Spark源码剖析 - SparkContext的初始化(二)_创建执行环境SparkEnv
2. 创建执行环境SparkEnv
SparkEnv是Spark的执行环境对象,其中包括众多与Executor执行相关的对象。由于在local模式下Driver会创建Executor,local-cluster部署模式或者Standalone部署模式下Worker另起的CoarseGrainedExecutorBackend进程中也会创建Executor,所以SparkEnv存在于Driver或者CoarseGrainedExecutorBackend进程中。创建SparkEnv主要使用SparkEnv的createDriverEnv,SparkEnv.createDriverEnv方法有三个参数:conf、isLocal和listenerBus。
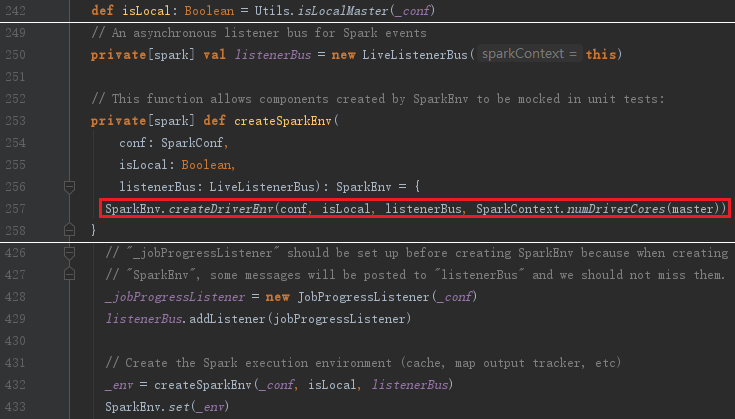
上面代码中的_conf是对SparkConf的复制,isLocal标识是否是单机模式,listenerBus采用监听器模式维护各类事件的处理。
SparkEnv的方法createDriverEnv最终调用create创建SparkEnv。SparkEnv的构造步骤如下:
- 创建安全管理器SecurityManager;
- 创建基于Netty的RPC通信工厂RpcEnv
- 创建广播管理器BroadcastManager;
- 创建Map任务输出跟踪器mapOutputTracker;
- 实例化ShuffleManager;
- 创建MemoryManager;
- 创建块传输服务BlockTransferService;
- 创建BlockManagerMaster;
- 创建块管理器BlockManager;
- 创建测量系统MetricsSystem;
- 创建SparkEnv;
2.1 安全管理器SecurityManager
SecurityManager主要对权限、账户进行设置,如果使用Hadoop YARN作为集群管理器,则需要使用证书生成secret key登录,最后给当前系统设置默认的口令认证实例,此实例采用匿名内部类实现,如图:

2.2 创建基于Netty的RPC通信RpcEnv
Netty是Spark中最基础的设施。....
2.3 创建广播管理器BroadcastManager
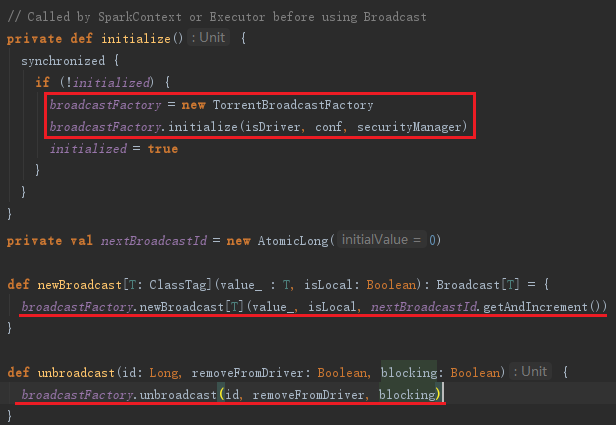
BroadcastManager用于将配置信息和序列化后的RDD、Job以及ShuffleDependency等信息在本地存储。如果为了容灾,也会复制到其他节点上。创建BroadcastManager的代码如下:

BoradcastManager必须在其初始化方法initialize被调用后,才能生效。initialize方法实际利用发射生成广播工厂示例broadcastFactory(可以配置属性spark.broadcast.factory指定,默认为org.apache.spark.broadcast.TorrentBroadcastFactory)。BroadcastManager的广播方法new Broadcast实际代理了工厂broadcastFactory的new Broadcast方法来生成广播对象。unbroadcast方法实际代理了工厂broadcastFactory的unbroadcast方法生成非广播对象。BroadcastManager的initialize、unbroadcast及new Broadcast方法见代码:
