Flume NG高可用集群搭建详解
、Flume NG简述
Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中。轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均衡。并且它拥有非常丰富的组件。Flume NG采用的是三层架构:Agent层,Collector层和Store层,每一层均可水平拓展。其中Agent包含Source,Channel和 Sink,三者组建了一个Agent。三者的职责如下所示:
•Source:用来消费(收集)数据源到Channel组件中
•Channel:中转临时存储,保存所有Source组件信息
•Sink:从Channel中读取,读取成功后会删除Channel中的信息
下图是Flume NG的架构图,如下所示: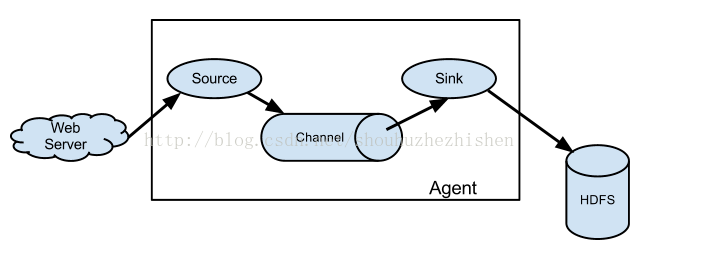
图中描述了,从外部系统(Web Server)中收集产生的日志,然后通过Flume的Agent的Source组件将数据发送到临时存储Channel组件,最后传递给Sink组件,Sink组件直接把数据存储到HDFS文件系统中。
2、单点Flume NG搭建、运行
我们在熟悉了Flume NG的架构后,我们先搭建一个单点Flume收集信息到HDFS集群中,由于资源有限,本次直接在之前的高可用Hadoop集群上搭建Flume。
场景如下:在NNA节点上搭建一个Flume NG,将本地日志收集到HDFS集群。
3、软件下载
在搭建Flume NG之前,我们需要准备必要的软件,具体下载地址 http://archive.apache.org/dist/flume/1.8.0/
http://mirror.bit.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
4、安装与配置
安装解压flume安装包,命令如下所示:
tar -zxvf apache-flume-1.8.0-bin.tar.gz
配置环境变量
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_92/
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar #set flume
export FLUME_HOME=/data/apps/apache-flume-1.8.0-bin
export PATH=$PATH:$FLUME_HOME/bin
source /etc/profile
cd /data/apps/apache-flume-1.8.0-bin/conf
修改 flume-env.sh配置如下:
export JAVA_HOME=/usr/java/jdk1.8.0_92/
flumr单节点配置文件设置如下:
flume-hdfs.conf
#agent1 name
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#Spooling Directory
#set source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/home/hadoop/flumetest/dir/logdfs
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#set sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://hadoopmaster:8020/flume/logdfs
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
agent1.sinks.sink1.hdfs.fileSuffix=.txt
#set channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/home/hadoop/flumetest/dir/logdfstmp/point
agent1.channels.channel1.dataDirs=/home/hadoop/flumetest/dir/logdfstmp
5、单节点flume启动
启动命令如下:
