SparkMLlib回归算法之决策树
SparkMLlib回归算法之决策树
(一),决策树概念
1,决策树算法(ID3,C4.5 ,CART)之间的比较:
1,ID3算法在选择根节点和各内部节点中的分支属性时,采用信息增益作为评价标准。信息增益的缺点是倾向于选择取值较多的属性,在有些情况下这类属性可能不会提供太多有价值的信息。
2 ID3算法只能对描述属性为离散型属性的数据集构造决策树,其余两种算法对离散和连续都可以处理
2,C4.5算法实例介绍(参考网址:http://m.blog.csdn.net/article/details?id=44726921)
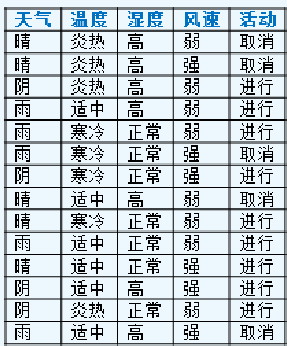

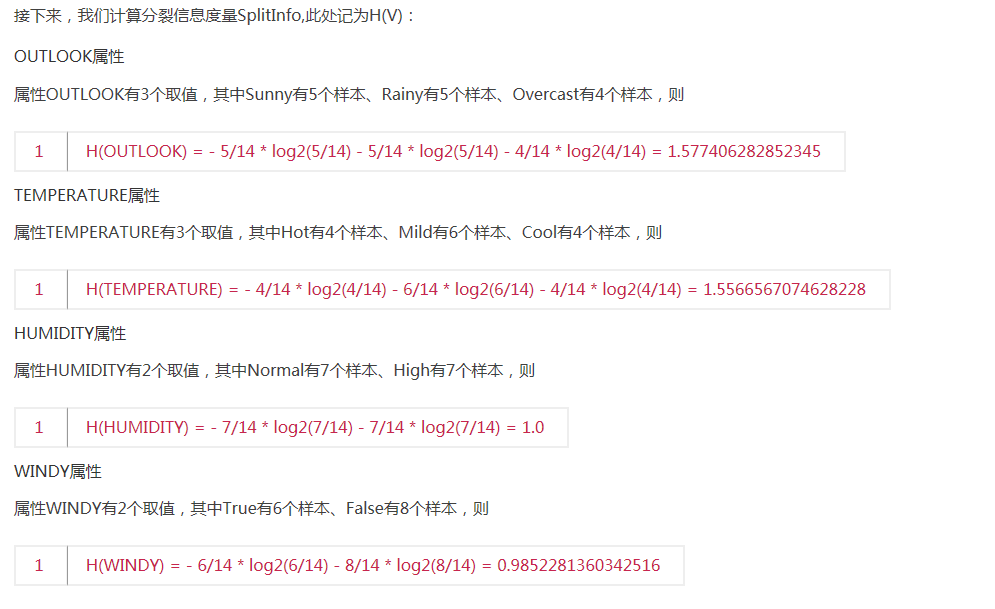
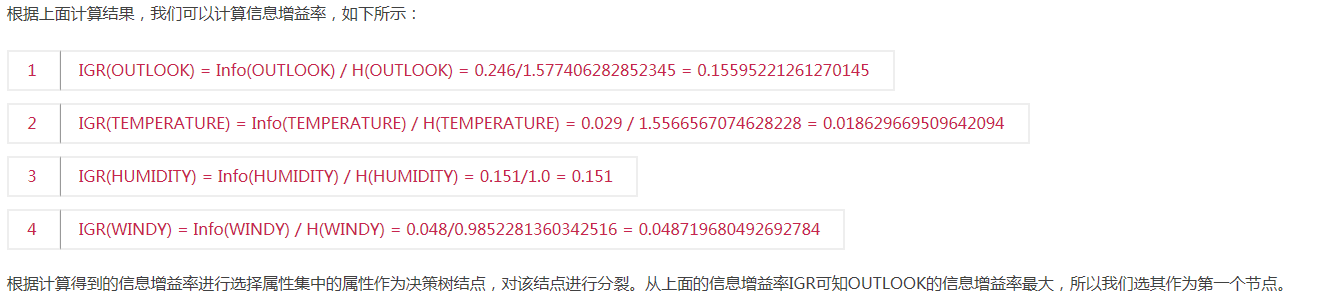
c4.5后剪枝策略:以悲观剪枝为主参考网址:http://www.cnblogs.com/zhangchaoyang/articles/2842490.html
(二) SparkMLlib决策树回归的应用
1,数据集来源及描述:参考http://www.cnblogs.com/ksWorld/p/6891664.html
2,代码实现:
2.1 构建输入数据格式:
val file_bike = "hour_nohead.csv"
val file_tree=sc.textFile(file_bike).map(_.split(",")).map{
x =>
val feature=x.slice(2,x.length-3).map(_.toDouble)
val label=x(x.length-1).toDouble
LabeledPoint(label,Vectors.dense(feature))
}
println(file_tree.first())
val categoricalFeaturesInfo = Map[Int,Int]()
val model_DT=DecisionTree.trainRegressor(file_tree,categoricalFeaturesInfo,"variance",5,32)
2.2 模型评判标准(mse,mae,rmsle)
val predict_vs_train = file_tree.map {
point => (model_DT.predict(point.features),point.label)
/* point => (math.exp(model_DT.predict(point.features)), math.exp(point.label))*/
}
predict_vs_train.take(5).foreach(println(_))
/*MSE是均方误差*/
val mse = predict_vs_train.map(x => math.pow(x._1 - x._2, 2)).mean()
/* 平均绝对误差(MAE)*/
val mae = predict_vs_train.map(x => math.abs(x._1 - x._2)).mean()
/*均方根对数误差(RMSLE)*/
val rmsle = math.sqrt(predict_vs_train.map(x => math.pow(math.log(x._1 + 1) - math.log(x._2 + 1), 2)).mean())
println(s"mse is $mse and mae is $mae and rmsle is $rmsle")
/*
mse is 11611.485999495755 and mae is 71.15018786490428 and rmsle is 0.6251152586960916
*/
(三) 改进模型性能和参数调优
1,改变目标量 (对目标值求根号),修改下面语句
LabeledPoint(math.log(label),Vectors.dense(feature))
和
val predict_vs_train = file_tree.map {
/*point => (model_DT.predict(point.features),point.label)*/
point => (math.exp(model_DT.predict(point.features)), math.exp(point.label))
}
/*结果
mse is 14781.575988339053 and mae is 76.41310991122032 and rmsle is 0.6405996100717035
*/
决策树在变换后的性能有所下降
2,模型参数调优
1,构建训练集和测试集
val file_tree=sc.textFile(file_bike).map(_.split(",")).map{
x =>
val feature=x.slice(2,x.length-3).map(_.toDouble)
