大数据处理框架之Strom:Storm集群环境搭建
搭建环境
Red Hat Enterprise Linux Server release 7.3 (Maipo)
zookeeper-3.4.11
jdk1.7.0_80
Python 2.7.5 (https://www.cnblogs.com/kimyeee/p/7250560.html)
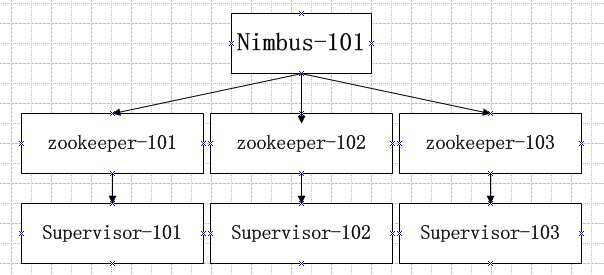
集群方案
机器:101 102 103
安装步骤
安装依赖jdk和python
[cluster@PCS101 ~]$ java -version
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) -Bit Server VM (build 24.80-b11, mixed mode)
[cluster@PCS101 ~]$ python -V
Python 2.7.
1.解压storm
[cluster@PCS101 tars]$ tar -zxvf apache-storm-0.9.-incubating.tar.gz -C /home/cluster
#改名
[cluster@PCS101 ~]$ mv /home/cluster/apache-storm-0.9.-incubating apache-storm-0.9.
#创建任务目录
[cluster@PCS101 ~]$ mkdir /home/cluster/apache-storm-0.9./task
2.修改配置
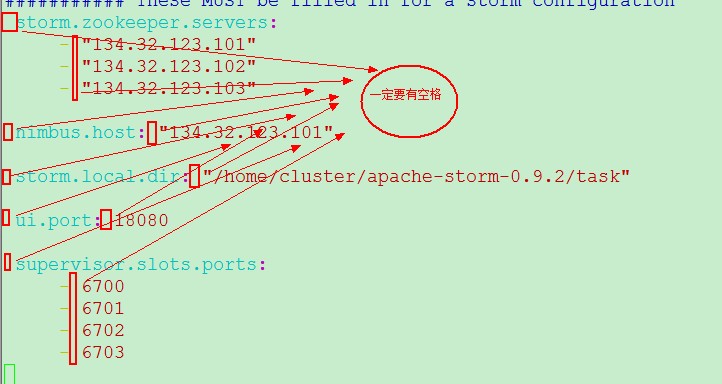
[cluster@PCS101 conf]$ vim /home/cluster/apache-storm-0.9./conf/storm.yaml
()zookeeper集群地址
storm.zookeeper.servers:
- "134.32.123.101"
- "134.32.123.102"
- "134.32.123.103" ()主节点Nimbus配置
nimbus.host: "134.32.123.101" ()设置storm运行任务执行的jar存放的目录
storm.local.dir: "/home/cluster/apache-storm-0.9.2/task" ()配置UI端口:ui.port
ui.port: ()配置worker而进程默认端口号,如果worker进程超过设置数量,则多出来的worker会随机分配端口
supervisor.slots.ports:
-
-
-
-
配置注意留有空格:
3.将101上的storm拷贝到102、103上
[cluster@PCS101 ~]$ scp -r /home/cluster/apache-storm-0.9./ cluster@134.32.123.102:/home/cluster/
[cluster@PCS101 ~]$ scp -r /home/cluster/apache-storm-0.9./ cluster@134.32.123.103:/home/cluster/
4.root用户修改系统环境变量
[root@PCS101 ~]# vim /etc/profile
export STORM_HOME=/home/cluster/apache-storm-0.9.
