Python爬虫教程-03-使用 chardet 检测编码
Spider-03-使用chardet
继续学习python爬虫,我们经常出现解码问题,因为所有的页面编码都不统一,我们使用chardet检测页面的编码,尽可能的减少编码问题的出现
网页编码问题解决
- 使用chardet 可以自动检测页面文件的编码格式,但是也有可能出错
- 需要安装chardet,
- 如果使用Anaconda环境,使用下面命令:
conda install chardet
- 如果不是,就自己手动在【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】>【chardet】>【install】
具体操作截图:
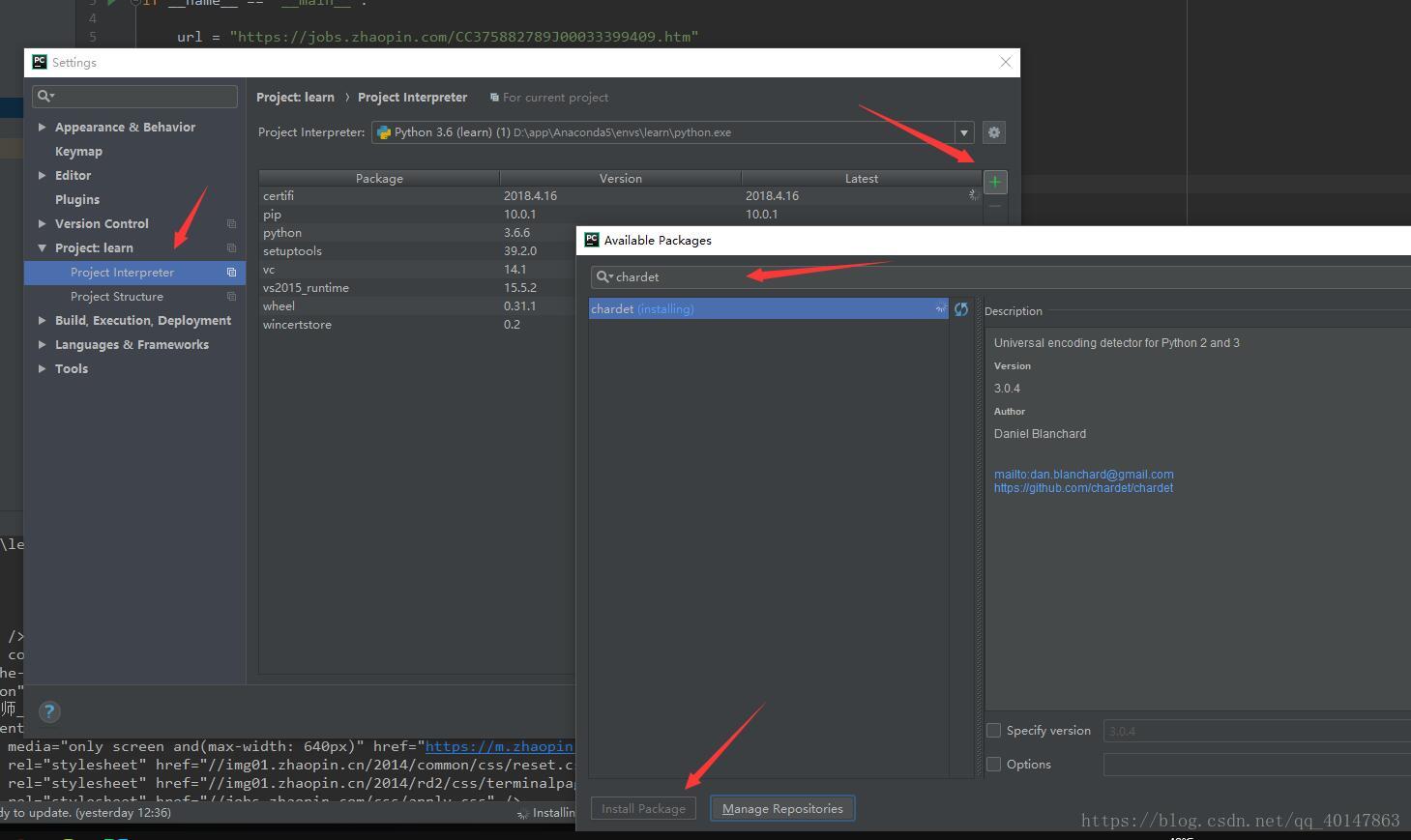
案例v2
- py03chardet.py文件:https://xpwi.github.io/py/py爬虫/py03chardet.py
# py03chardet.py
# 使用request下载页面,并自动检测页面编码
from urllib import request
import chardet
if __name__ == '__main__':
url = 'https://jobs.zhaopin.com/CC375882789J00033399409.htm'
rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法
html = rsp.read()
cs = chardet.detect(html)
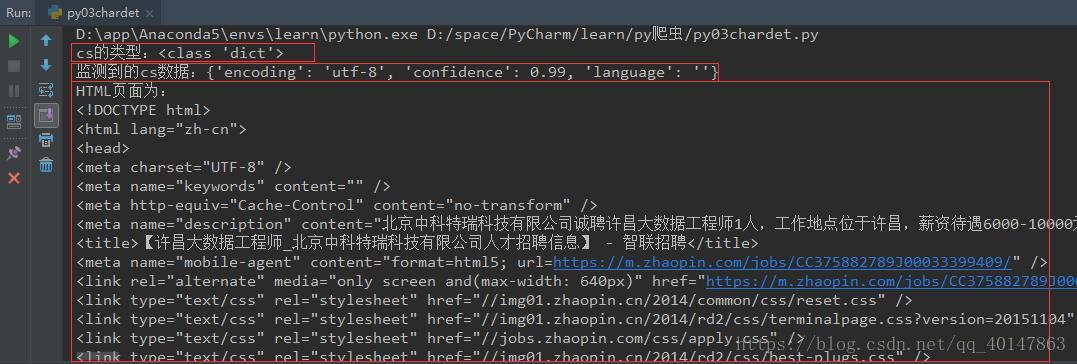
print("cs的类型:{0}".format(type(cs)))
print("监测到的cs数据:{0}".format(cs))
html = html.decode(cs.get("encoding", "utf-8"))
# 意思是监测到就使用监测到的,监测不到就使用utf-8
print("HTML页面为:\n%s" % html)
右键运行,截图如下
编码检测就介绍完了,最要的功能是检测页面的编码,尽可能的减少编码问题的出现
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-03-使用 chardet 检测编码的更多相关文章
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
- Python爬虫教程-07-post介绍(百度翻译)(上)
Python爬虫教程-07-post介绍(百度翻译)(上) 访问网络两种方法 get: 利用参数给服务器传递信息 参数为dict,使用parse编码 post :(今天给大家介绍的post) 一般向服 ...
- Python爬虫教程-28-Selenium 操纵 Chrome
我觉得本篇是很有意思的,闲着没事来看看! Python爬虫教程-28-Selenium 操纵 Chrome PhantomJS 幽灵浏览器,无界面浏览器,不渲染页面.Selenium + Phanto ...
- Python爬虫教程-23-数据提取-BeautifulSoup4(一)
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据,查看文档 https://www.crummy.com/software/BeautifulSoup/bs4/doc. ...
