第二篇:基于K-近邻分类算法的约会对象智能匹配系统
前言
假如你想到某个在线约会网站寻找约会对象,那么你很可能将该约会网站的所有用户归为三类:
1. 不喜欢的
2. 有点魅力的
3. 很有魅力的
你如何决定某个用户属于上述的哪一类呢?想必你会分析用户的信息来得到结论,比如该用户 "每年获得的飞行常客里程数","玩网游所消耗的时间比","每年消耗的冰淇淋公升数"。
使用机器学习的K-近邻算法,可以帮助你在获取到用户的这三个信息后(或者更多信息 方法同理),自动帮助你对该用户进行分类,多方便呀!
本文将告诉你如何具体实现这样一个自动分类程序。
第一步:收集并准备数据
首先,请搜集一些约会数据 - 尽可能多。
然后将自行搜集到的数据存放到一个txt文件中,例如,可以将每个样本数据各为一行,
前言中提到的那三个分析数据(特征)以及分析结果(整数表示)各为一列,如下所示:
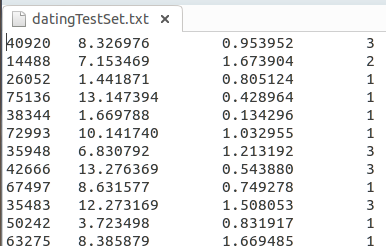
再编写函数将这些数据从文件中取出并存放到数据结构中:
# 导入numpy数学运算库
import numpy # ==============================================
# 输入:
# 训练集文件名(含路径)
# 输出:
# 特征矩阵和标签向量
# ==============================================
def file2matrix(filename):
'获取训练集数据' # 打开训练集文件
fr = open(filename)
# 获取文件行数
numberOfLines = len(fr.readlines())
# 文件指针归0
fr.seek(0)
# 初始化特征矩阵
returnMat = numpy.zeros((numberOfLines,3))
# 初始化标签向量
classLabelVector = []
# 特征矩阵的行号 也即样本序号
index = 0 for line in fr: # 遍历训练集文件中的所有行
# 去掉行头行尾的换行符,制表符。
line = line.strip()
# 以制表符分割行
listFromLine = line.split('\t')
# 将该行特征部分数据存入特征矩阵
returnMat[index,:] = listFromLine[0:3]
# 将该行标签部分数据存入标签矩阵
classLabelVector.append(int(listFromLine[-1]))
# 样本序号+1
index += 1 return returnMat,classLabelVector
获取到数据后就可以print查看获取到的数据内容了,如下:
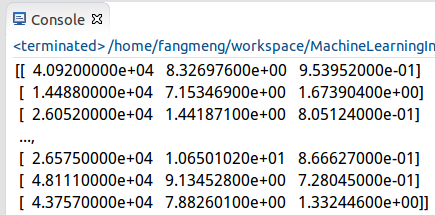
很显然,这样的显示非常的不友好,可采用Python的Matplotlib库来图像化地展示获取到的数据。
如果你是在Ubuntu下使用Eclipse插件编译PyDev的话,安装Matplotlib是很坑的。
在获取到安装包后,还得在插件设置那里添加新的库路径,因为Matplotlib不会自动安装到Python2.7的库目录下,这和NumPy不同。
下面这个才是正确的库路径:

然后就可以编写以下代码进行数据的分析了:
# 新建一个图对象
fig = plt.figure()
# 设置1行1列个图区域,并选择其中的第1个区域展示数据。
ax = fig.add_subplot(111)
# 以训练集第一列(玩网游所消耗的时间比)为数据分析图的行,第二列(每年消费的冰淇淋公升数)为数据分析图的列。
ax.scatter(datingDataMat[:,1], datingDataMat[:,2])
# 展示数据分析图
plt.show()
另外在代码顶部记得包含所需的matplotlib库:
# 导入Matplotlib库
import matplotlib.pyplot as plt
import matplotlib
运行完后,输出数据分析图如下:
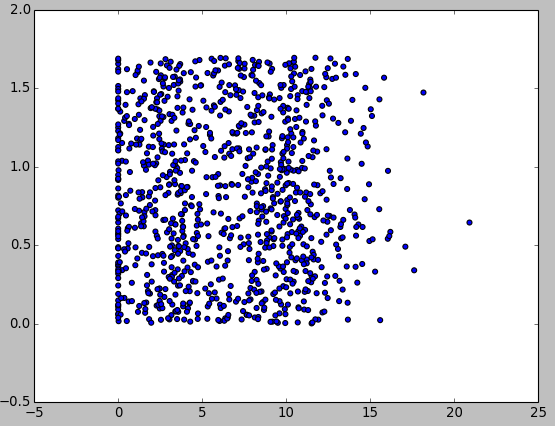
