Hadoop详解(04-1) - 基于hadoop3.1.3配置Windows10本地开发运行环境
Hadoop详解(04-1) - 基于hadoop3.1.3配置Windows10本地开发运行环境
环境准备
- 安装jdk环境
- 安装idea
- 配置maven
- 搭建好的hadoop集群
配置hadoop
- 解压hadoopo
将hadoop压缩包hadoop-3.1.3.tar.gz解压到本地任意目录

- 拷贝Windows依赖到本地目录
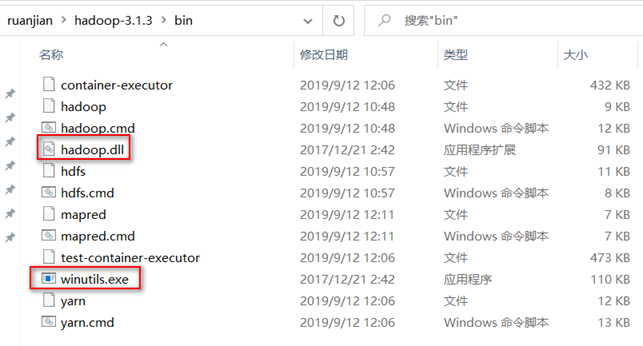
Hadoop的Windows依赖说明
hadoop在windows上运行需要winutils支持和hadoop.dll等文件,hadoop主要基于linux编写,hadoop.dll和winutil.exe主要用于模拟linux下的目录环境,如果缺少这两个文件在本地调试MR程序会报错
缺少winutils.exe
Could not locate executable null \bin\winutils.exe in the hadoop binaries
缺少hadoop.dll
Unable to load native-hadoop library for your platform… using builtin-Java classes where applicable
Windows依赖文件官方没有直接提供,需要自行下载。
如在gitubxiaz(版本不全) https://github.com/4ttty/winutils
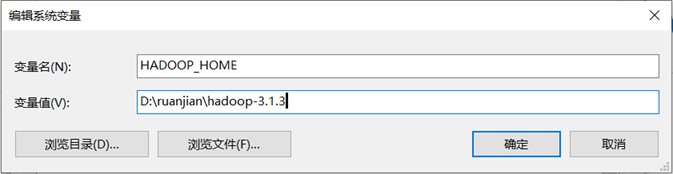
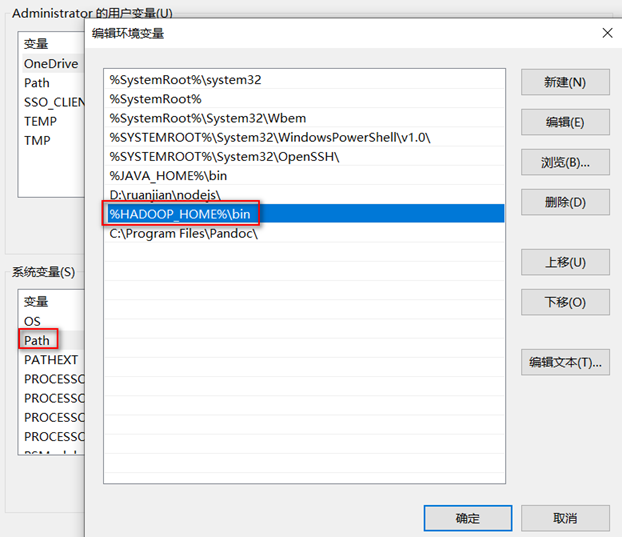
- 配置环境变量
添加HADOOP_HOME并编辑Path的值
- 查看hadoop版本
通过查看hadoop版本确认windows下的hadoop环境变量配置是否成功
C:\Users\Administrator> hadoop version

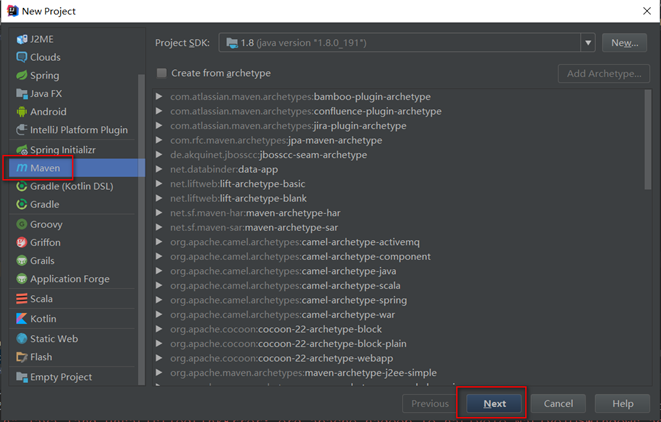
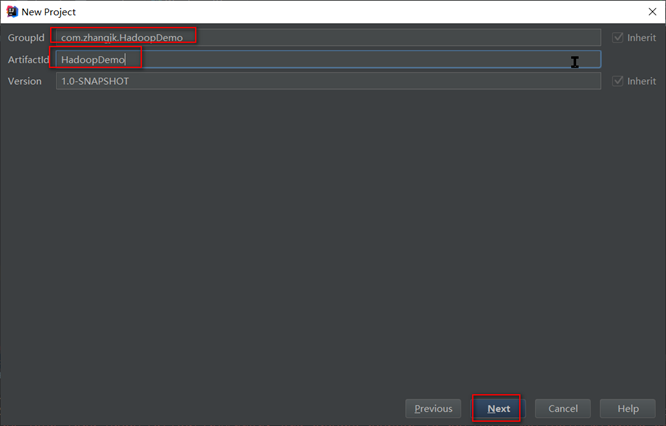
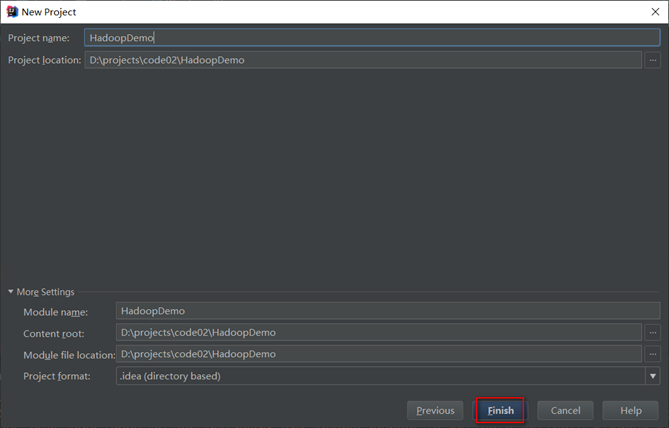
创建项目
- 创建maven项目HadoopDemo
- 导入相应的依赖坐标
在pom.xml文件中添加依赖坐标
Hadoop开发环境只需要引入hadoop-client即可,hadoop-client的依赖关系已经包含了client、common、hdfs、mapreduce、yarn等模块
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
- 和添加日志
在项目的src/main/resources目录下,新建一个文件,命名为"log4j2.xml",在文件中填入
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型名为Console,名称为必须属性 -->
<Appender type="Console" name="STDOUT">
<!-- 布局为PatternLayout的方式,
输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- 可加性为false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig设置 -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>
本地测试hdfs
- 需求
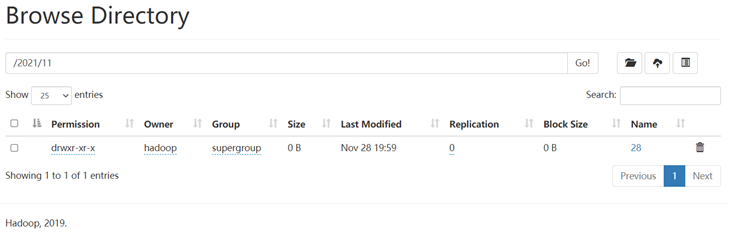
在hdfs中创建目录:/1128/daxian/banzhang
- 创建包名:com.zhangjk.hdfs
