X_test, y_test))
输出为:
0.933333333333
这样得分就提高到了93分,相当于有93%的准确率。
因此,如果数据集中各个属性之间数值取值范围差异比较大的话,可以通过标准化来提高机器学习的性能。
sklearn标准化-【老鱼学sklearn】的更多相关文章
- sklearn数据库-【老鱼学sklearn】
在做机器学习时需要有数据进行训练,幸好sklearn提供了很多已经标注好的数据集供我们进行训练. 本节就来看看sklearn提供了哪些可供训练的数据集. 这些数据位于datasets中,网址为:htt ...
- sklearn交叉验证-【老鱼学sklearn】
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法.于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证. 一开始 ...
- sklearn交叉验证3-【老鱼学sklearn】
在上一个博文中,我们用learning_curve函数来确定应该拥有多少的训练集能够达到效果,就像一个人进行学习时需要做多少题目就能拥有较好的考试成绩了. 本次我们来看下如何调整学习中的参数,类似一个 ...
- sklearn保存模型-【老鱼学sklearn】
训练好了一个Model 以后总需要保存和再次预测, 所以保存和读取我们的sklearn model也是同样重要的一步. 比如,我们根据房源样本数据训练了一下房价模型,当用户输入自己的房子后,我们就需要 ...
- sklearn交叉验证2-【老鱼学sklearn】
过拟合 过拟合相当于一个人只会读书,却不知如何利用知识进行变通. 相当于他把考试题目背得滚瓜烂熟,但一旦环境稍微有些变化,就死得很惨. 从图形上看,类似下图的最右图: 从数学公式上来看,这个曲线应该是 ...
- sklearn模型的属性与功能-【老鱼学sklearn】
本节主要讲述模型中的各种属性及其含义. 例如上个博文中,我们有用线性回归模型来拟合房价. # 创建线性回归模型 model = LinearRegression() # 训练模型 model.fit( ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- 二分类问题续 - 【老鱼学tensorflow2】
前面我们针对电影评论编写了二分类问题的解决方案. 这里对前面的这个方案进行一些改进. 分批训练 model.fit(x_train, y_train, epochs=20, batch_size=51 ...
- numpy有什么用【老鱼学numpy】
老鱼为了跟上时代潮流,也开始入门人工智能.机器学习了,瞬时觉得自己有点高大上了:). 从机器学习的实用系列出发,我们会以numpy => pandas => scikit-learn =& ...
随机推荐
- centos6/7安装java和maven
下载安装包并解压到相关目录即可 编辑环境变量vim /etc/profile.d/maven.sh export JAVA_HOME=/app/soft/java-1.8.0_181 export J ...
- 记录一次被bc利用跳转过程分析
挖公司的项目站,发现站点一访问就直接跳转到了赌博站,有点懵逼,简单分析下hc利用过程: 公司项目站:http://***.com 当我访问它: 通过http:***.com直接跳转到了306648.c ...
- txt文件按行处理工具类(可以截取小说、分析日志等)【我】
txt文件按行处理工具类(可以分析日志.截取小说等) package file; import java.io.BufferedReader; import java.io.BufferedWrite ...
- python去除html标签的几种方法
import re from bs4 import BeautifulSoup from lxml import etree html = '<p>你好</p><br/& ...
- Eclipse拷贝动态的web工程修改context root的值
Eclipse拷贝动态的web工程修改context root的值 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. context root的名称一般是我们访问URL时的PATH路径 ...
- 金融量化分析【day110】:Pandas-DataFrame索引和切片
一.实验文档准备 1.安装 tushare pip install tushare 2.启动ipython C:\Users\Administrator>ipython Python 3.7.0 ...
- Entity Framework入门教程(11)---EF6中的异步查询和异步保存
EF6中的异步查询和异步保存 在.NET4.5中介绍了异步操作,异步操作在EF中也很有用,在EF6中我们可以使用DbContext的实例进行异步查询和异步保存. 1.异步查询 下边是一个通过L2E语法 ...
- line-height && vertical-align 学习总结
前言 line-height.font-size.vertical-align是设置行内元素布局的关键属性.这三个属性是相互依赖的关系,改变行间距离.设置垂直对齐等都需要它们的通力合作. 行高 lin ...
- Filebeat+ELK部署文档
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的Filebeat+ELK开源实时日志分析平台的记录过程,有不对的地方还望指出. 简单介绍: 日志主要包括系统日志.应用 ...
- Linux负载查询定位工具
1 uptime命令,负载查询命令 02:34:03 // 当前时间up 2 days, 20:14 // 系统运行时间1 user // 正在登录用户数 而最后三个数字呢,依次则是过去 1 分钟.5 ...