大数据小白系列——HDFS(2)
这里是大数据小白系列,这是本系列的第二篇,介绍一下HDFS中SecondaryNameNode、单点失败(SPOF)、以及高可用(HA)等概念。
上一篇我们说到了大数据、分布式存储,以及HDFS中的一些基本概念,为了能更好的理解后续介绍的内容,这里先补充介绍一下NameNode到底是怎么存储元数据的。

首先,在启动的时候,将磁盘中的元数据文件读取到内存,后续所有变化将被直接写入内存,同时被写入一个叫Edit Log的磁盘文件。(如果你熟悉关系型数据库,这个Edit Log有点像Oracle Redo Log,这是题外话)。
Q: 为什么不把这些变化直接写到磁盘上的元数据中,使磁盘上的元数据保持最新呢?Edit Log是不是多此一举?
A: 这个主要是基于性能考虑,由于对Edit Log的写是“顺序写”(追加),对元数据的写是“随机写”,两者在磁盘上表现出来的性能有相当大的差异。有兴趣的同学可以搜索学习一下磁盘相关原理哦。
上面这个方案,带来了一些明显的副作用。
- NameNode长期运行,不停地向Edit Log追加内容,导致它变得巨大无比。
- NameNode在重启时,需要使用Edit Log更新元数据文件,当Edit Log太大时,这一步骤就会耗费很长的时间。
为了消除这些副作用,HDFS中引入了另外一个角色,SecondaryNameNode。
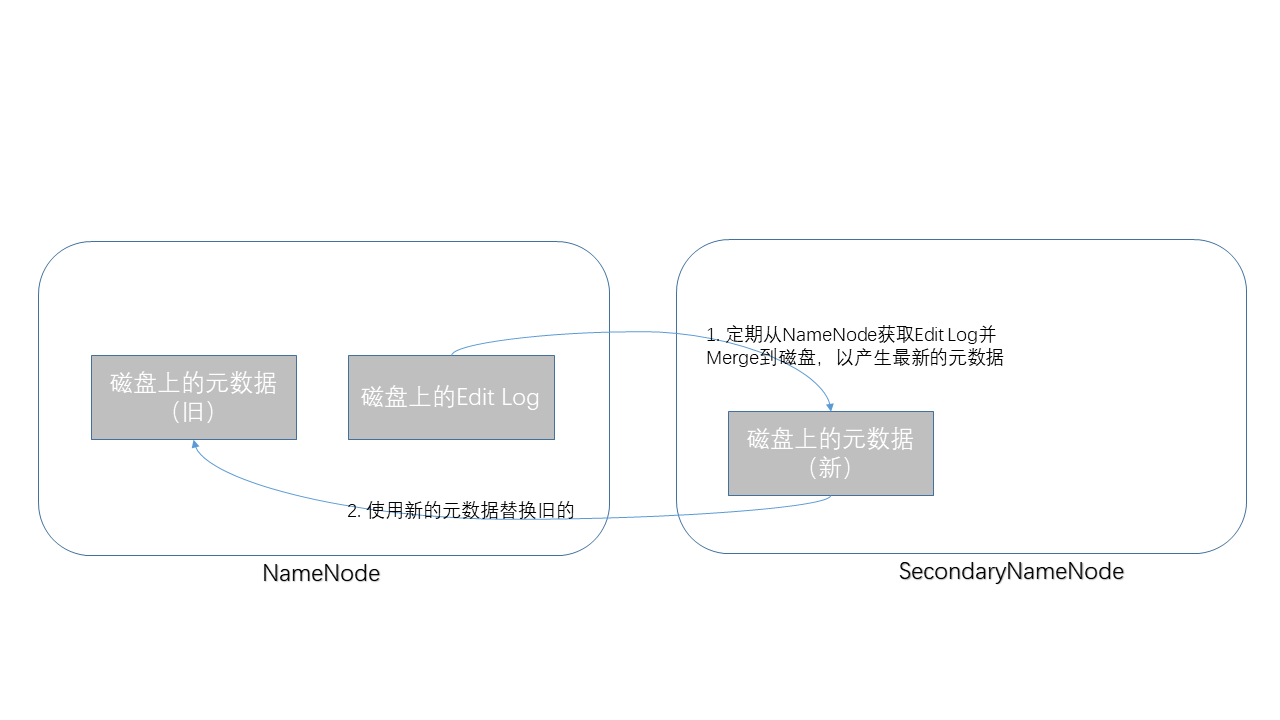
它定期(比如每小时)从NameNode上抓取Edit Log,使用它更新元数据文件,并把最新的元数据文件写回到NameNode。
说完了SecondaryNameNode的职责之后,大家应该明白,它并不是一个“备用NameNode”,其实这是典型的命名不当,它应该被命名成“Checkpoint NameNode”才比较恰当。
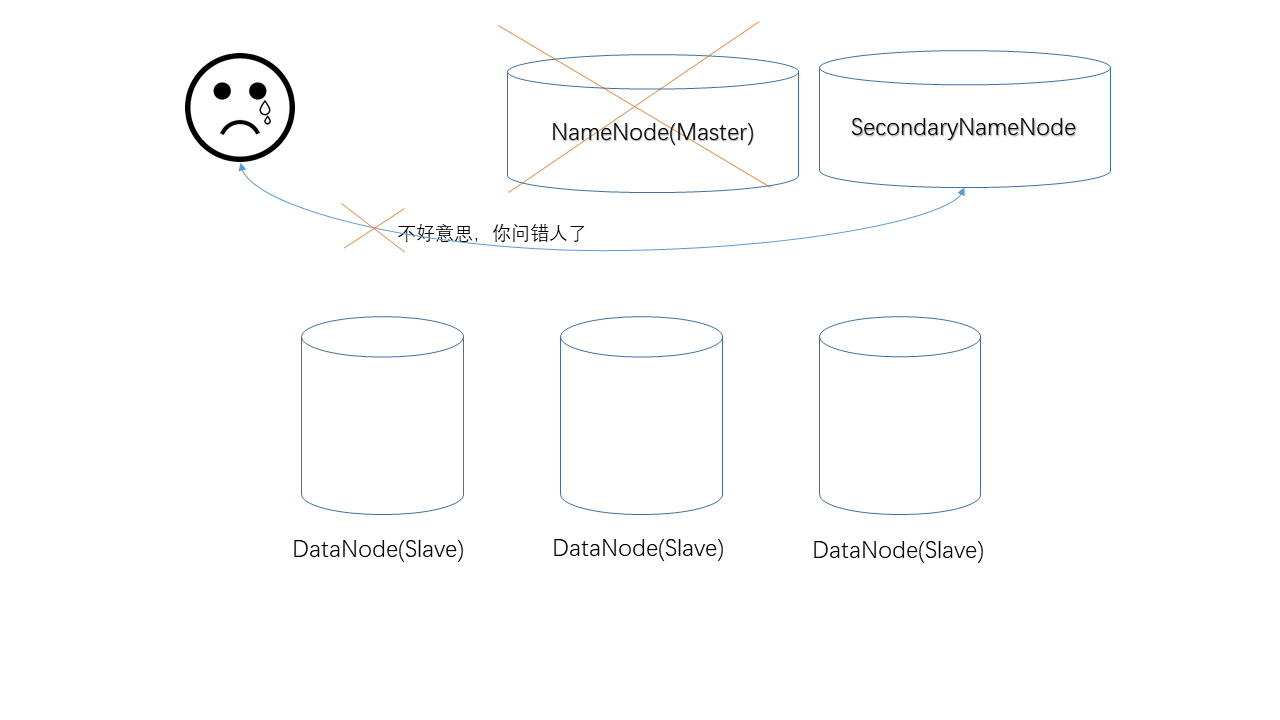