- 创建HdfsClient类并编写代码
- package com.zhangjk.hdfs;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.junit.Test;
- import java.io.IOException;
- import java.net.URI;
- import java.net.URISyntaxException;
- /**
- * @author : 张京坤
- * mail:zhangjingkun88@126.com
- * date: 2021/11/28
- * project name: HdfsClientDemo
- * package name: com.zhangjk.hdfs
- * content:
- * @version :1.0
- */
- public class HdfsClient {
- @Test
- public void testMkdirs() throws IOException, InterruptedException, URISyntaxException {
- // 1 获取文件系统
- Configuration configuration = new Configuration();
- FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9820"), configuration, "hadoop");
- // 2 创建目录
- fs.mkdirs(new Path("/1128/daxian/banzhang"));
- // 3 关闭资源
- fs.close();
- }
- }
- 要配置用户名称
客户端去操作HDFS时,是有一个用户身份的。默认情况下,HDFS客户端API会从JVM中获取一个参数来作为自己的用户身份:通过在VM options中设置参数-DHADOOP_USER_NAME=hadoop,hadoop为用户名称。
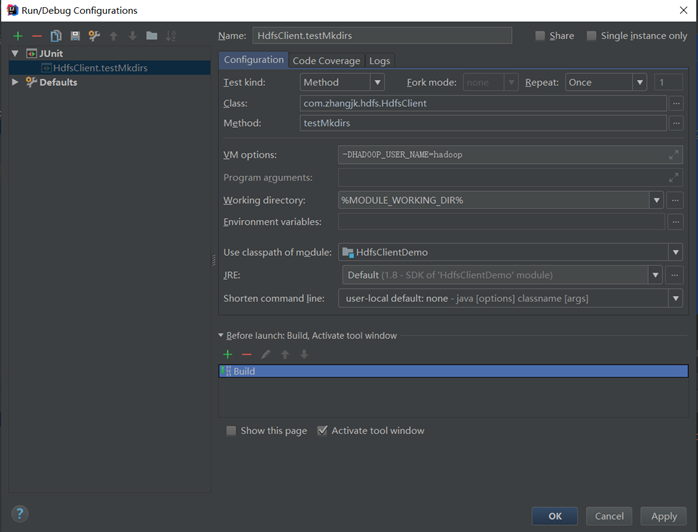
- 执行程序
运行程序并查看结果
本地测试MR程序WordCount
- 需求
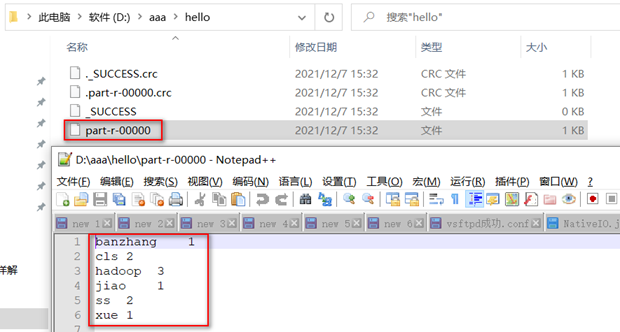
在给定的文本文件hello.txt中统计输出每一个单词出现的总次数
hello.txt文件中的内容
hadoop hadoop
ss ss
cls cls
jiao
banzhang
xue
hadoop
期望输出数据
hadoop 2
banzhang 1
cls 2
hadoop 1
jiao 1
ss 2
xue 1
- 需求分析
按照MapReduce编程规范,分别编写Mapper,Reducer,Driver。
输入数据
hadoop hadoop
ss ss
cls cls
jiao
banzhang
xue
hadoop
输出数据
hadoop 2
banzhang1
cls 2
hadoop 1
jiao 1
ss 2
xue 1
Mapper阶段
1 将MapTask传过来的文本内容先转换成String
hadoop hadoop
2 根据空格将这一行切分成单词
hadoop
hadoop
3 将单词输出为<单词,1>
hadoop, 1
hadoop, 1
Reducer阶段
1 汇总各个key的个数
hadoop, 1
hadoop, 1
2 输出该key的总次数
hadoop, 2
Driver阶段
1 获取配置信息,获取job对象实例
2 指定本程序的jar包所在的本地路径
3 关联Mapper/Reducer业务类
4 指定Mapper输出数据的kv类型
5 指定最终输出的数据的kv类型
6 指定job的输入原始文件所在目录
7 指定job的输出结果所在目录
8 提交作业
- 创建包名:com.zhangjk.mapreduce
