Python爬虫教程-03-使用 chardet 检测编码
Spider-03-使用chardet
继续学习python爬虫,我们经常出现解码问题,因为所有的页面编码都不统一,我们使用chardet检测页面的编码,尽可能的减少编码问题的出现
网页编码问题解决
- 使用chardet 可以自动检测页面文件的编码格式,但是也有可能出错
- 需要安装chardet,
- 如果使用Anaconda环境,使用下面命令:
conda install chardet
- 如果不是,就自己手动在【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】>【chardet】>【install】
具体操作截图:
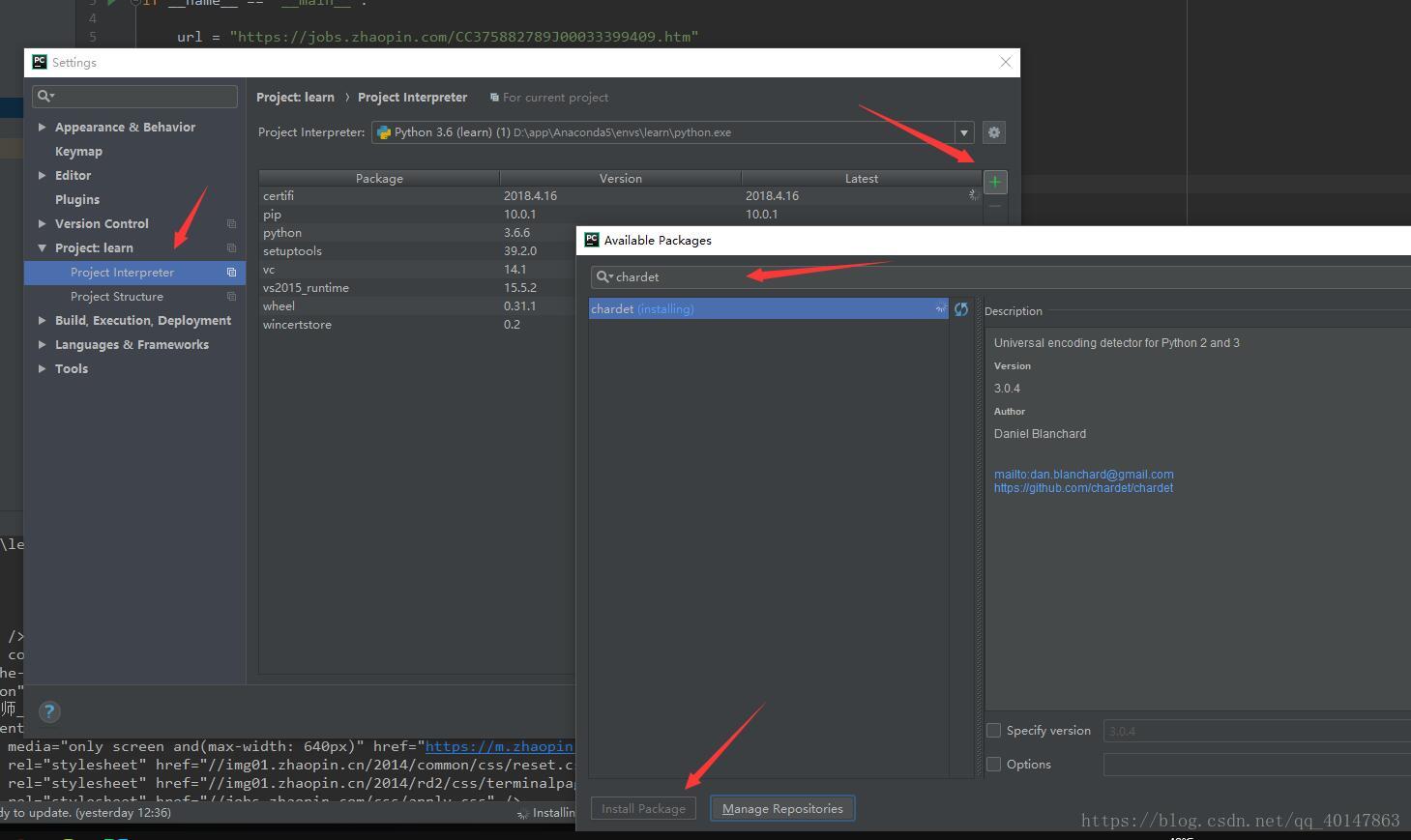
案例v2
- py03chardet.py文件:https://xpwi.github.io/py/py爬虫/py03chardet.py
# py03chardet.py
# 使用request下载页面,并自动检测页面编码
from urllib import request
import chardet
if __name__ == '__main__':
url = 'https://jobs.zhaopin.com/CC375882789J00033399409.htm'
rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法
html = rsp.read()
cs = chardet.detect(html)
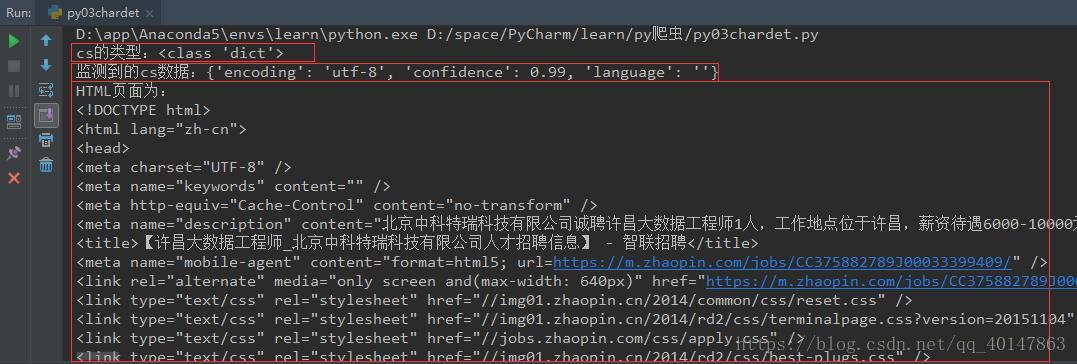
print("cs的类型:{0}".format(type(cs)))
print("监测到的cs数据:{0}".format(cs))
html = html.decode(cs.get("encoding", "utf-8"))
# 意思是监测到就使用监测到的,监测不到就使用utf-8
print("HTML页面为:\n%s" % html)
右键运行,截图如下
编码检测就介绍完了,最要的功能是检测页面的编码,尽可能的减少编码问题的出现
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-03-使用 chardet 检测编码的更多相关文章
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