2.4 创建Map任务输出跟踪器mapOutputTracker
mapOutputTracker用于跟踪map阶段任务的输出状态,此状态便于reduce阶段任务获取地址及中间输出结果。每个map任务或者reduce任务都会有其唯一标识,分别为mapId和reduceId。每个reduce任务的输入可能是多个map任务的输出,reduce会到各个map任务的所在节点上拉取Block,这一过程叫做shuffle。每批shuffle过程都有唯一的标识shuffleId。
这里先介绍下MapOutputTrackerMaster。MapOutputTrackerMaster内部使用mapStatuses:ConcurrentHashMap[Int, Array[MapStatus]]来维护跟踪各个map任务的输出状态。其中key对应shuffleId,Array存储各个map任务对应的状态信息MapStatus。由于MapStatus维护了map输出Block的地址BlockManagerId,所以reduce任务知道从何处获取map任务的中间输出。MapOutputTrackerMaster还使用cachedSerializedStatuses:ConcurrentHashMap[Int, Array[Byte]]维护序列化后的各个map任务的输出状态。其中key对应shuffleId,Array存储各个序列化MapStatus生成的字节数组。
Driver和Executor处理MapOutputTracker的方式有所不同。
- 如果当前应用程序是Driver,则创建MapOutputTrackerMaster,然后创建MapOutputTrackerMasterEndpoint,并且注册到RpcEnv中。
- 如果当前应用程序是Executor,则创建MapOutputTrackerWorker,并从RpcEnv中找到MapOutputTrackerMasterEndpoint的引用。
无论是Driver还是Executor,最后都由mapOutputTracker的属性trackerEndpoint持有MapOutputTrackerMasterEndpoint的引用,代码如图:
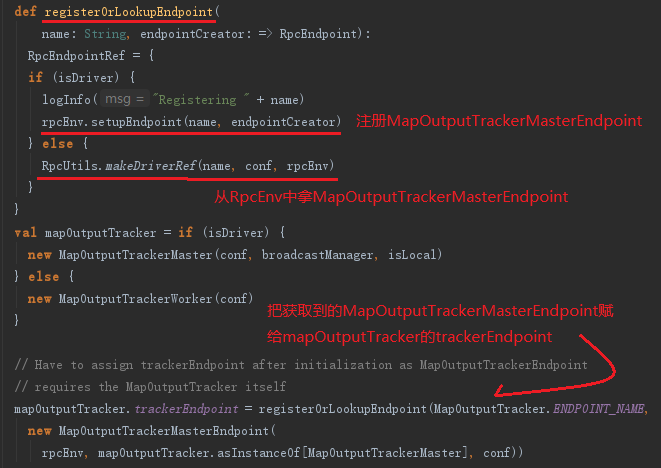
map任务的状态正是由Executor向持有的MapOutputTrackerMasterEndpoint发送消息,将map任务状态同步到mapOutputTracker的mapStatuses和cachedSerializedStatuses的。Executor究竟是如何找到MapOutputTrackerMasterEndpoint的?registerOrLookupEndpoint方法通过调用RpcUtils.makeDriverRef找到MapOutputTrackerMasterEndpoint,实际正是利用RpcEnv提供的分布式消息机制实现的。