val label=x(x.length-1).toDouble
LabeledPoint(label,Vectors.dense(feature))
/*LabeledPoint(math.log(label),Vectors.dense(feature))*/
}
val tree_orgin=file_tree.randomSplit(Array(0.8,0.2),11L)
val tree_train=tree_orgin(0)
val tree_test=tree_orgin(1)
2,调节树的深度参数
val categoricalFeaturesInfo = Map[Int,Int]()
val model_DT=DecisionTree.trainRegressor(file_tree,categoricalFeaturesInfo,"variance",5,32)
/*调节树深度次数*/
val Deep_Results = Seq(1, 2, 3, 4, 5, 10, 20).map { param =>
val model = DecisionTree.trainRegressor(tree_train, categoricalFeaturesInfo,"variance",param,32)
val scoreAndLabels = tree_test.map { point =>
(model.predict(point.features), point.label)
}
val rmsle = math.sqrt(scoreAndLabels.map(x => math.pow(math.log(x._1) - math.log(x._2), 2)).mean)
(s"$param lambda", rmsle)
}
/*深度的结果输出*/
Deep_Results.foreach { case (param, rmsl) => println(f"$param, rmsle = ${rmsl}")}
/*
1 lambda, rmsle = 1.0763369409492645
2 lambda, rmsle = 0.9735820606349874
3 lambda, rmsle = 0.8786984993014815
4 lambda, rmsle = 0.8052113493915528
5 lambda, rmsle = 0.7014036913077335
10 lambda, rmsle = 0.44747906135994925
20 lambda, rmsle = 0.4769214752638845
*/
深度较大的决策树出现过拟合,从结果来看这个数据集最优的树深度大概在10左右
3,调节划分数
/*调节划分数*/
val ClassNum_Results = Seq(2, 4, 8, 16, 32, 64, 100).map { param =>
val model = DecisionTree.trainRegressor(tree_train, categoricalFeaturesInfo,"variance",10,param)
val scoreAndLabels = tree_test.map { point =>
(model.predict(point.features), point.label)
}
val rmsle = math.sqrt(scoreAndLabels.map(x => math.pow(math.log(x._1) - math.log(x._2), 2)).mean)
(s"$param lambda", rmsle)
}
/*划分数的结果输出*/
ClassNum_Results.foreach { case (param, rmsl) => println(f"$param, rmsle = ${rmsl}")}
/*
2 lambda, rmsle = 1.2995002615220668
4 lambda, rmsle = 0.7682777577495858
8 lambda, rmsle = 0.6615110909041817
16 lambda, rmsle = 0.4981237727958235
32 lambda, rmsle = 0.44747906135994925
64 lambda, rmsle = 0.4487531073836407
100 lambda, rmsle = 0.4487531073836407
*/
更多的划分数会使模型变复杂,并且有助于提升特征维度较大的模型性能。划分数到一定程度之后,对性能的提升帮助不大。实际上,由于过拟合的原因会导致测试集的性能变差。可见分类数应在32左右。。
SparkMLlib回归算法之决策树的更多相关文章
- SparkMLlib分类算法之决策树学习
SparkMLlib分类算法之决策树学习 (一) 决策树的基本概念 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风 ...