flume-ng agent --conf conf --conf-file /home/hadoop/cloud/programs/flume/conf/flume-hdfs.conf --name agent1 -Dflume.root.logger=INFO,console > /home/hadoop/cloud/programs/flume/logs/flume-hdfs.log 2>&1 &
注:命令中的agent1表示配置文件中的Agent的Name,如配置文件中的agent1。flume-hdfs.conf表示配置文件所在配置,需填写准确的配置文件路径。
6、单节点flume效果预览
在/home/hadoop/flumetest/dir/logdfs下编辑文件test.txt并任意写入内容,保存后,文件会立即上传hdfs,并被标记完成。

运行效果如下:

页面可查看已上传并重命名的文件:

7、高可用Flume NG搭建
在完成单点的Flume NG搭建后,下面我们搭建一个高可用的Flume NG集群,架构图如下所示:
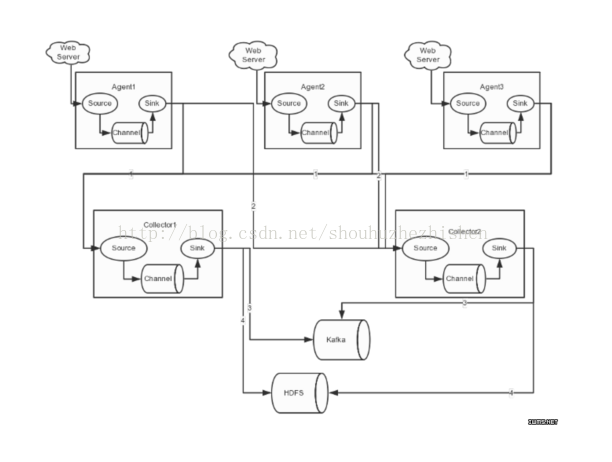
图中,我们可以看出,Flume的存储可以支持多种,这里只列举了HDFS和Kafka(如:存储最新的一周日志,并给Storm系统提供实时日志流)。
7.1、Flume的Agent和Collector分布如下表所示:
3台机器构建集群。Flume的Agent和Collector分布如下表所示:

图中所示,Agent1,Agent2,Agent3数据分别流入到Collector1和Collector2,Flume NG本身提供了Failover机制,可以自动切换和恢复。在上图中,有3个产生日志服务器分布在不同的机房,要把所有的日志都收集到一个集群中存储。下 面我们开发配置Flume NG集群
7.2、flume集群配置
配置Agent1,Agent2,Agent3,分别位于192.168.50.100-102三台机器,配置相同,如下所示:
flume-client.properties
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set gruop
agent1.sinkgroups = g1
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /home/hadoop/flumetest/dir/logdfs/flumetest.log
agent1.sources.r1.interceptors = i1 i2
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = Type
agent1.sources.r1.interceptors.i1.value = LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp
# set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = hadoopmaster
agent1.sinks.k1.port = 52020
# set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = hadoopslave1
agent1.sinks.k2.port = 52020
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 10000
配置Collector1和Collector2,分别位于192.168.50.100-101两台台机器,绑定的IP(或主机名)不同,需要修改为各自所在机器的IP(或主机名)
192.168.50.100(hadoopmaster)的flume-server.properties配置如下:
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoopmaster
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoopmaster
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://hadoopmaster:8020/flume/logdfs
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=1