2.5 实例化ShuffleManager
ShuffleManager负责管理本地及远程的block数据的shuffle操作。ShuffleManager默认为通过反射方式生成的SortShuffleManager实例。SortShuffleManager通过持有的IndexShuffleBlockManager间接操作BlockManager中的DiskBlockManager将map结果写入本地,并根据shuffleId、mapId写入索引文件,也能通过MapOutputTrackerMaster种种那个维护的mapStatuses从本地或者其他远程节点读取文件。Spark作为并行计算框架,同一个作业会被划分为多个任务在多个节点上并行执行,reduce的输入可能存在于多个节点上,因此需要通过“洗牌”将所有reduce的输入汇总起来,这个过程就是shuffle。
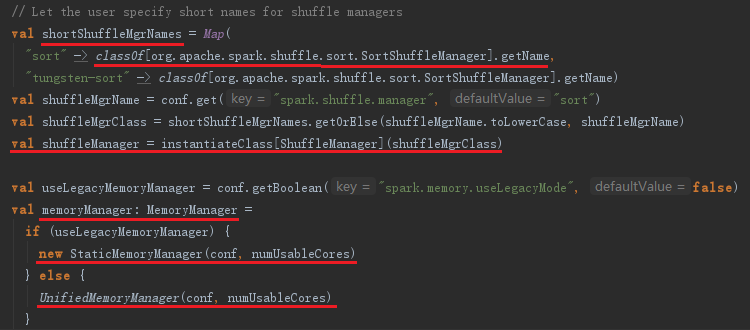
shuffleManager和MemoryManager的创建。
2.6 内存管理器MemoryManager
用于管理最大Execution内存和最大Storage内存,可以通过spark.memory.useLegacyMode选择StaticMemoryManager模式还是UnifiedMemoryManager模式。一般默认是UnifiedMemoryManager模式。对于StaticMemoryManager和UnifiedMemoryManager模式可以通过spark.executor.memory、spark.shuffle.memoryFraction、spark.shuffle.safetyFraction配置属性控制内存。
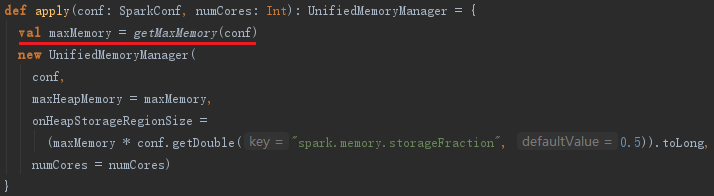
getMaxMemory方法用于获取shuffle所有线程占用的最大内存,实现如下:
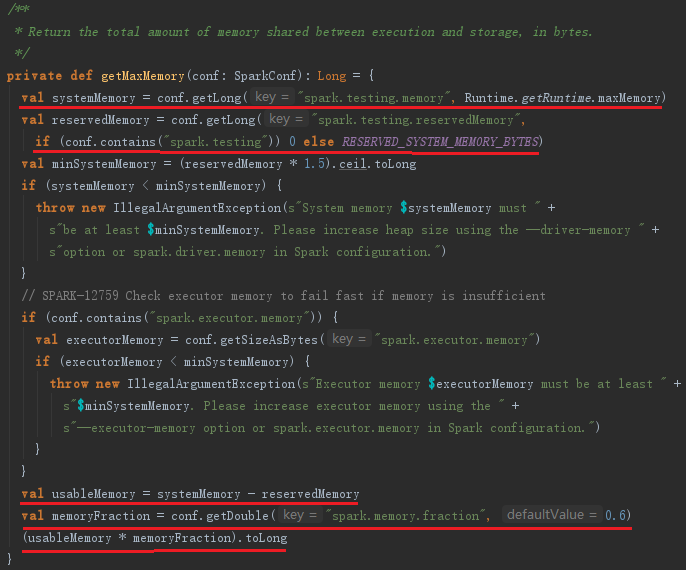
MemoryManager通常运行在Executor中,Driver中的MemoryManager只有在local模式下才起作用。
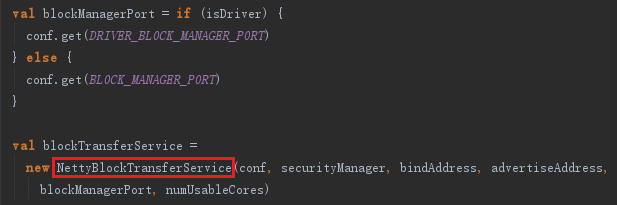
2.7 创建块传输服务BlockTransferService
BlockTransferService默认为NettyBlockTransferService,它使用Netty提供的异步事件驱动的网络应用框架,提供web服务及客户端,获取远程节点上Block的集合。
2.8 BlockManagerMaster介绍
BlockManagerMaster负责对Block的管理和协调,具体操作依赖于BlockManagerMasterEndpoint。Driver和Executor处理BlockManagerMaster的方式不同:
- 如果当前应用程序是Driver,则创建BlockManagerMasterEndpoint,并且注册到RpcEnv中。
- 如果当前应用程序是Executor,则从RpcEnv中找到BlockManagerMasterEndpoint。
无论是Driver还是Executor,最后BlockManagerMaster的属性driverEndpoint将持有对BlockManagerMasterEndpoint的引用。BlockManagerMaster的创建代码如下:

registerOrLookupEndpoint已在2.4出现过,不再介绍。
2.9 创建块管理器BlockManager
BlockManager负责对Block的管理,只有在BlockManager的初始化方法initialize调用后,它才是有效的。BlockManager是存储系统的一部分。BlockManager的创建代码如下:

2.10 创建测量系统MetricsSystem
MetricsSystem是Spark的测量系统,创建MetricsSystem的代码如下:

上面调用的createMetricsSystem方法实际创建了MetricsSystem,代码如下:

构造MetricsSystem的过程最重要的是调用了MetricsConfig的initialize方法,见代码如下:
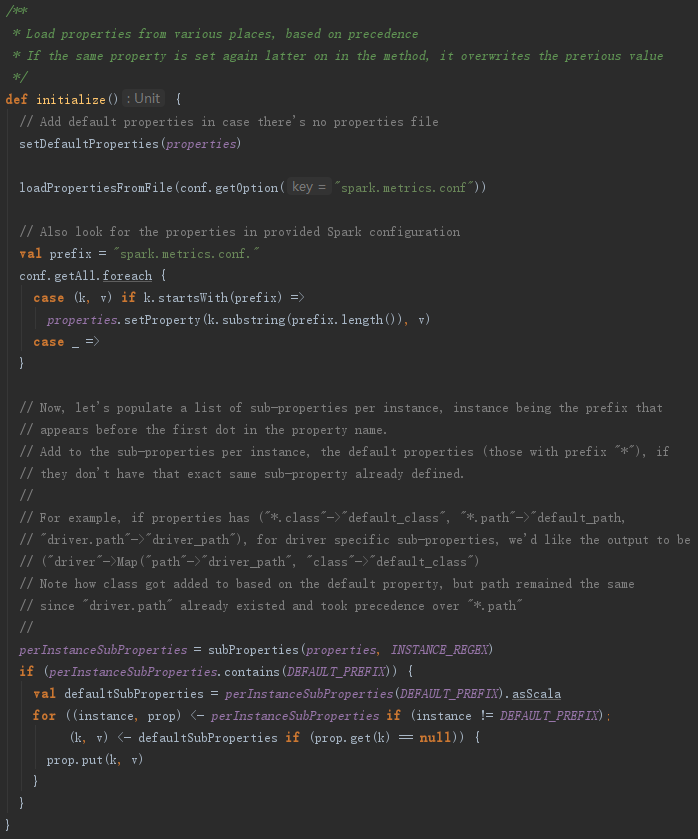
从以上实现可以看出,MetricsConfig的initialize方法主要负责加载metrics.properties文件中的属性配置,并对属性进行初始化转换。
例如,将属性
("*.sink.servlet.class"->"class1", "*.sink.servlet.path"->"path1")
转换为
Map("*" -> Properties("sink.servlet.class" -> "class1", "sink.servlet.path" -> "path1"))
2.11 创建SparkEnv
当所有的基础组件准备好后,最终使用下面的代码创建执行环境SparkEnv。
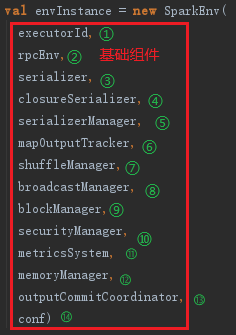
serializer和closureSerializer都是使用Class.forName反射生成的org.apache.spark.serializer.JavaSerializer类的实例,其中closureSerializer实例特别用来对Scala中的闭包进行序列化。
查看:Spark源码剖析——SparkContext的初始化
参考资料:
《深入理解Spark核心思想与源码分析》
Spark源码剖析 - SparkContext的初始化(二)_创建执行环境SparkEnv的更多相关文章
- Spark源码剖析 - SparkContext的初始化(三)_创建并初始化Spark UI
3. 创建并初始化Spark UI 任何系统都需要提供监控功能,用浏览器能访问具有样式及布局并提供丰富监控数据的页面无疑是一种简单.高效的方式.SparkUI就是这样的服务. 在大型分布式系统中,采用 ...