这里发现一个问题,上面的数据分析图并没有显示分类的结果。
进一步优化数据分析图显示部分代码:
# 新建一个图对象
fig = plt.figure()
# 设置1行1列个图区域,并选择其中的第1个区域展示数据。
ax = fig.add_subplot(111)
# 以训练集第一列(玩网游所消耗的时间比)为数据分析图的行,第二列(每周消费的冰淇淋公升数)为数据分析图的列。
ax.scatter(datingDataMat[:,1], datingDataMat[:,2], 15.0*numpy.array(datingLabels), 15.0*numpy.array(datingLabels))
# 坐标轴定界
ax.axis([-2,25,-0.2,2.0])
# 坐标轴说明 (matplotlib配置中文显示有点麻烦 这里直接用英文的好了)
plt.xlabel('Percentage of Time Spent Playing Online Games')
plt.ylabel('Liters of Ice Cream Consumed Per Week')
# 展示数据分析图
plt.show()
得到如下数据分析图:
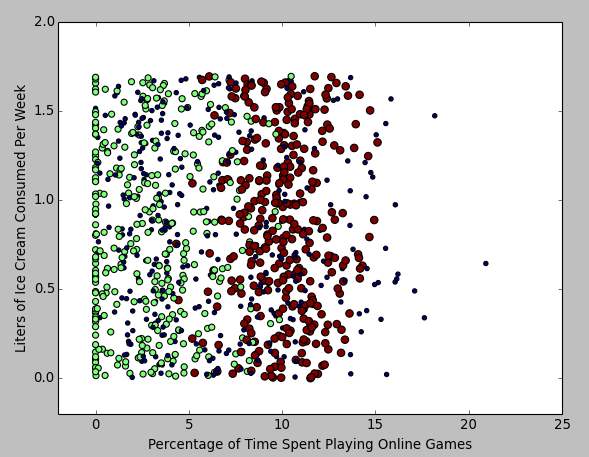
也可以用同样方法得到 "每年获得的飞行常客里程数" 和 "玩网游所消耗的时间比" 为轴的图:
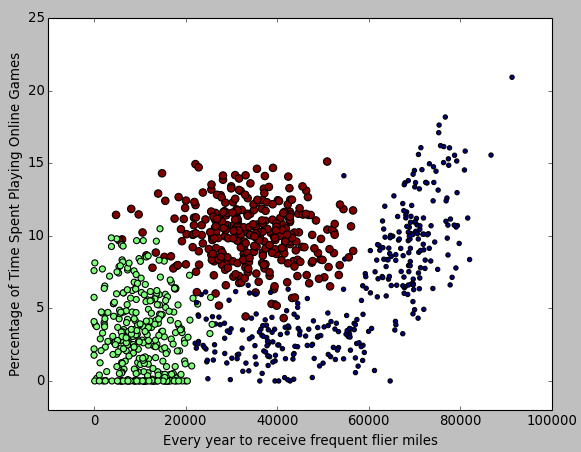
第三步:数据归一化
想必你会发现,我们分析的这三个特征,在距离计算公式中所占的权重是不同的:飞机历程肯定要比吃冰淇淋的公升数大多了。
因此,需要将它们转为同样的一个数量区间,再进行距离计算。 --- 这个步骤就叫做数据归一化。
可以使用如下公式对数据进行归一化:
newValue = (oldValue - min) / (max - min)
即用旧的特征值去减它取到的最小的值,然后再除以它的取值范围。
很显然,所有得到的新值取值均在 0 -1 。
这部分代码如下:
# ==============================================
# 输入:
# 训练集
# 输出:
# 归一化后的训练集
# ==============================================
def autoNorm(dataSet):
'数据归一化' # 获得每列最小值
minVals = dataSet.min(0)
# 获得每列最大值
maxVals = dataSet.max(0)
# 获得每列特征的取值范围
ranges = maxVals - minVals
# 构建初始矩阵(模型同dataSet)
normDataSet = numpy.zeros(numpy.shape(dataSet)) # 数据归一化矩阵运算
m = dataSet.shape[0]
normDataSet = dataSet - numpy.tile(minVals, (m,1))
# 注意/是特征值相除法。/在别的函数库也许是矩阵除法的意思。
normDataSet = normDataSet/numpy.tile(ranges, (m,1)) return normDataSet
第四步:测试算法
测试的策略是随机取10%的数据进行分析,再判断分类准确率如何。
这部分代码如下:
# ================================================
# 输入:
# 空
# 输出:
# 对指定训练集文件进行K近邻算法测试并打印测试结果
# ================================================
def datingClassTest():
'分类算法测试' # 设置要测试的数据比重
hoRatio = 0.10
# 获取训练集
datingDataMat,datingLabels = file2matrix('datingTestSet.txt')
# 数据归一化
normMat, ranges, minVals = autoNorm(datingDataMat)