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
a1.sinks.k1.hdfs.fileSuffix=.txt
192.168.50.101(hadoopslave1)的flume-server.properties配置如下:
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoopslave1
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoopslave1
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://hadoopmaster:8020/flume/logdfs
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=1
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
a1.sinks.k1.hdfs.fileSuffix=.txt
7.3、flume集群启动
在Collector各节点上启动命令如下所示:
flume-ng agent --conf conf --conf-file /home/hadoop/cloud/programs/flume/conf/flume-server.properties --name a1 -Dflume.root.logger=INFO,console > /home/hadoop/cloud/programs/flume/logs/flume-server.log 2>&1 &
注:命令中的a1表示配置文件中的Agent的Name,如配置文件中的a1。flume-server.properties表示配置文件所在配置,需填写准确的配置文件路径。
在Agent各节点上启动命令如下所示:
flume-ng agent --conf conf --conf-file /home/hadoop/cloud/programs/flume/conf/flume-client.properties --name agent1 -Dflume.root.logger=INFO,console > /home/hadoop/cloud/programs/flume/logs/flume-client.log 2>&1 &
注:命令中的agent1表示配置文件中的Agent的Name,如配置文件中的agent1。flume-client.properties表示配置文件所在配置,需填写准确的配置文件路径。
7.4、Flume NG集群的高可用(故障转移)测试
场景如下:我们在Agent1节点上传文件,由于我们配置Collector1的权重比Collector2大,所以 Collector1优先采集并上传到存储系统。然后我们kill掉Collector1,此时有Collector2负责日志的采集上传工作,之后,我 们手动恢复Collector1节点的Flume服务,再次在Agent1上次文件,发现Collector1恢复优先级别的采集工作。具体截图如下所 示:
Collector1优先上传: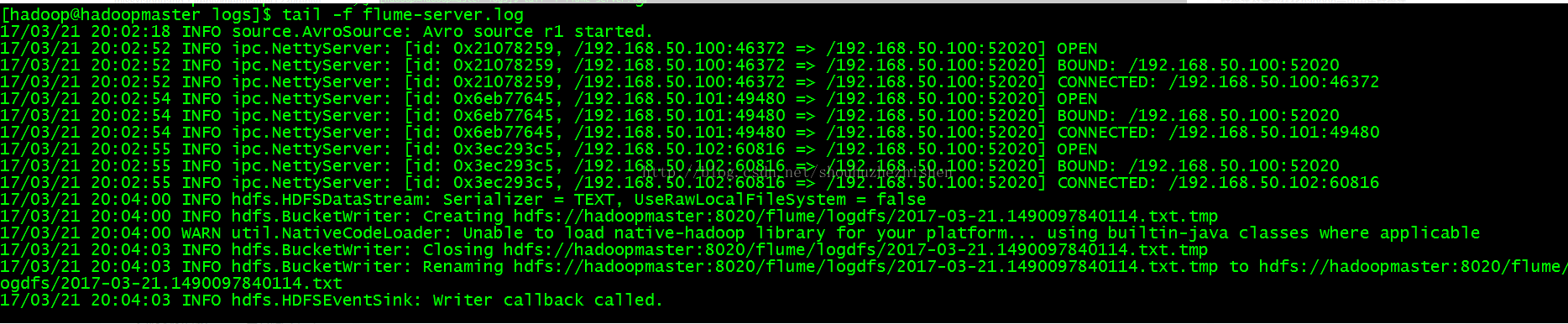
HDFS集群中上传的log内容预览:

Collector1宕机,Collector2获取优先上传权限:

HDFS文件系统中的截图预览:
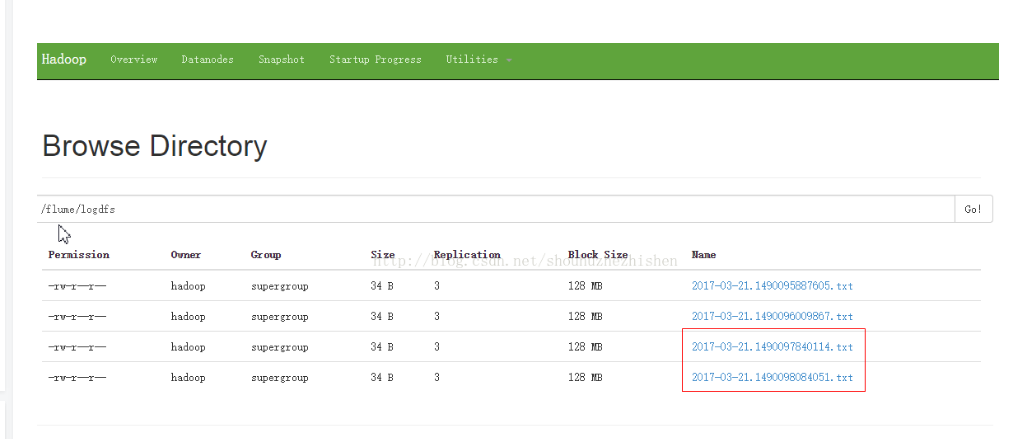
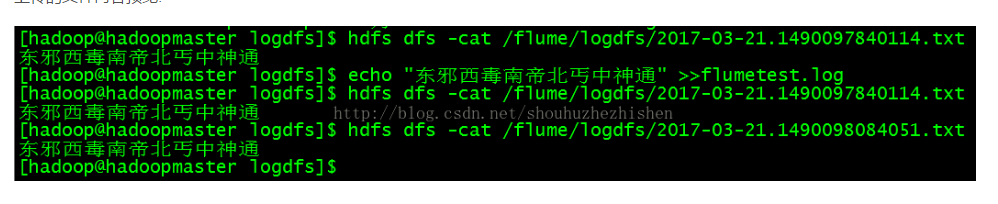
上传的文件内容预览:
8、总结
在配置高可用的Flume NG时,需要注意一些事项。在Agent中需要绑定对应的Collector1和Collector2的IP和Port,另外,在配置Collector 节点时,需要修改当前Flume节点的配置文件,Bind的IP(或HostName)为当前节点的IP(或HostName),最后,在启动的时候,指定配置文件中的Agent的Name和配置文件的路径,否则会出错。
Flume NG高可用集群搭建详解的更多相关文章
- Flume 学习笔记之 Flume NG高可用集群搭建
Flume NG高可用集群搭建: 架构总图: 架构分配: 角色 Host 端口 agent1 hadoop3 52020 collector1 hadoop1 52020 collector2 had ...
