Transformer —— attention is all you need
https://www.cnblogs.com/rucwxb/p/10277217.html
Transformer —— attention is all you need
Transformer模型是2018年5月提出的,可以替代传统RNN和CNN的一种新的架构,用来实现机器翻译,论文名称是attention is all you need。无论是RNN还是CNN,在处理NLP任务时都有缺陷。CNN是其先天的卷积操作不很适合序列化的文本,RNN是其没有并行化,很容易超出内存限制(比如50tokens长度的句子就会占据很大的内存)。
下面左图是transformer模型一个结构,分成左边Nx框框的encoder和右边Nx框框的decoder,相较于RNN+attention常见的encoder-decoder之间的attention(上边的一个橙色框),还多出encoder和decoder内部的self-attention(下边的两个橙色框)。每个attention都有multi-head特征。最后,通过position encoding加入没考虑过的位置信息。 下面从multi-head attention,self-attention, position encoding几个角度介绍。
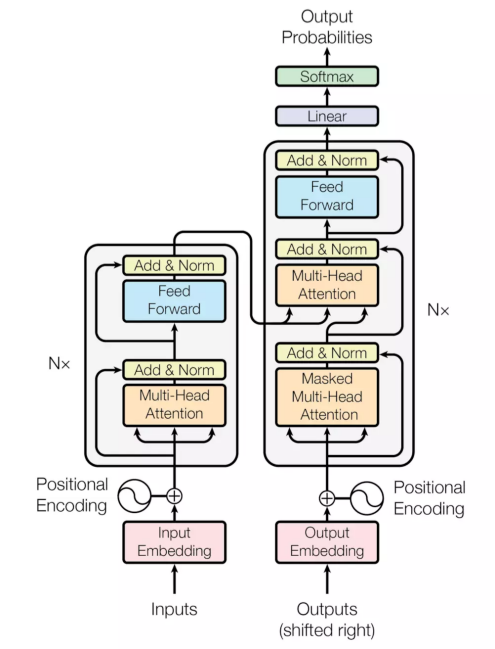
multi-head attention:
将一个词的vector切分成h个维度,求attention相似度时每个h维度计算。由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
self-attention:
每个词位的词都可以无视方向和距离,有机会直接和句子中的每个词encoding。比如上面右图这个句子,每个单词和同句其他单词之间都有一条边作为联系,边的颜色越深表明联系越强,而一般意义模糊的词语所连的边都比较深。比如:law,application,missing,opinion。。。
position encoding:
因为transformer既没有RNN的recurrence也没有CNN的convolution,但序列顺序信息很重要,比如你欠我100万明天要还和我欠你100万明天要还的含义截然不同。。。 transformer计算token的位置信息这里使用正弦波↓,类似模拟信号传播周期性变化。这样的循环函数可以一定程度上增加模型的泛化能力。
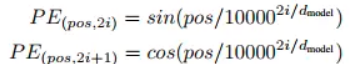
但BERT直接训练一个position embedding来保留位置信息,每个位置随机初始化一个向量,加入模型训练,最后就得到一个包含位置信息的embedding(简单粗暴。。),最后这个position embedding和word embedding的结合方式上,BERT选择直接拼接。
Transformer —— attention is all you need的更多相关文章
- Attention & Transformer
Attention & Transformer seq2seq; attention; self-attention; transformer; 1 注意力机制在NLP上的发展 Seq2Seq ...
- Paper Reading - Attention Is All You Need ( NIPS 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1706.03762 Motivation: The inherently sequential nature of ...
- [NLP] REFORMER: THE EFFICIENT TRANSFORMER
1.现状 (1) 模型层数加深 (2) 模型参数量变大 (3) 难以训练 (4) 难以fine-tune 2. 单层参数量和占用内存分析 层 参数设置 参数量与占用内存 1 layer 0.5Bill ...
- (转)How Transformers Work --- The Neural Network used by Open AI and DeepMind
How Transformers Work --- The Neural Network used by Open AI and DeepMind Original English Version l ...
