数据挖掘算法——K-means算法
k-means中文称为K均值聚类算法,在1967年就被提出 所谓聚类就是将物理或者抽象对象的集合分组成为由类似的对象组成的多个簇的过程
聚类生成的组成为簇 簇内部任意两个对象之间具有较高的相似度,不同簇的两个对象之间具有较高的相异度
相异度和相似度可以根据描述的对象的属性值来计算 对象间的距离是最常采用的相异度度量指标
常用的距离方法有

k-means是基于划分的方法 就是通过迭代将数据对象划分为k个组每个组为一个簇
每个分组至少包含一个对象
每个对象属于且仅属于某个分组
输入:簇的数目K和包含n个对象的数据集D
输出:K个簇的集合
方法:
1.从D中任意选择K个对象作为初始簇的质心;
2.计算每个对象与各簇质心的距离,并且将对象划分到距离其更近的簇
3.更新每个新簇的质心
4.重复2.3步骤,直到簇中的对象不再变化
对K-means算法的几点说明
1.簇的质心就是簇中所有对象在每一维属性的举止组合成的虚拟点 并非实际存在的数据点
2.对噪声和离群(孤立)点数据是敏感,因为它们的存在会对均值的计算产生极大的影响
3.对象到质心的距离通常使用欧式距离来计算
4.要求用户实现给出生成的数目,要求K值已直
5.算法收敛的速度和结果容易受初始质心的影响
来个例子:
数据集:
n = 8, k = 2;取1和3为初始点
|
序号 |
属性1 |
属性2 |
|
1 |
1 |
1 |
|
2 |
2 |
1 |
|
3 |
1 |
2 |
|
4 |
2 |
2 |
|
5 |
4 |
3 |
|
6 |
5 |
3 |
|
7 |
4 |
4 |
|
8 |
5 |
4 |
#include<bits/stdc++.h>
using namespace std;
struct Node
{
int id;
double a, b;
}node[];
vector<int>beginn[],endd[];
int flag = ;
double distance(pair<double,double>a, Node b){
return (b.a - a.first) * (b.a - a.first) + (b.b - a.second) * (b.b - a.second);
}
bool check(int k )
{
if(flag == )
{
flag = ;
return false;
}
for(int i = ; i < k ; i ++)
{
if(beginn[i].size() != endd[i].size())
return false;
for(int j = ; j < endd[i].size(); j++)
{
if(endd[i][j] != beginn[i][j])
return false;
}
}
return true;
}
int main()
{
int n, k;
cin >> n >> k;
for(int i = ; i <= n; i ++)
cin >> node[i].id >> node[i].a >> node[i].b;
vector<double>vec[];
vector< pair<double, double> > gg;
for(int i = ; i <= k; i ++)
{
int x;
cin >> x;
gg.push_back(make_pair(node[x].a,node[x].b));
}//只要把这些点当作是初始点就可以 与其他的点无关即可
while(true)
{
for(int i = ; i < k; i++)
{
beginn[i].assign(endd[i].begin(), endd[i].end());
endd[i].clear();
}
for(int i = ; i < k; i ++) //表示有k个堆 计算每个堆里面的值
{
vec[i].clear();
for(int j = ; j <= n ; j ++)
vec[i].push_back(distance(gg[i] , node[j]));//计算的是每个点到初始点的距离
}
for(int i = ;i < n ; i ++)
{
double minn = 0x3f3f3f3f;
int u = -;
for(int j = ; j < k; j ++){
if(vec[j][i] < minn){
minn = vec[j][i];
u = j;//表示的是哪个簇的
}
}
endd[u].push_back(i + );
}
cout<<"新计算得到的"<<endl;
for(int i = ; i < k ; i ++)
{
for(int j = ; j < endd[i].size(); j ++)
printf("%d ",endd[i][j]);
printf("\n");
}
cout<<"原本的"<<endl;
for(int i = ; i < k ; i ++)
{
for(int j = ; j < beginn[i].size(); j ++)
printf("%d ",beginn[i][j]);
printf("\n");
}
gg.clear();
for(int i = ; i < k ; i ++)
{