# 计算实际要测试的样本数
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
# 存放错误数
errorCount = 0.0 # 对测试集样本一一进行分类并分析打印结果
print "错误的分类结果如下:"
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
if (classifierResult != datingLabels[i]):
print "分类结果: %d, 实际结果: %d" % (classifierResult, datingLabels[i])
errorCount += 1.0
print "总错误率: %.2f" % (errorCount/float(numTestVecs))
print "总错误数:%.2f" % errorCount
其中,classify0 函数在文章K-近邻分类算法原理分析与代码实现中有具体实现。
打印出如下结果:

错误率为5%左右,这是应该算是比较理想的状况了吧。
第五步:使用算法构建完整可用系统
下面,可以在这个训练集和分类器之上构建一个完整的可用系统了。
系统功能很简单:用户输入要判断对象三个特征 - "每年获得的飞行常客里程数","玩网游所消耗的时间比","每年消耗的冰淇淋公升数"。
PS:在真实系统中,这部分输入可不由用户来输入,而从网站直接下载数据。
程序帮你判断你是不喜欢还是有点喜欢,抑或是很喜欢。
这部分代码如下:
# ===========================================================
# 输入:
# 空
# 输出:
# 对用户指定的对象以指定的训练集文件进行K近邻分类并打印结果信息
# ===========================================================
def classifyPerson():
'约会对象分析系统' # 分析结果集合
resultList = ['不喜欢', '有点喜欢', '很喜欢'] # 获取用户输入的目标分析对象的特征值
percentTats = float(raw_input("玩网游所消耗的时间比:"))
ffMiles = float(raw_input("每年获得的飞行常客里程数:"))
iceCream = float(raw_input("每年消费的冰淇淋公升数:")) # 获取训练集
datingDataMat, datingLabels = file2matrix('datingTestSet.txt')
# 数据归一化
normMat, ranges, minVals = autoNorm(datingDataMat)
# 获取分类结果
inArr = numpy.array([ffMiles, percentTats, iceCream])
classifierResult = classify0((inArr-minVals)/ranges, normMat, datingLabels, 3) print "分析结果:", resultList[classifierResult-1]
运行结果:
至此,该系统编写完毕。
小结
1. KNN算法其实并没有一个实际的 "训练" 过程。取得了数据就当作是训练过了的。在下下篇文章将讲解决策树,它就有详细的训练,或者说知识学习的过程。
2. 可采用从网站自动下载数据的方式,让这个系统的决策更为科学,再加上良好的界面,就能投入实际使用了。
3. 下篇文章将讲解KNN算法一个更为高级的应用 - 手写识别系统。
4. 这个程序也看出,处理文本/字符串方面,Python比C++好用多了。
第二篇:基于K-近邻分类算法的约会对象智能匹配系统的更多相关文章
- K近邻分类算法实现 in Python
K近邻(KNN):分类算法 * KNN是non-parametric分类器(不做分布形式的假设,直接从数据估计概率密度),是memory-based learning. * KNN不适用于高维数据(c ...