接下来我们来说说HDFS中的单点失败问题(SPOF, Single Point Of Failure),即,当NameNode掉线之后,整个HDFS集群就变得不可用了。为解决这个问题,Hadoop 2.0中真正引入了一个“备用NameNode”。
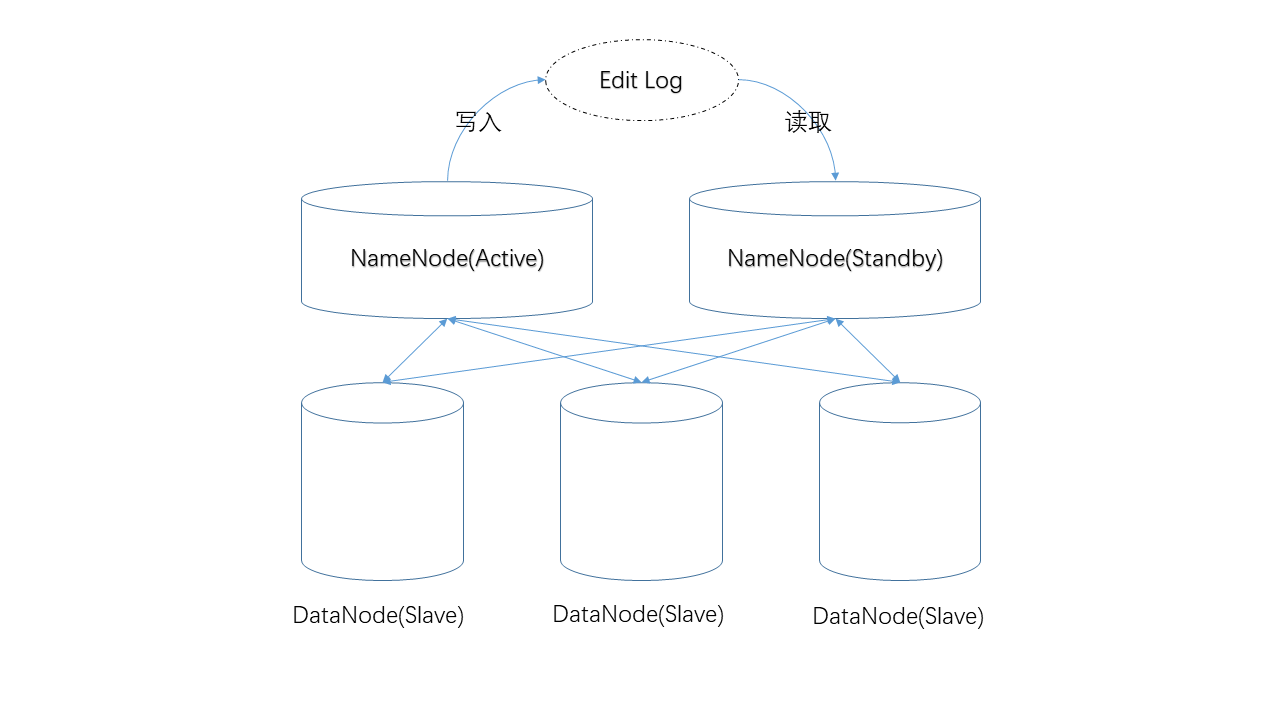
- 对元数据的修改首先发生在NameNode,并被写入某个“共享位置”,备用NameNode将从该位置获取Edit Log。
- DataNode节点们同时向两台NameNode汇报状态。
由于这两点,两台NameNode上的元数据将一直保持同步。这将保证当NameNode掉线后,用户可以立即切换到备用NameNode,系统将保持可用。
由于备用NameNode比较空闲(不用处理用户请求),系统又给它安排了另外一份工作——定期使用Edit Log更新元数据文件,也就是说它接手了SecondaryNameNode的工作。
所以,在HA环境中,我们就不再需要SecondaryNameNode了。
今天就到这里,下一篇准备介绍JournalNode、NameNode选举等概念,Cheers!