创建WordcountMapper、WordcountReducer、WordcountDriver类并编写代码
Mapper
- package com.zhangjk.mapreduce;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Mapper;
- import java.io.IOException;
- /**
- * @author : 张京坤
- * mail:zhangjingkun88@126.com
- * date: 2021/12/2
- * project name: HdfsClientDemo
- * package name: com.zhangjk.mapreduce
- * content:
- * @version :1.0
- */
- public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
- //常见kv对变量
- Text k = new Text();
- IntWritable v = new IntWritable(1);
- @Override
- protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- //获取一行
- String line = value.toString();
- //切割
- String[] words = line.split(" ");
- //输出
- for (String word : words) {
- k.set(word);
- context.write(k, v);
- }
- }
- }
Reducer
- package com.zhangjk.mapreduce;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Reducer;
- import java.io.IOException;
- /**
- * @author : 张京坤
- * mail:zhangjingkun88@126.com
- * date: 2021/12/2
- * project name: HdfsClientDemo
- * package name: com.zhangjk.mapreduce
- * content:
- * @version :1.0
- */
- public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
- int sum;
- IntWritable v = new IntWritable();
- @Override
- protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
- //累加求和
- sum = 0;
- for (IntWritable value : values) {
- sum += value.get();
- }
- //输出
- v.set(sum);
- context.write(key, v);
- }
- }
Driver驱动类
- package com.zhangjk.mapreduce;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import java.io.IOException;
- /**
- * @author : 张京坤
- * mail:zhangjingkun88@126.com
- * date: 2021/12/2
- * project name: HdfsClientDemo
- * package name: com.zhangjk.mapreduce
- * content:
- * @version :1.0
- */