- 查看neighbors大小对K近邻分类算法预测准确度和泛化能力的影响
代码: # -*- coding: utf-8 -*- """ Created on Thu Jul 12 09:36:49 2018 @author: zhen &qu ...
- K邻近分类算法
# -*- coding: utf-8 -*- """ Created on Thu Jun 28 17:16:19 2018 @author: zhen "& ...
- 第三篇:基于K-近邻分类算法的手写识别系统
前言 本文将继续讲解K-近邻算法的项目实例 - 手写识别系统. 该系统在获取用户的手写输入后,判断用户写的是什么. 为了突出核心,简化细节,本示例系统中的输入为32x32矩阵,分类结果也均为数字.但对 ...
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- OpenCV手写数字字符识别(基于k近邻算法)
摘要 本程序主要参照论文,<基于OpenCV的脱机手写字符识别技术>实现了,对于手写阿拉伯数字的识别工作.识别工作分为三大步骤:预处理,特征提取,分类识别.预处理过程主要找到图像的ROI部 ...
- 每日一个机器学习算法——k近邻分类
K近邻很简单. 简而言之,对于未知类的样本,按照某种计算距离找出它在训练集中的k个最近邻,如果k个近邻中多数样本属于哪个类别,就将它判决为那一个类别. 由于采用k投票机制,所以能够减小噪声的影响. 由 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- 第七篇:Logistic回归分类算法原理分析与代码实现
前言 本文将介绍机器学习分类算法中的Logistic回归分类算法并给出伪代码,Python代码实现. (说明:从本文开始,将接触到最优化算法相关的学习.旨在将这些最优化的算法用于训练出一个非线性的函数 ...
随机推荐
- php 之 查询 投票练习(0508)
练习题目: 解题: 方法一: 1. 投票主页面: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ...
- openerp binary filed import export
1: user xmlrpc 2: use csv file to export import but want to change the csv model field_size_limit
- GPUImage 自定义滤镜
GPUImage 自定义滤镜 GPUImage 是一个基于 GPU 图像和视频处理的开源 iOS 框架.由于使用 GPU 来处理图像和视频,所以速度非常快,它的作者 BradLarson 称在 iPh ...
- EasyUI篇の日期控件
页面代码: <input type="text" id='astartTime' class="easyui-datebox" style="w ...
- linux中bin和xbin下可执行程序的区别
/bin下的都是Linux最基础的,所有用户都可以使用的外部命令 /sbin下的都是只有超级用户root才能使用的.管理Linux系统的外部命令 /usr/bin以及/usr/local/bin下的都 ...
- python 单元测试
http://blog.csdn.net/five3/article/details/7104466
- 概率质量函数:怀孕周期的PMF
__author__ = 'dell' import surveyimport Pmfimport matplotlib.pyplot as pyplot table = survey.Pregnan ...
- 通过 IDE 向 Storm 集群远程提交 topology
转载: http://weyo.me/pages/techs/storm-topology-remote-submission/ http://www.javaworld.com/article/20 ...
- CP30,DBCP数据源配置
Spring中 CP30数据源配置 <!-- 加载属性文件 01--> <bean id= "propertyConfigurer" class="or ...
- 在浏览器控制台调试php程序
jsp中用system.out.print如果是在eclipse中调试的话,eclipse会自动拦截系统输出流, 然后输出在控制台中,而http输出流则不受影响,php好像无此功能, PHP是一种服务 ...