export PATH=$JAVA_HOME/bin:$MYSQL_BIN:$STORM_HOME/bin:$PATH
[root@PCS101 ~]# source /etc/profile
5.启动(保证zookeeper集群已启动)
按顺序启动:
启动Nimbus
134.32.123.101: 主机器(nimbus运行) : nohup storm nimbus > /dev/null >& &
[cluster@PCS101 ~]$ jps
QuorumPeerMain
Jps
nimbus
启动supervisor
134.32.123.101: 从机器(supervisor运行): nohup storm supervisor > /dev/null >& &
134.32.123.102: 从机器(supervisor运行): nohup storm supervisor > /dev/null >& &
134.32.123.103: 从机器(supervisor运行): nohup storm supervisor > /dev/null >& &
[cluster@PCS102 conf]$ jps
supervisor
Jps
QuorumPeerMain
启动UI (默认jetty做容器)
134.32.123.101: 主机器(ui运行) : nohup storm ui > /dev/null >& & (查看ui)
[cluster@PCS101 conf]$ jps
supervisor
QuorumPeerMain
nimbus
Jps
core
启动logviewer
134.32.123.101: 主机器(logviewer运行) : nohup storm logviewer > /dev/null >& &(查看工作日志)
[cluster@PCS101 conf]$ jps
supervisor
QuorumPeerMain
Jps
nimbus
logviewer
core
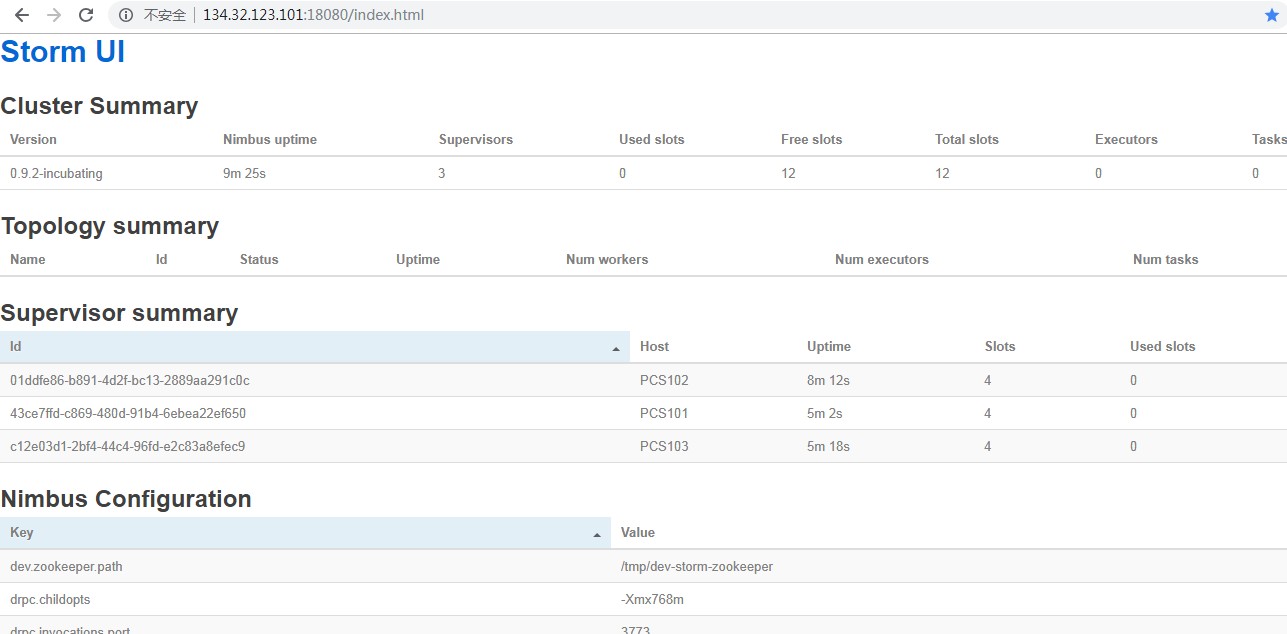
访问 StormUI
http://134.32.123.101:18080/
附一:伪分布式搭建
#storm帮助命令
[cluster@PCS101 ~]$ ./bin/storm --help #下面分别按照顺序启动ZooKeeper、Nimbus、UI、supervisor、logviewer
[cluster@PCS101 ~]$ ./bin/storm dev-zookeeper >> ./logs/zk.out 2>&1 &
[cluster@PCS101 ~]$ ./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
[cluster@PCS101 ~]$ ./bin/storm ui >> ./logs/ui.out 2>&1 &
[cluster@PCS101 ~]$ ./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
[cluster@PCS101 ~]$ ./bin/storm logviewer >> ./logs/logviewer.out 2>&1 &
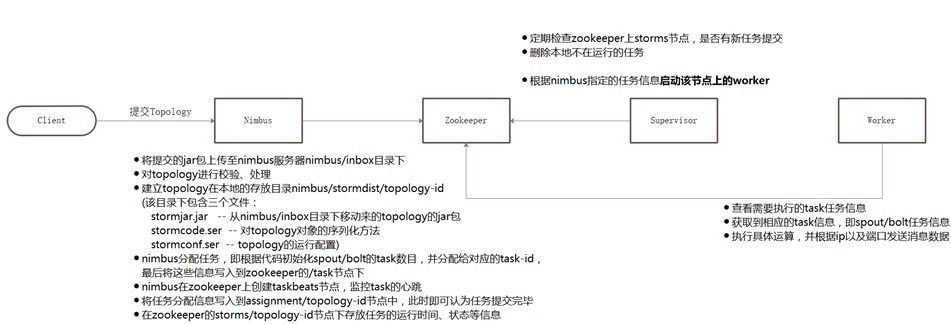
附二:storm提交任务流程
附三:storm本地目录树

附四:ZK目录树

参考:
大数据处理框架之Strom:Storm集群环境搭建的更多相关文章
- 一:Storm集群环境搭建
第一:storm集群环境准备及部署[1]硬件环境准备--->机器数量>=3--->网卡>=1--->内存:尽可能大--->硬盘:无额外需求[2]软件环境准备---& ...