- public class WordcountDriver {
- public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
- //1 获取配置信息和job对象
- Configuration configuration = new Configuration();
- Job job = Job.getInstance(configuration);
- //2 关联本Dirver程序的jar
- job.setJarByClass(WordcountDriver.class);
- //3 关联Mapper和Reducer的jar
- job.setMapperClass(WordcountMapper.class);
- job.setReducerClass(WordcountReducer.class);
- //4 设置Mapper输出的kv类型
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- //5 设置最终输出的kv类型
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- //6 设置输入和输出路径
- FileInputFormat.setInputPaths(job, new Path(args[0]));
- FileOutputFormat.setOutputPath(job, new Path(args[1]));
- //7 提交job
- boolean result = job.waitForCompletion(true);
- System.out.println(result);
- }
- }
- 运行测试
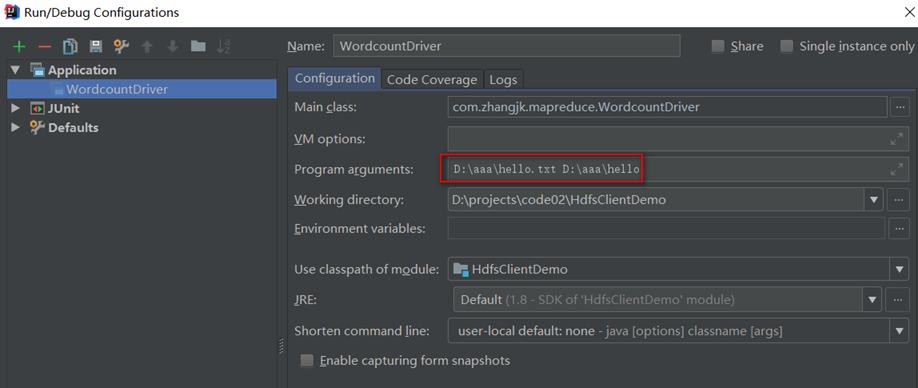
配置agrs参数
在启动类配置的Program agtuments中分别设置input 和output 并用空格分隔
解决报错:
启动WordcountDriver类时会遇到如下错误信息:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
错误日志信息
- Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
- at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
- at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:640)
- at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:1223)
- at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:160)
- at org.apache.hadoop.util.DiskChecker.checkDirInternal(DiskChecker.java:100)
- at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:77)
- at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:315)
- at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:378)
- at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:152)
- at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:133)
- at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:117)