- Python爬虫教程-19-数据提取-正则表达式(re)
本篇主页内容:match的基本使用,search的基本使用,findall,finditer的基本使用,匹配中文,贪婪与非贪婪模式 Python爬虫教程-19-数据提取-正则表达式(re) 正则表达式 ...
随机推荐
- 透析ARP原理
对于ARP协议, 我本来是不了解的,只是解决了两个ARP相关的P2的Bug后,也就懂了.本文将从原理的角度对ARP做一个透析. 1. 什么是ARP? ARP(Address Resolution Pr ...
- session_start()导致history.go(-1)返回时无法保存表单数据的解决方法
问题背景: 在填写完表单提交时,由于某个表单项可能填写的不合法,导致提交失败,返回表单页面.但返回后所有的表单都被清空了,重新填写比较麻烦,度娘解释说,是由于每个页面都调用了session_start ...
- linux下统计文本行数的各种方法(一)
文件test1.txt有17行 方法一: awk '{print NR}' test1.txt | tail -n1
- 分布式版本控制系统Git——使用GitStack+TortoiseGit 图形界面搭建Git环境(服务器端及客户端)(转)
近期想改公司内部的源码管控从TFS为git,发现yubinfeng大侠有关git的超详细大作,现将其转载并记录下,以防忘记,其原博客中有更加详细的git及.net开发相关内容.原文地址:http:// ...
- JS+Zero Clipboard swf复制到剪贴板 兼容浏览器(bind事件绑定函数)
转自http://www.ipmtea.net/css_ie_firefox/201107/07_499.html 1.ZeroClipboard其实是国外的一个js类库,源码结构如: var Zer ...
- EntityFrameworkCode 操作MySql 相关问题
近段时间,由于工作原因,使用到了EntityFrameworkCore 操作MySql数据库,使用中遇到一些问题,特此记录 系统环境 Win10 1805,VS 2017,Framework:Asp. ...
- vue做的简单购物车
<code><!DOCTYPE html><html><head lang="en"> <meta charset=" ...
- 通过Visual Studio 的“代码度量值”来改进代码质量
1 软件度量值指标 1.1 可维护性指数 表示源代码的可维护性,数值越高可维护性越好.该值介于0到100之间.绿色评级在20到100之间,表明该代码具有高度的可维护性:黄色评级在10到19之间,表示该 ...
- synchronized同步锁
在多线程的情况下,由于同一进程的多个线程共享同一片存储空间,在带来方便的同时,也带来了访问冲突这个严重的问题.Java语言提供了专门机制以解决这种冲突,有效避免了同一个数据对象被多个线程同时访问.由于 ...
- <深入理解JavaScript>学习笔记(3)_全面解析Module模式
简介 Module模式是JavaScript编程中一个非常通用的模式,一般情况下,大家都知道基本用法,本文尝试着给大家更多该模式的高级使用方式. 首先我们来看看Module模式的基本特征: 模块化,可 ...