- Storm —— 集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 系列(四)—— Storm 集群环境搭建
一.集群规划 这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus ...
- storm集群环境搭建
1.环境 Java环境 卸载虚机环境中自带的openJdk,安装sun的jdk,配置环境变量 2.安装storm 下载storm安装包 解压到安装目录,配置环境变量 vi /etc/profile # ...
- 大数据处理框架之Strom: Storm拓扑的并行机制和通信机制
一.并行机制 Storm的并行度 ,通过提高并行度可以提高storm程序的计算能力. 1.组件关系:Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor. ...
- centos7:storm集群环境搭建
1.安装storm 下载storm安装包 在线下载 wget http://apache.fayea.com/storm/apache-storm-1.1.1/apache-storm-1.1.1.t ...
- 大数据hadoop入门学习之集群环境搭建集合
目录: 1.基本工作准备 1.虚拟机准备 2.java 虚拟机-jdk环境配置 3.ssh无密码登录 2.hadoop的安装与配置 3.hbase安装与配置(集成安装zookeeper) 4.zook ...
- 大数据处理框架之Strom: Storm----helloword
大数据处理框架之Strom: Storm----helloword Storm按照设计好的拓扑流程运转,所以写代码之前要先设计好拓扑图.这里写一个简单的拓扑: 第一步:创建一个拓扑类含有main方法的 ...
随机推荐
- linux内存不足,swap交换分区创建
为什么需要swap 根 据Redhat公司的建议,Linux系统swap分区最适合的大小是物理内存的1-2倍.不过Linux上有些软件对swap分区得需求较大,例如要顺 利执行Oracle数据库软件, ...
- icon工具类
using System; using System.Drawing; using System.Collections; using System.ComponentModel; using Sys ...
- 编写第一个H5页面
<!DOCTYPE html><html ><head> <meta charset="UTF-8"> <title>第 ...
- Linux下Zookeeper的安装
Linux下Zookeeper的安装 安装环境: Linux:centos6.4 Jdk:1.7以上版本 Zookeeper是java开发的可以运行在windows.linux环境.需要先安装jdk. ...
- 【WebDriver】WebDriver 常用操作
WebDriver 常用操作 1 浏览器操作 2 窗口和弹框操作 3 cookies 操作 4 简单对象的定位 5 页面元素操作 6 鼠标事件 7 键盘事件 1 浏览器操作 #属性: driver.c ...
- 代码控如何实现配置fiddler
很多小哥哥总觉得测试点点点很low,总想码代码.那么fiddler除了一些手动设置外,还可以进行丰富的代码编写,用以完成任务. 打开fiddler,工具栏选择Rules->Customize R ...
- 剑指offer-合并两个排列的链接
题目描述 输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则. public ListNode Merge(ListNode list1,ListNode ...
- 【UNIX网络编程(三)】TCP客户/server程序演示样例
上一节给出了TCP网络编程的函数.这一节使用那些基本函数编写一个完毕的TCP客户/server程序演示样例. 该样例运行的过程例如以下: 1.客户从标准输入读入一行文本,并写给server. 2.se ...
- mysql之event
mysql之event http://blog.csdn.net/lxgwm2008/article/details/9088521 Mysql事件调度器(Event Scheduler)类似于定时器 ...
- 006-优化web请求二-应用缓存、异步调用【Future、ListenableFuture、CompletableFuture】、ETag、WebSocket【SockJS、Stomp】
四.应用缓存 使用spring应用缓存.使用方式:使用@EnableCache注解激活Spring的缓存功能,需要创建一个CacheManager来处理缓存.如使用一个内存缓存示例 package c ...