- at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:124)
- at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:172)
- at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:788)
- at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:251)
- at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1570)
- at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1567)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:422)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
- at org.apache.hadoop.mapreduce.Job.submit(Job.java:1567)
- at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1588)
- at com.zhangjk.mapreduce.WordcountDriver.main(WordcountDriver.java:47)
错误原因:
在新版本的windows系统中,会取消部分文件,某些功能无法支持。本地的NativeIO无法写入
解决方法:再写一个NativeIO类替代源代码
操作步骤:
- 在项目的java目录下重建一个org.apache.hadoop.io.nativeio包和NativeIO类
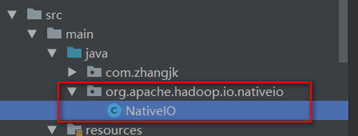
- 按2次shift查找NativeIO类
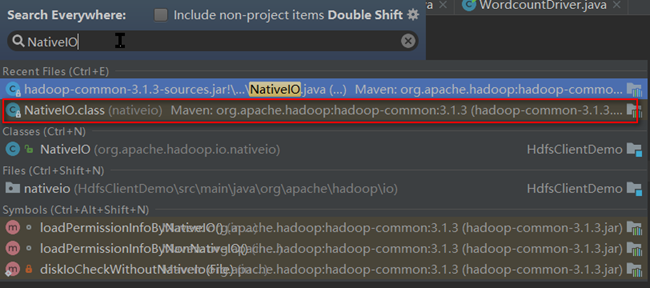
- 选择hadoop-common jar包中的org.apache.hadoop.io.nativeio.NativeIO类进入到对应的源码文件,如果没有下载源码,则需要点击Download Sources下载源码
- 在源代码的org.apache.hadoop.io.nativeio.NativeIO类中Ctrl+a全选,Ctrl+c复制所有代码
- 将复制的代码覆盖到第1步创建的NativeIO类中(Ctrl+a全选,Ctrl+v粘贴)
- Ctrl+f查找return access0
- 将本行代码修改成return true;

再次运行查看结果
再次启动WordcountDriver类,已没有错误信息并正常查看日志,进入到output输出目录查看运行结果
集群测试MR程序WordCount
- 在pom.xml中添加用maven打jar包所需要的打包插件依赖
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
注意:如果工程上显示红叉。在项目上右键->maven->Reimport即可
- 程序打成jar包
使用maven插件对项目打包
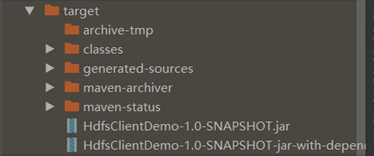
等待编译完成就会在项目的target文件夹中生成jar包
如果看不到。在项目上右键->Refresh即可
其中
HdfsClientDemo-1.0-SNAPSHOT.jar为不带依赖的jar包
HdfsClientDemo-1.0-SNAPSHOT-jar-with-dependencies.jar是带依赖的jar包
修改不带依赖的jar包名称为wc.jar,并拷贝该jar包到Hadoop集群
