算法与数据结构基础 - 合并查找(Union Find)
Union Find算法基础
Union Find算法用于处理集合的合并和查询问题,其定义了两个用于并查集的操作:
- Find: 确定元素属于哪一个子集,或判断两个元素是否属于同一子集
- Union: 将两个子集合并为一个子集
并查集是一种树形的数据结构,其可用数组或unordered_map表示:

Find操作即查找元素的root,当两元素root相同时判定他们属于同一个子集;Union操作即通过修改元素的root(或修改parent)合并子集,下面两个图展示了id[6]由6修改为9的变化:
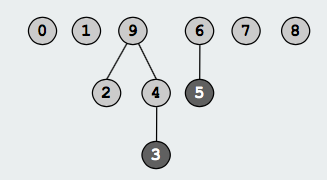
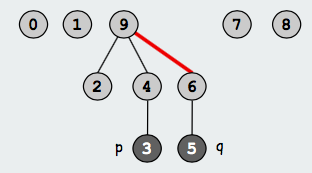
图片来源 这里
Union Find算法应用
Union Find可用于解决集合相关问题,如判断某元素是否属于集合、两个元素是否属同一集合、求解集合个数等,算法框架如下:
//261. Graph Valid Tree
bool validTree(int n, vector<pair<int, int>>& edges) {
vector<);
for(auto edge:edges){
//find查看两点是否已在同一集合
int x=find(num,edge.first);
int y=find(num,edge.second);
if(x==y) return false; //两点已在同一集合情况下则出现环
//union让两点加入同一集合
num[x]=y;
}
==edges.size();
}
int find(vector<int>&num,int i){
) return i;
return find(num,num[i]); //id[id[...id[i]...]]
}
一些情况下为清晰和解偶会将Uinon Find实现为一个类,独立出明显的Union和Find两个操作。
相关LeetCode题:
947. Most Stones Removed with Same Row or Column 题解
算法优化
有两种常用的方法用来降低并查集树形结构的高度、以减少Uinon Find算法的时间复杂度,这两种方法是:
Weighting(或称作Ranking): 使用多一个数组记录每个集合的size,Uinon时将size小的集合挂到size大的集合下,例如:
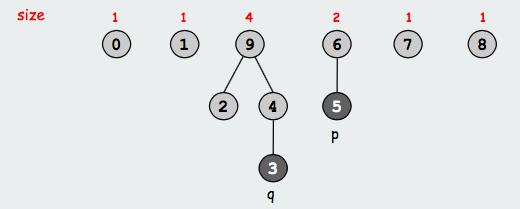
对3、5 Uinon,因3所在集合元素size 4大于5所在集合元素size 2,将6挂到9下而不是将9挂到6下。
Path compression: 对一个集合下的元素直接挂到root之下,而不是挂到其parent,path compression实现很简单只需在Find中加一行代码:
string find(unordered_map<string,string>& root,string s){
if(root[s]!=s)
root[s]=find(root,root[s]);
return root[s];
}
加入path compression也能实现减少并查集树高度的效果,图示如下:
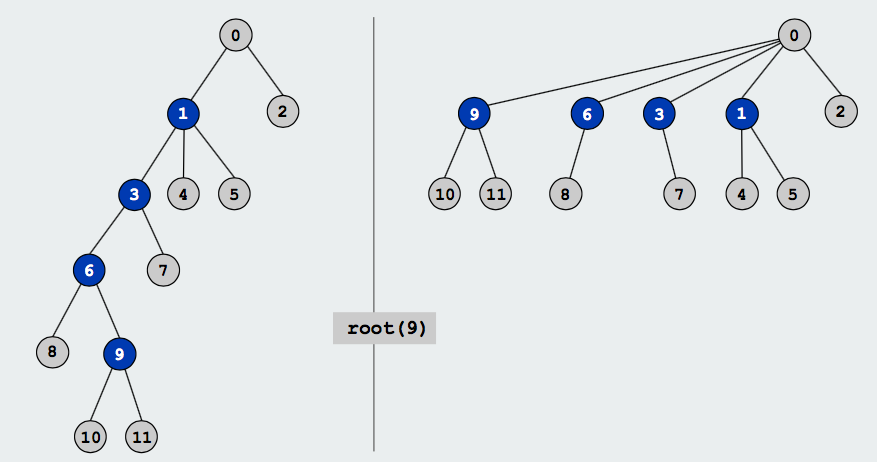
Weighting和Path compression两种方法可以同时使用,这样使得对N个元素进行M次Union Find操作的时间复杂度可以减少到 (M+N)lgN。因lgN随N的增长变化很小,所以整体算法时间复杂度接近于线性的时间复杂度。
相关LeetCode题:
924. Minimize Malware Spread 题解
算法与数据结构基础 - 合并查找(Union Find)的更多相关文章
- 算法与数据结构基础 - 折半查找(Binary Search)
Binary Search基础 应用于已排序的数据查找其中特定值,是折半查找最常的应用场景.相比线性查找(Linear Search),其时间复杂度减少到O(lgn).算法基本框架如下: //704. ...