公众号“程序员杂书馆”,专注大数据,欢迎关注,每位关注者将获赠《Spark快速大数据分析》纸质书一本!


大数据小白系列——HDFS(2)的更多相关文章
- 大数据小白系列——HDFS(4)
这里是大数据小白系列,这是本系列的第四篇,来看一个真实世界Hadoop集群的规模,以及我们为什么需要Hadoop Federation. 首先,我们先要来个直观的印象,这是你以为的Hadoop集群: ...
- 大数据小白系列——HDFS(3)
这里是大数据小白系列,这是本系列的第三篇,介绍HDFS中NameNode选举,JournalNode等概念. 上一期我们说到了为解决NameNode(下称NN)单点失败问题,HDFS中使用了双NN的机 ...
- 大数据小白系列——HDFS(1)
[注1:结尾有大福利!] [注2:想写一个大数据小白系列,介绍大数据生态系统中的主要成员,理解其原理,明白其用途,万一有用呢,对不对.] 大数据是什么?抛开那些高大上但笼统的说法,其实大数据说的是两件 ...
- 大数据小白系列——MR(1)
一部编程发展史就是一部程序员偷懒史,MapReduce(下称MR)同样是程序员们用来偷懒的工具. 来了一份大数据,我们写了一个程序准备分析它,需要怎么做? 老式的处理方法不行,数据量太大时,所需的时间 ...
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
随机推荐
- java多线程快速入门(二十)
1.Java.util的线程安全工具类 Vector(线程安全) ArrayList(线程不安全) HashTable(线程安全) HashMap(线程不安全) 2.将线程不安全集合变为线程安全集合 ...
- WEB漏洞 XSS(一)
1.xss的形成原理 xss 中文名是“跨站脚本攻击”,英文名“Cross Site Scripting”.xss也是一种注入攻击,当web应用对用户输入过滤不严格,攻击者写入恶意的脚本代码(HTML ...
- bzoj2200拓扑排序+最短路+联通块
自己写的不知道哪里wa了,明明和网上的代码差不多.,. /* 给定一张图,有的边是无向边,有的是有向边,有向边不会出现在环中,且有可能是负权值 现在给定起点s,求出s到其余所有点的最短路长度 任何存在 ...
- Nginx详解十五:Nginx场景实践篇之负载均衡
负载均衡 GSLB(全局的负载均衡,往往是以国家为单位,或者以省为单位) SLB Nginx就是一个典型的SLB模型, 分为四层负载均衡和七层负载均衡 七层负载均衡可以处理应用层,如thhp信息,Ng ...
- requests中get和post传参
get请求 get(url, params=None, **kwargs) requests实现get请求传参的两种方式 方式一: import requests url = 'http://www. ...
- python字典操作用法总结
基本语法: dict = {'ob1':'computer', 'ob2':'mouse', 'ob3':'printer'} 技巧: 字典中包含列表:dict={'yangrong':['23',' ...
- Eclipes导入工程
1.在eclipes中导入其他的一些工程后往往会出错,修改意见是 在project.properties该文件下修改 这个target是你的sdk中已经下载好的 查看: 右键目标工程,选择proper ...
- Python学生信息管理系统的开发
# 第一题:设计一个全局变量,来保存很多个学生信息:学生(学号, 姓名,年龄):思考要用怎样的结构来保存:# 第二题:在第一题基础上,完成:让用户输入一个新的学生信息(学号,姓名,年龄):你将其保存在 ...
- HDU 1452 Happy 2004(因数和+费马小定理+积性函数)
Happy 2004 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total ...
- CORS跨域
一:简介 为什么会出现跨域问题? 受同源策略影响,不同域名之间不可以进行访问.同源策略(Same-Origin Policy).所谓的 同源 是指域名.协议.端口号 相同.不同的客户端脚本(JavaS ...