hadoop集群上已经包含了执行MR程序所需要的依赖,所以在集群上运行MR程序时选择不带依赖的jar包
上传hello.txt文件到hdfs
[hadoop@hadoop102 ~]$ hadoop fs -put /home/hadoop/hello.txt /user/hadoop
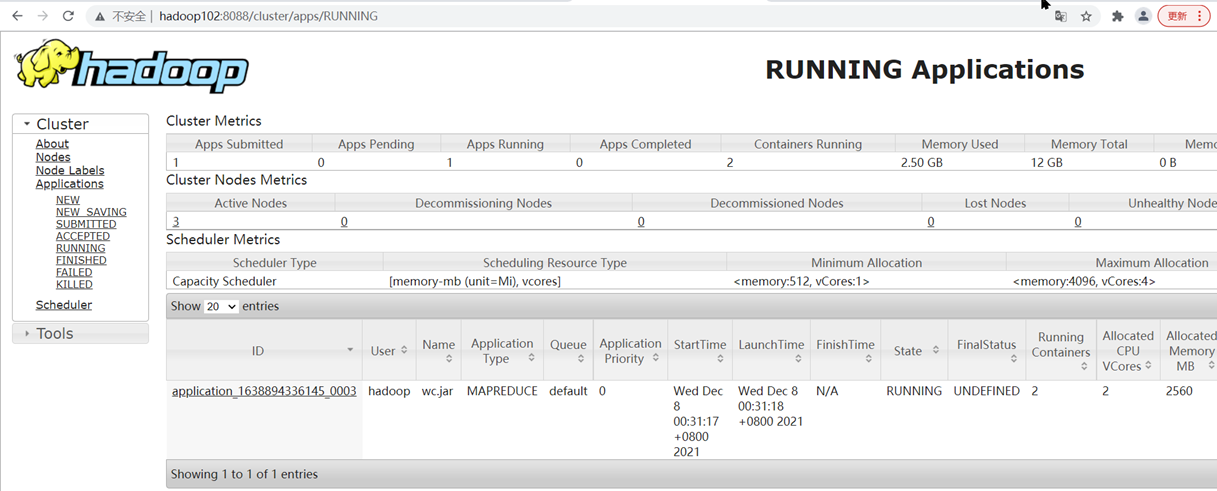
提交任务
[hadoop@hadoop102 ~]$ hadoop jar wc.jar com.zhangjk.mapreduce.WordcountDriver /user/hadoop/hello.txt /user/hadoop/output
在yarn平台上查看正在运行的任务
在hdfs中查看执行结果
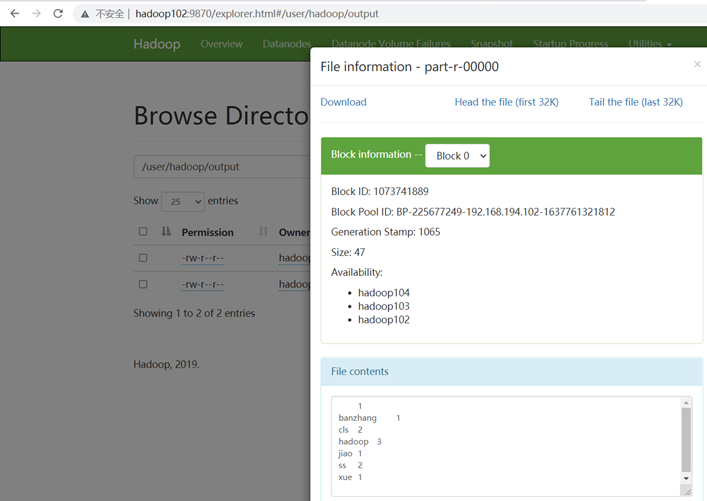
在Windows上向集群提交任务
复制WordcountDriver类到同一包下命名为WordcountDriverWin(也可直接在WordcountDriver类上修改)
- 添加必要配置信息,6、8、10、12行
- public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
- //1 获取配置信息和job对象
- Configuration configuration = new Configuration();
- //设置HDFS NameNode的地址
- configuration.set("fs.defaultFS", "hdfs://hadoop102:9820");
- // 指定MapReduce运行在Yarn上
- configuration.set("mapreduce.framework.name","yarn");
- // 指定mapreduce可以在远程集群运行
- configuration.set("mapreduce.app-submission.cross-platform","true");
- //指定Yarn resourcemanager的位置
- configuration.set("yarn.resourcemanager.hostname","hadoop102");
- Job job = Job.getInstance(configuration);
- //2 关联本Dirver程序的jar
- // job.setJarByClass(WordcountDriverWin.class);
- job.setJar("D:\\projects\\code02\\HdfsClientDemo\\target\\HdfsClientDemo-1.0-SNAPSHOT.jar");
- //3 关联Mapper和Reducer的jar
- job.setMapperClass(WordcountMapper.class);
- job.setReducerClass(WordcountReducer.class);
- //4 设置Mapper输出的kv类型
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- //5 设置最终输出的kv类型
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- //6 设置输入和输出路径
- FileInputFormat.setInputPaths(job, new Path(args[0]));
- FileOutputFormat.setOutputPath(job, new Path(args[1]));
- // //7 提交job
- boolean result = job.waitForCompletion(true);
- System.out.println(result);
- }
- 编辑任务配置
检查第一个参数Main class是不是要运行的类的全类名,如果不是要修改!