double sum1 = , sum2 = ;
for(int j = ; j < endd[i].size(); j ++)
{
sum1 += node[endd[i][j]].a;
sum2 += node[endd[i][j]].b;
}
sum1 = sum1 / endd[i].size();
sum2 = sum2 / endd[i].size();
gg.push_back(make_pair(sum1,sum2)); //得到的新的值
}
cout<<"新的平均值:"<<endl;
for(int i = ; i < k ;i ++)
cout<<gg[i].first <<" " << gg[i].second<<endl;
cout<<endl;
if(check(k))
return ;
}
return ;
}
结果可得
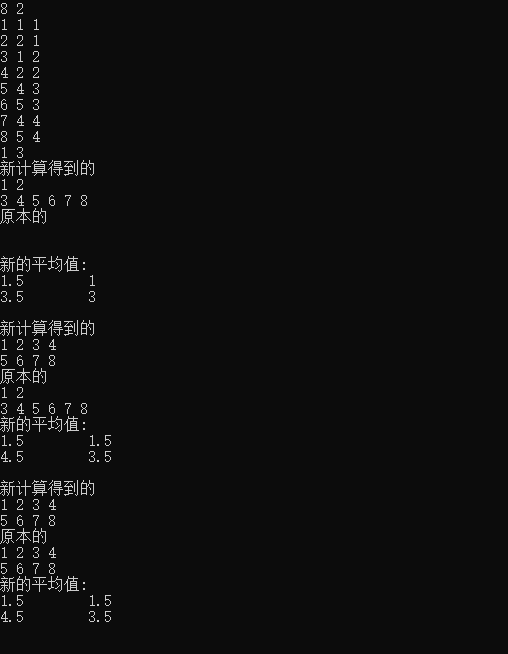
参考来自:
https://www.jianshu.com/p/4f032dccdcef
https://www.icourse163.org/course/CUG-1003556007?utm_campaign=share&utm_medium=androidShare&utm_source=
数据挖掘算法——K-means算法的更多相关文章
- 第4章 最基础的分类算法-k近邻算法
思想极度简单 应用数学知识少 效果好(缺点?) 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 distances = [] for x_train in X_train ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 分类算法----k近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 分类算法——k最近邻算法(Python实现)(文末附工程源代码)
kNN算法原理 k最近邻(k-Nearest Neighbor)算法是比较简单的机器学习算法.它采用测量不同特征值之间的距离方法进行分类,思想很简单:如果一个样本在特征空间中的k个最近邻(最相似)的样 ...
- 【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 用例子来理解k-近邻算法 电影可以按 ...
- 【机器学习】聚类算法——K均值算法(k-means)
一.聚类 1.基于划分的聚类:k-means.k-medoids(每个类别找一个样本来代表).Clarans 2.基于层次的聚类:(1)自底向上的凝聚方法,比如Agnes (2)自上而下的分裂方法,比 ...
随机推荐
- c/c++ main 函数命令行参数的使用
C程序最大的特点就是所有的程序都是用函数来装配的.main()称之为主函数,是所有程 序运行的入口.其余函数分为有参或无参两种,均由main()函数或其它一般函数调用,若调用的是有参函数,则参数在调用 ...
- python3之scrapy数据存储问题(MySQL)
这次我用的是python3.6,scrapy在python2.7,3.5的使用方法都不同所以要特别注意, 列如 在python3.5的开发环境下scrapy 的主爬虫文件可以使用 from urlli ...
- 测试误区《二》 python逻辑运算和关系运算优先级
关系运算 关系运算就是对2个对象进行比较,通过比较符判断进行比较,有6种方式. x > y 大于 x >= y 大于等于 x < y 小于 x <= y 小于等于 x = y ...
- TCP 的三次握手和四次挥手
参考资料: 1.TCP的三次握手与四次挥手理解及面试题: 2.Http协议三次握手和四次挥手: 3.TCP通信的三次握手和四次撒手的详细流程(顿悟) 前置: 序号(也称序列号) - Sequence ...
- navicat 导出查询结果
请依照下列步骤:(Windows 版本) 例子:导出查询结果到一个文本文件 在执行查询之后,保存查询及在工具栏点击导出向导/导出. 按照导出向导的步骤指导你完成 设置导出文件格式(步骤 1) 设置目标 ...
- 插入排序算法&算法分析
- RROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2
RROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2 ...
- process.env
官方: process.env属性返回一个包含用户环境信息的对象.
- 容易出错的JavaScript题目集锦
容易出错的JavaScript题目集锦 1.typeof(null) 会得到什么?object,在JavaScript中null被认为是一个对象. 2.下列代码将输出控制台的是什么?为什么? 1234 ...
- celery beat之pidfile already exists问题
背景 在进行celery定时任务测试时,发现到点任务并未执行,检查了log发现在启动celery beat的时候有这样一个报错,所以celery beat并未启动成功. 1234 (hzinfo) E ...