- 算法与数据结构基础 - 图(Graph)
图基础 图(Graph)应用广泛,程序中可用邻接表和邻接矩阵表示图.依据不同维度,图可以分为有向图/无向图.有权图/无权图.连通图/非连通图.循环图/非循环图,有向图中的顶点具有入度/出度的概念. 面 ...
- 算法与数据结构基础 - 分治法(Divide and Conquer)
分治法基础 分治法(Divide and Conquer)顾名思义,思想核心是将问题拆分为子问题,对子问题求解.最终合并结果,分治法用伪代码表示如下: function f(input x size ...
- 算法与数据结构基础 - 数组(Array)
数组基础 数组是最基础的数据结构,特点是O(1)时间读取任意下标元素,经常应用于排序(Sort).双指针(Two Pointers).二分查找(Binary Search).动态规划(DP)等算法.顺 ...
- 算法与数据结构基础 - 堆(Heap)和优先级队列(Priority queue)
堆基础 堆(Heap)是具有这样性质的数据结构:1/完全二叉树 2/所有节点的值大于等于(或小于等于)子节点的值: 图片来源:这里 堆可以用数组存储,插入.删除会触发节点shift_down.shif ...
- 算法与数据结构基础 - 广度优先搜索(BFS)
BFS基础 广度优先搜索(Breadth First Search)用于按离始节点距离.由近到远渐次访问图的节点,可视化BFS 通常使用队列(queue)结构模拟BFS过程,关于queue见:算法与数 ...
- 算法与数据结构基础 - 哈希表(Hash Table)
Hash Table基础 哈希表(Hash Table)是常用的数据结构,其运用哈希函数(hash function)实现映射,内部使用开放定址.拉链法等方式解决哈希冲突,使得读写时间复杂度平均为O( ...
- 算法与数据结构基础 - 二叉树(Binary Tree)
二叉树基础 满足这样性质的树称为二叉树:空树或节点最多有两个子树,称为左子树.右子树, 左右子树节点同样最多有两个子树. 二叉树是递归定义的,因而常用递归/DFS的思想处理二叉树相关问题,例如Leet ...
- 算法与数据结构基础 - 双指针(Two Pointers)
双指针基础 双指针(Two Pointers)是面对数组.链表结构的一种处理技巧.这里“指针”是泛指,不但包括通常意义上的指针,还包括索引.迭代器等可用于遍历的游标. 同方向指针 设定两个指针.从头往 ...
随机推荐
- 性能测试即服务-docker部署jmeter及.netcore应用
前言 现在各种业务都追求上云,通俗的讲,“XX即服务”,作为一名专职的性能测试调优人员的我,由于会点三脚猫的开发功夫,“性能测试即服务”这种开发大任就落到我头上了,先做一个能完成核心压测功能的基础版. ...
- 从零开始基于go-thrift创建一个RPC服务
Thrift 是一种被广泛使用的 rpc 框架,可以比较灵活的定义数据结构和函数输入输出参数,并且可以跨语言调用.为了保证服务接口的统一性和可维护性,我们需要在最开始就制定一系列规范并严格遵守,降低后 ...
- JavaScript 之迭代方法
前言:关于 JS 中为数组定义的迭代方法,我最开始是在<JavaScript高级程序设计>中学习的,然后...我并没有看懂,后来翻阅各个大佬的博客,稍微理解了那么一丢丢.以下就是我的一点见 ...
- 跟着大彬读源码 - Redis 3 - 服务器如何响应客户端请求?(下)
继续我们上一节的讨论.服务器启动了,客户端也发送命令了.接下来,就要到服务器"表演"的时刻了. 1 服务器处理 服务器读取到命令请求后,会进行一系列的处理. 1.1 读取命令请求 ...
- flink window实例分析
window是处理数据的核心.按需选择你需要的窗口类型后,它会将传入的原始数据流切分成多个buckets,所有计算都在window中进行. flink本身提供的实例程序TopSpeedWindowin ...
- 手机如何进入开发者选项--以vivo为例
发现一个新方法 打开拨号键盘 输入 *#*#7777#*#* 欧儿了
- 多线程总结-同步之ReentrantLock
目录 1 ReentrantLock与synchronized对比 2.示例用法 2.1 基本用法 2.2 尝试锁 2.3 可打断 2.4 公平锁 1 ReentrantLock与synchroniz ...
- CDQZ集训DAY0 日记
貌似没发生什么事…… 按照教练员的交代,写一下流水账…… 早上5:30到了机场,然后就默默地坐着飞机到了成都.然后就按预定好的被GXY的父亲的朋友接机(貌似因为觉得GXY和他爸的同学挺像被批判一番). ...
- 快速掌握mongoDB(二)——聚合管道和MapReduce
上一节简单介绍了一下mongoDB的增删改查操作,这一节将介绍其聚合操作.我们在使用mysql.sqlserver时经常会用到一些聚合函数,如sum/avg/max/min/count等,mongoD ...
- blog更新
特别感谢: yu__xuan (啊这位着重感谢,多次帮助,于是帮他宣传一下https://www.cnblogs.com/poi-bolg-poi/) widerg 为两位大佬撒花~