在VM options后面加上 :-DHADOOP_USER_NAME=hadoop
在Program arguments后面加上两个参数分别代表输入输出路径,两个参数之间用空格隔开。如:hdfs://hadoop102:9820/user/hadoop/hello.txt hdfs://hadoop102:9820/user/hadoop/output1
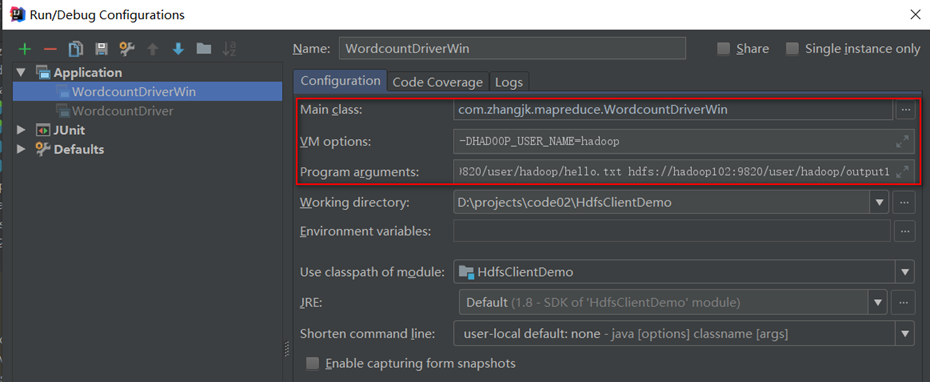
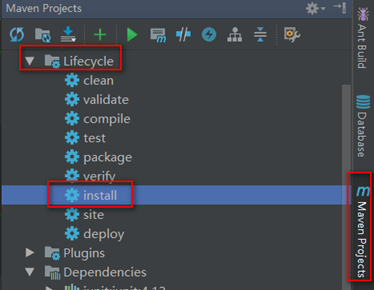
- 重新打包,并将Jar包设置到Driver中
Maven Projects --> Lifecyle --> install
- public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
- //1 获取配置信息和job对象
- Configuration configuration = new Configuration();
- //设置HDFS NameNode的地址
- configuration.set("fs.defaultFS", "hdfs://hadoop102:9820");
- // 指定MapReduce运行在Yarn上
- configuration.set("mapreduce.framework.name","yarn");
- // 指定mapreduce可以在远程集群运行
- configuration.set("mapreduce.app-submission.cross-platform","true");
- //指定Yarn resourcemanager的位置
- configuration.set("yarn.resourcemanager.hostname","hadoop102");
- Job job = Job.getInstance(configuration);
- //2 关联本Dirver程序的jar
- // job.setJarByClass(WordcountDriverWin.class);
- job.setJar("D:\\projects\\code02\\HdfsClientDemo\\target\\HdfsClientDemo-1.0-SNAPSHOT.jar");
- //3 关联Mapper和Reducer的jar
- job.setMapperClass(WordcountMapper.class);
- job.setReducerClass(WordcountReducer.class);
- //4 设置Mapper输出的kv类型
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- //5 设置最终输出的kv类型
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- //6 设置输入和输出路径
- FileInputFormat.setInputPaths(job, new Path(args[0]));
- FileOutputFormat.setOutputPath(job, new Path(args[1]));
- // //7 提交job
- boolean result = job.waitForCompletion(true);
- System.out.println(result);
- }
- 提交并查看结果
yarn平台上查看任务正在运行
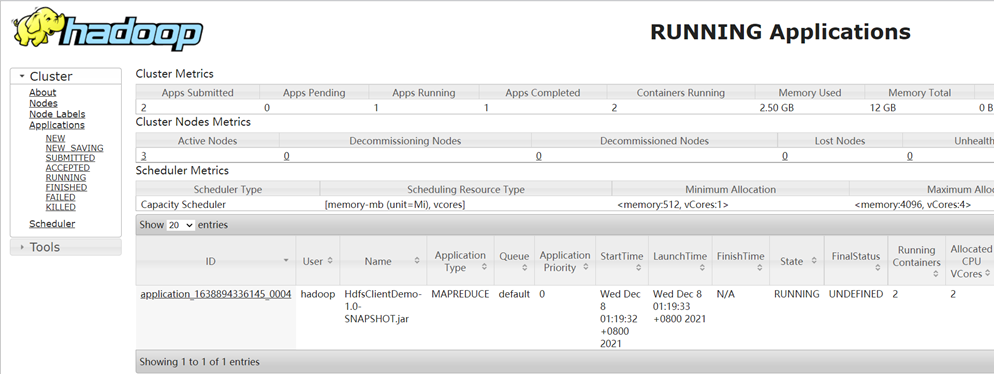
也可在hdfs中查看输出结果
Hadoop详解(04-1) - 基于hadoop3.1.3配置Windows10本地开发运行环境的更多相关文章
- Hadoop详解(04)-Hdfs
Hadoop详解(04)-Hdfs HDFS概述 HDFS产出背景及定义 背景:随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需 ...
- Hadoop详解(05) – MapReduce
Hadoop详解(05) – MapReduce MapReduce概述 定义 MapReduce是一个分布式运算程序的编程框架,是用户 "基于Hadoop的数据分析应用" 开发的 ...