- Spark源码剖析 - SparkContext的初始化(五)_创建任务调度器TaskScheduler
5. 创建任务调度器TaskScheduler TaskScheduler也是SparkContext的重要组成部分,负责任务的提交,并且请求集群管理器对任务调度.TaskScheduler也可以看作 ...
- Spark源码剖析 - SparkContext的初始化(六)_创建和启动DAGScheduler
6.创建和启动DAGScheduler DAGScheduler主要用于在任务正式交给TaskSchedulerImpl提交之前做一些准备工作,包括:创建Job,将DAG中的RDD划分到不同的Stag ...
- Spark源码剖析 - SparkContext的初始化(九)_启动测量系统MetricsSystem
9. 启动测量系统MetricsSystem MetricsSystem使用codahale提供的第三方测量仓库Metrics.MetricsSystem中有三个概念: Instance:指定了谁在使 ...
- Spark源码剖析 - SparkContext的初始化(八)_初始化管理器BlockManager
8.初始化管理器BlockManager 无论是Spark的初始化阶段还是任务提交.执行阶段,始终离不开存储体系.Spark为了避免Hadoop读写磁盘的I/O操作成为性能瓶颈,优先将配置信息.计算结 ...
- Spark源码剖析 - SparkContext的初始化(一)
1. SparkContext概述 注意:SparkContext的初始化剖析是基于Spark2.1.0版本的 Spark Driver用于提交用户应用程序,实际可以看作Spark的客户端.了解Spa ...
- Spark源码剖析 - SparkContext的初始化(十)_Spark环境更新
12. Spark环境更新 在SparkContext的初始化过程中,可能对其环境造成影响,所以需要更新环境,代码如下: SparkContext初始化过程中,如果设置了spark.jars属性,sp ...
- Spark源码剖析 - SparkContext的初始化(七)_TaskScheduler的启动
7. TaskScheduler的启动 第五节介绍了TaskScheduler的创建,要想TaskScheduler发挥作用,必须要启动它,代码: TaskScheduler在启动的时候,实际调用了b ...
- Spark源码剖析 - SparkContext的初始化(四)_Hadoop相关配置及Executor环境变量
4. Hadoop相关配置及Executor环境变量的设置 4.1 Hadoop相关配置信息 默认情况下,Spark使用HDFS作为分布式文件系统,所以需要获取Hadoop相关配置信息的代码如下: 获 ...
随机推荐
- rt-thread中动态内存分配之小内存管理模块方法的一点理解
@2019-01-18 [小记] rt-thread中动态内存分配之小内存管理模块方法的一点理解 > 内存初始化后的布局示意 lfree指向内存空闲区首地址 /** * @ingroup Sys ...
- js多回调函数
多回调问题 前端编程时,大多通过接口交换数据,接口调用都是异步的,处理数据都是在回调函数里. 假如需要为一个用户建立档案,需要准备以下数据,然后调用建档接口 name // 用户名字 使用接口 ...
- 自适应PC端网页制作使用REM
做一个PC端的网页,设计图是1920X1080的. 要在常见屏上显示正常(比例正确可) 1280X720 1366X768 1440X900 1920X1080 使用了几种办法 1.内容在一屏内显示的 ...
- scrapy 基本命令
创建scrapy项目 scrapy startproject project_name 创建爬虫文件 scrapy genspider [-t template] <name> <d ...
- hdu 3374 String Problem(kmp+最小表示法)
Problem Description Give you a string with length N, you can generate N strings by left shifts. For ...
- 如何在jsp中引入bootstrap
如何在jsp中引入bootstrap包: 1.首先在http://getbootstrap.com/上下载Bootstrap的最新版. 您会看到两个按钮: Download Bootstrap:下载 ...
- 洛谷P1173 [NOI2016]网格
这个码量绝对是业界大毒瘤...... 300行,6.5k,烦的要死...... 题意:给你一个网格图,里面有0或1.你需要把一些0换成1使得存在某两个0不四联通.输出最小的换的数量.无解-1. n,m ...
- A1109. Group Photo
Formation is very important when taking a group photo. Given the rules of forming K rows with N peop ...
- A1013. Battle Over Cities
It is vitally important to have all the cities connected by highways in a war. If a city is occupied ...
- 登录rabbitmq报错User can only log in via localhost
在访问管理界面使用guest用户登录时出现login failed错误. 到服务器上查询日志显示出现错误的原因是:HTTP access denied: user ‘guest’ - User can ...