#Week2 Linear Regression with One Variable
一、Model Representation
还是以房价预测为例,一图胜千言:

h表示一个从x到y的函数映射。
二、Cost Function
因为是单变量线性回归,所以假设函数是:
\]
所以接下来的问题是怎样确定参数\(\theta_0\)和\(\theta_1\)?
这两个参数会决定我们的模型预测值与训练集的实际数据的差距,这就是建模误差。
那么在回归问题中,代价函数选择如下的平方误差函数比较合理:
\]
m是训练集的样本数目,\(x^{(i)}\)是每个房子的尺寸,\(y^{(i)}\)是实际价格。
只要寻找使得\(J(\theta_0,\theta_1)\)最小的参数即可。
之所以要除以2,主要是为了后续的梯度下降法求导时抵消平方的那个2。
三、Gradient Descent
为了求得代价函数的最小值,采用梯度下降法。
- 用一个随机的参数组合计算\(J\)
- 找到一个使得\(J\)下降最多的参数组合,更新参数,直到找到一个局部最优解
就像下山一样,每次都走一步,每次选择下降最快的方向直到局部最低。
在批量梯度下降算法(所有的训练样本都要用到)中,同步更新所有参数:

\(\alpha\)是学习率,表示每一步走多长。
如果\(\alpha\)太小,那么更新的过程就会很缓慢;如果\(\alpha\)太大,可能跳过最低点,导致发散。
当接近局部最优时,由于斜率会越来越小,所以每一步会自动走得很小,不需要减小学习率\(\alpha\)。
四、Gradient Descent For Linear Regression
对之前得回归模型应用梯度下降算法:
对\(J(\theta_0,\theta_1)\)求关于\(\theta_0\)、\(\theta_1\)的偏导数,带入参数更新公式,有:
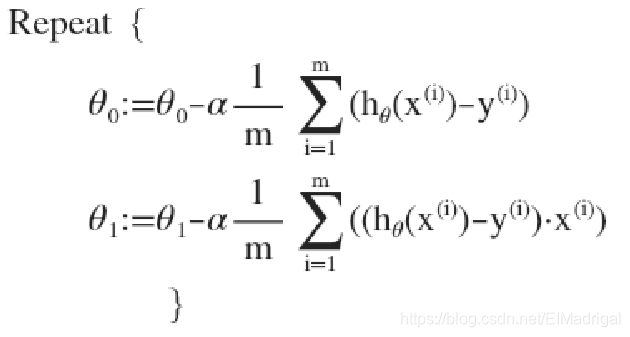
#Week2 Linear Regression with One Variable的更多相关文章
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable
原文:http://blog.csdn.net/abcjennifer/article/details/7700772 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Stanford机器学习---第一讲. Linear Regression with one variable
原文:http://blog.csdn.net/abcjennifer/article/details/7691571 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 机器学习笔记1——Linear Regression with One Variable
Linear Regression with One Variable Model Representation Recall that in *regression problems*, we ar ...
- Machine Learning 学习笔记2 - linear regression with one variable(单变量线性回归)
一.Model representation(模型表示) 1.1 训练集 由训练样例(training example)组成的集合就是训练集(training set), 如下图所示, 其中(x,y) ...
- Ng第二课:单变量线性回归(Linear Regression with One Variable)
二.单变量线性回归(Linear Regression with One Variable) 2.1 模型表示 2.2 代价函数 2.3 代价函数的直观理解 2.4 梯度下降 2.5 梯度下 ...
- 【cs229-Lecture2】Linear Regression with One Variable (Week 1)(含测试数据和源码)
从Ⅱ到Ⅳ都在讲的是线性回归,其中第Ⅱ章讲得是简单线性回归(simple linear regression, SLR)(单变量),第Ⅲ章讲的是线代基础,第Ⅳ章讲的是多元回归(大于一个自变量). 本文的 ...
- MachineLearning ---- lesson 2 Linear Regression with One Variable
Linear Regression with One Variable model Representation 以上篇博文中的房价预测为例,从图中依次来看,m表示训练集的大小,此处即房价样本数量:x ...
- 斯坦福第二课:单变量线性回归(Linear Regression with One Variable)
二.单变量线性回归(Linear Regression with One Variable) 2.1 模型表示 2.2 代价函数 2.3 代价函数的直观理解 I 2.4 代价函数的直观理解 I ...
- 机器学习 (一) 单变量线性回归 Linear Regression with One Variable
文章内容均来自斯坦福大学的Andrew Ng教授讲解的Machine Learning课程,本文是针对该课程的个人学习笔记,如有疏漏,请以原课程所讲述内容为准.感谢博主Rachel Zhang的个人笔 ...
随机推荐
- 数据科学 R语言速成
文章更新于:2020-03-07 按照惯例,需要的文件附上链接放在文首: 文件名:R-3.6.2-win.exe 文件大小:82.4M 下载链接:https://www.lanzous.com/i9c ...
- C语言 生日快乐
#include <stdio.h> #include <math.h> #include <stdlib.h> #define I 20 #define R 34 ...
- python3(十九)Partial func
# 偏函数(Partial function) # 如int()函数可以把字符串转换为整数,当仅传入字符串时,int()函数默认按十进制转换 # 但int()函数还提供额外的base参数,默认值为10 ...
- tf.nn.softmax_cross_entropy_with_logits 分类
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None) 参数: logits:就是神经网络最后一层的输出,如果有batch ...
- SwiftUI - 一步一步教你使用UIViewRepresentable封装网络加载视图(UIActivityIndicatorView)
概述 网络加载视图,在一个联网的APP上可以讲得上是必须要的组件,在SwiftUI中它并没有提供如 UIKit 中的UIActivityIndicatorView直接提供给我们调用,但是我们可以通过 ...
- Trie(字典树、前缀树)
目录 什么是Trie? 创建一棵Trie 向Trie中添加元素 Trie的查询操作 对比二分搜索树和Trie的性能 leetcode上的问题 什么是Trie? Trie是一个多叉树,Trie专门为 ...
- 1 - Apache HttpClient 简单使用
Apache HttpClient 是Apache 开源的实现Http协议的java开源库. HttpClien 是客户端的HTTP通信实现库,实现HTTP GET 和POST请求,获取响应内容. A ...
- PHP代码审计(初级篇)
一.常见的PHP框架 1.zendframwork: (ZF)是Zend公司推出的一套PHP开发框架 功能非常的强大,是一个重量级的框架,ZF 用 100%面向对象编码实现. ZF 的组件结构独一无二 ...
- threejs 鼠标移动控制模型旋转
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- 【three.js 第一课】创建场景,显示几何体
<!DOCTYPE html> <html> <head> <title>demo1</title> </head> <s ...