- Hadoop详解(10) - Hadoop HA高可用
Hadoop详解(10) - Hadoop HA高可用 HA概述 HA(High Availablity),即高可用(7*24小时不中断服务). 实现高可用最关键的策略是消除单点故障.HA严格来说应该 ...
- Hadoop详解(06) - Yarn平台架构和资源调度器
Hadoop详解(06) - Yarn平台架构和资源调度器 Yarn平台架构 Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程 ...
- Spark详解(04) - Spark项目开发环境搭建
类别 [随笔分类]Spark Spark详解(04) - Spark项目开发环境搭建 Spark Shell仅在测试和验证程序时使用的较多,在生产环境中,通常会在IDEA中编制程序,然后打成Ja ...
- kafka详解(04) - kafka监控 可视化工具
kafka详解(04) - kafka监控 可视化工具 Kafka监控Eagle 1)修改kafka启动命令 修改kafka-server-start.sh命令中 if [ "x$KAFKA ...
- HBase详解(04) - HBase Java API使用
HBase详解(04) - HBase Java API使用 环境准备 新建Maven项目,在pom.xml中添加依赖 <dependency> <groupId>org.ap ...
- Hive详解(04) - hive函数的使用
Hive详解(04) - hive函数的使用 系统内置函数 查看系统自带的函数 hive> show functions; 显示自带的函数的用法 hive> desc function u ...
- Hadoop详解(09) - Hadoop新特性
Hadoop详解(09) - Hadoop新特性 Hadoop2.x新特性 远程主机之间的文件复制 scp实现两个远程主机之间的文件复制 推 push:scp -r hello.txt root@ha ...
随机推荐
- Java学习之路:快捷键
常用的快捷键 Ctrl+Shift:切换输入法 Ctrl+C:复制 Ctrl+V:粘贴 Ctrl+X:剪切 Ctrl+A:全选 Ctrl+Z:撤销 Ctrl+Y:返回撤销 Ctrl+S:保存 Shif ...
- 从源码分析 MGR 的流控机制
Group Replication 是一种 Shared-Nothing 的架构,每个节点都会保留一份数据. 虽然支持多点写入,但实际上系统的吞吐量是由处理能力最弱的那个节点决定的. 如果各个节点的处 ...
- getColumnName 和 getColumnLabel 的区别
select id as user from * getColumnName返回:"id" getColumnLabel 返回:"user"
- scrapy操作mysql/批量下载图片
1.操作mysql items.py meiju.py 3.piplines.py 4.settings.py -------------------------------------------- ...
- IDEA& Android Studio 配置
1.配置环境 首先要安装好JDK,但不需要单独下载SDK,只需在IDEA或AS的"设置->外观与行为->->系统设置->Android SDK"中下载相应版 ...
- SpringCloud微服务实战——搭建企业级开发框架(四十六):【移动开发】整合uni-app搭建移动端快速开发框架-环境搭建
近年来uni-app发展势头迅猛,只要会vue.js,就可以开发一套代码,发布移动应用到iOS.Android.Web(响应式).以及各种小程序(微信/支付宝/百度/头条/飞书/QQ/快手/钉钉/ ...
- 京东云开发者| Redis数据结构(二)-List、Hash、Set及Sorted Set的结构实现
1 引言 之前介绍了Redis的数据存储及String类型的实现,接下来再来看下List.Hash.Set及Sorted Set的数据结构的实现. 2 List List类型通常被用作异步消息队列.文 ...
- 微信小程序经纬度转化为具体位置(逆地址解析)
小程序wx.getLocation只能获取经纬度, 这时候想要具体地址就需要借助第三方sdk(逆地址解析) 我这边第三方以腾讯位置服务举例 一. 首先小程序需要申请wx.getLocation接口权限 ...
- 渗透技巧基于Swagger-UI的XSS
目录 免责声明: 漏洞简述: 漏洞实现 POC 漏洞利用 如何大规模找到 Swagger UI Google FOFA XRAY 修复 免责声明: 本文章仅供学习和研究使用,严禁使用该文章内容对互 ...
- .net随笔——Web开发config替换到正式config appSettings
前言(废话) 查了一些资料,总体来说呢,就是坑,而且顺带吐槽下百度,一个内容被copy那么多遍还排在最前面.同一个内容我点了那么多次,淦. 正题: 实现目的:开发的时候使用system.debug.c ...