- SparkMLlib学习分类算法之逻辑回归算法
SparkMLlib学习分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/51693 ...
- SparkMLlib分类算法之逻辑回归算法
SparkMLlib分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/5169383 ...
- SparkMLlib分类算法之支持向量机
SparkMLlib分类算法之支持向量机 (一),概念 支持向量机(support vector machine)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最 ...
- Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
Spark MLlib回归算法------线性回归.逻辑回归.SVM和ALS 1.线性回归: (1)模型的建立: 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多 ...
- Spark MLlib架构解析(含分类算法、回归算法、聚类算法和协同过滤)
Spark MLlib架构解析 MLlib的底层基础解析 MLlib的算法库分析 分类算法 回归算法 聚类算法 协同过滤 MLlib的实用程序分析 从架构图可以看出MLlib主要包含三个部分: 底层基 ...
- Lasso回归算法: 坐标轴下降法与最小角回归法小结
前面的文章对线性回归做了一个小结,文章在这: 线性回归原理小结.里面对线程回归的正则化也做了一个初步的介绍.提到了线程回归的L2正则化-Ridge回归,以及线程回归的L1正则化-Lasso回归.但是对 ...
- 基于Python的函数回归算法验证
看机器学习看到了回归函数,看了一半看不下去了,看到能用方差进行函数回归,又手痒痒了,自己推公式写代码验证: 常见的最小二乘法是一阶函数回归回归方法就是寻找方差的最小值y = kx + bxi, yiy ...
- 机器学习之Logistic 回归算法
1 Logistic 回归算法的原理 1.1 需要的数学基础 我在看机器学习实战时对其中的代码非常费解,说好的利用偏导数求最值怎么代码中没有体现啊,就一个简单的式子:θ= θ - α Σ [( hθ( ...
随机推荐
- js计算器
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- 细说OC中的load和initialize方法
OC中有两个特殊的类方法,分别是load和initialize.本文总结一下这两个方法的区别于联系.使用场景和注意事项.Demo可以在我的Github上找到--load和initialize,如果觉得 ...
- Python爬虫 Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- C字符串处理函数
部分参考百科. C常用字符串函数:字符串输入函数,字符串输出函数,字符串处理函数,标准输入输出流 字符串处理函数: 1.字符串长度:strlen(str),返回字符串实际长度,不包括'\0',返回值类 ...
- phpcms 制作简单企业站的常用标签
标题 title 关键字 keywords 描述 description 来源 copyfrom 允许访问 allow_visitor==1 thumb 缩略图 {template "con ...
- centos7安装redis3.0和phpredis扩展详细教程(图文)
整理一下centos7安装redis3.0和phpredis扩展的过程,有需要的朋友可以拿去使用. 一.安装redis3.0 1.安装必要的包 yum install gcc 2.centos7安装r ...
- 简谈-Python的输入、输出、运算符、数据类型转换
输出: 格式化输出: 看到了 % 这样的操作符,这就是Python中格式化输出. 换行输出: 在输出的时候,如果有 \n 那么,此时 \n 后的内容会在另外一行显示 输入: 在python2.7当中, ...
- [进程管理]Linux进程状态解析之T、Z、X
Linux进程状态:T (TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态. 向进程发送一个SIGSTOP信号,它就会因响应该信号而进入 ...
- Supervisor: A Process Control System
Supervisor: 进程控制系统 概述:Supervisor是一个 Client/Server模式的系统,允许用户在类unix操作系统上监视和控制多个进程,或者可以说是多个程序. 它与launch ...
- 蓝桥杯-土地测量-java
/* (程序头部注释开始) * 程序的版权和版本声明部分 * Copyright (c) 2016, 广州科技贸易职业学院信息工程系学生 * All rights reserved. * 文件名称: ...