- 文本建模、文本分类相关开源项目推荐(Pytorch实现)
Awesome-Repositories-for-Text-Modeling repo paper miracleyoo/DPCNN-TextCNN-Pytorch-Inception Deep Py ...
- 【NLP】彻底搞懂BERT
# 好久没更新博客了,有时候随手在本上写写,或者Evernote上记记,零零散散的笔记带来零零散散的记忆o(╥﹏╥)o..还是整理到博客上比较有整体性,也方便查阅~ 自google在2018年10月底 ...
- CVPR2020|3D-VID:基于LiDar Video信息的3D目标检测框架
作者:蒋天园 Date:2020-04-18 来源:3D-VID:基于LiDar Video信息的3D目标检测框架|CVPR2020 Brief paper地址:https://arxiv.org/p ...
- ACNet: 特别的想法,腾讯提出结合注意力卷积的二叉神经树进行细粒度分类 | CVPR 2020
论文提出了结合注意力卷积的二叉神经树进行弱监督的细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数来定义从根节点到叶子节点的计算路径,结合所有叶子节点的预测值进行最终的预测,论文的 ...
- Deformable 可变形的DETR
Deformable 可变形的DETR This repository is an official implementation of the paper Deformable DETR: Defo ...
随机推荐
- nginx的共享字典项api(操作方法)
nginx的共享内存,称为共享字典项,对于所有的worker进程都可见,是一种全局变量. 备注一下内容中的 [] 是 备注. 源码分析文档:https://www.codercto.com/a/948 ...
- 谈谈你对OOM的理解?
(1)整体架构 (1)ByteBuffer使用native方法,直接在堆外分配内存. 当堆外内存(也即本地物理内存)不够时,就会抛出这个异常 ----GC Direct buffer memo ...
- 攻防世界pwn-Mary_Morton
题目连接 https://adworld.xctf.org.cn/media/task/attachments/532c53dce1ce4f5d88461e4c2a336468 友情连接 https: ...
- [C3W2] Structuring Machine Learning Projects - ML Strategy 2
第二周:机器学习策略(2)(ML Strategy(2)) 误差分析(Carrying out error analysis) 你好,欢迎回来,如果你希望让学习算法能够胜任人类能做的任务,但你的学习算 ...
- hdu6494 dp
http://acm.hdu.edu.cn/showproblem.php?pid=6494 题意 一个长n字符串(n,1e4),'A'代表A得分,'B'代表B得分,'?'代表不确定,一局比赛先得11 ...
- P2按要求补全表达式
---恢复内容开始--- #include<stdio.h> int main () { int x; printf("输入一个整数"); scanf(" ...
- 使用VisualVM 进行性能分析及调优
概述 开发大型 Java 应用程序的过程中难免遇到内存泄露.性能瓶颈等问题,比如文件.网络.数据库的连接未释放,未优化的算法等.随着应用程序的持续运行,可能会造成整个系统运行效率下降,严重的则会造成系 ...
- LeetCode28——实现strStr()
6月中下旬辞职在家,7 月份无聊的度过了一个月.8 月份开始和朋友两个人写项目,一个后台和一个 APP ,APP 需要对接蓝牙打印机.APP 和蓝牙打印机都没有搞过,开始打算使用 MUI 开发 APP ...
- HTML+CSS基础 css的尺寸
css的尺寸 width 宽 height高 Line-light 行高 行高是由三部分构成,上间距.文本高度.下间距. 且上下间距相等.所以文字居中 行高.一旦设置行高了,元素内部必须 ...
- vue-cli安装以及创建一个简单的项目(一)(Node\npm\webpack简单使用)
1.关系介绍 1.简单的说 Node.js 就是运行在服务端的 JavaScript. 2.NPM是随同NodeJS一起安装的包管理工具(新版的nodejs已经集成了npm),能解决NodeJS代码部 ...