- 高可用集群(crmsh详解)http://www.it165.net/admin/html/201404/2869.html
crmsh是pacemaker的命令行接口工具,执行help命令,可以查看shell接口所有的一级命令和二级命令,使用cd 可以切换到二级子命令的目录中去,可以执行二级子命令 在集群中的资源有四类:p ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- MongoDB高可用集群搭建(主从、分片、路由、安全验证)
目录 一.环境准备 1.部署图 2.模块介绍 3.服务器准备 二.环境变量 1.准备三台集群 2.安装解压 3.配置环境变量 三.集群搭建 1.新建配置目录 2.修改配置文件 3.分发其他节点 4.批 ...
- RabbitMQ高级指南:从配置、使用到高可用集群搭建
本文大纲: 1. RabbitMQ简介 2. RabbitMQ安装与配置 3. C# 如何使用RabbitMQ 4. 几种Exchange模式 5. RPC 远程过程调用 6. RabbitMQ高可用 ...
- spring cloud 服务注册中心eureka高可用集群搭建
spring cloud 服务注册中心eureka高可用集群搭建 一,准备工作 eureka可以类比zookeeper,本文用三台机器搭建集群,也就是说要启动三个eureka注册中心 1 本文三台eu ...
随机推荐
- XMPP开发adiumclient登陆
我写在前面client它已经实现了登陆,我用下面的adium要登录落实的朋友加入,而自己写的client在聊天帐号. 第一次登录时adium工欲善其事,必先例如,下面的配置 保存后.你会发现自己的账号 ...
- 下面介绍一个 yii2.0 的 Rbac 权限设置,闲话少说,直接上代码,
1.首先我们要在组件里面配置一下 Rbac ,如下所示(common/config/main-local.php或者main.php). 'authManager' => [ 'class' ...
- Multiple address space mapping technique for shared memory wherein a processor operates a fault handling routine upon a translator miss
Virtual addresses from multiple address spaces are translated to real addresses in main memory by ge ...
- jquery即点击改
$(document).on("click",".sp",function(){ var brand_id=$(this).attr("valu ...
- 我已经写了DAL层的代码生成器
(1)创建您自己的解决方案 文件夹结构如以下: (2)编写代码: (要使用数据库 建议创建随意数据库就可以) 创建配置文件App.config代码例如以下: <?xml version=&quo ...
- android游戏开发系列(1)——迅雷不及掩耳的声音
这种声音是短而快的声音,应该采用android.media.SoundPool实现. SoundPool的特点: 1. SoundPool载入音乐文件使用了独立的线程,不会阻塞UI主线程的操作.但是这 ...
- oracle授权grant
alter any cluster 修改任意簇的权限 alter any index 修改任意索引的权限 alter any role 修改任意角色的权限 alter any sequence 修改任 ...
- windown下linux子系统的安装和卸载
原文:windown下linux子系统的安装和卸载 安装 第一步 打开开发人员模式 第二步 勾选适用linux的window子系统 第三步 打开powershell 第四步 在PowerShe ...
- 【狼窝乀野狼】Windows Server 2008 R 配置 Microsoft Server 2008 远程登录连接
如果你已经了解了,或者你已经经历了,那么此篇文章对你是毫无用处.因为文笔深处未必有自己亲身体验来的真实有效. 闲话少说,直接上菜. 最近脑子“抽筋”,想安装一个服务器来玩玩,那么怎么选择呢?我的PC是 ...
- java程序设计第二课
抽象基类和接口 能够使用keywordabstact来创建抽象类,该抽象类不能被实例化 也能够使用keywordabstact来描写叙述一个尚未被详细实现的方法,该方法不能包括方法体 一个抽象方法仅仅 ...