- Python爬虫教程-07-post介绍(百度翻译)(上)
Python爬虫教程-07-post介绍(百度翻译)(上) 访问网络两种方法 get: 利用参数给服务器传递信息 参数为dict,使用parse编码 post :(今天给大家介绍的post) 一般向服 ...
- Python爬虫教程-28-Selenium 操纵 Chrome
我觉得本篇是很有意思的,闲着没事来看看! Python爬虫教程-28-Selenium 操纵 Chrome PhantomJS 幽灵浏览器,无界面浏览器,不渲染页面.Selenium + Phanto ...
- Python爬虫教程-23-数据提取-BeautifulSoup4(一)
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据,查看文档 https://www.crummy.com/software/BeautifulSoup/bs4/doc. ...
- Python爬虫教程-19-数据提取-正则表达式(re)
本篇主页内容:match的基本使用,search的基本使用,findall,finditer的基本使用,匹配中文,贪婪与非贪婪模式 Python爬虫教程-19-数据提取-正则表达式(re) 正则表达式 ...
随机推荐
- [BZOJ5248][2018九省联考]一双木棋
题目描述 https://www.lydsy.com/JudgeOnline/problem.php?id=5248 Solution 我们首先考虑放棋子的操作 发现它一定放棋子的部分是一个联通块 ...
- Great Expectations
Dear friend, This game is created based on Dicken's Great Expectations. To colorful the contents, I ...
- mono for android 第三课--页面布局(转)
对于C#程序员来说布局不是什么难事,可是对于我这个新手在mono for android 中布局还是有点小纠结的,不会没关系.慢慢学习.好吧我们开始简单的布局.在之前我们拖拽的控件都是自动的去布局,也 ...
- DIV盒子介绍
1.盒子模型=网页布局的基石,由四部分组成: 边框(border).外边距(margin).内边距(padding).盒子中的内容(content) 2.设置顺序是顺时针:上.右.下.左. 三个值(上 ...
- Windows里下载并安装phpstudy(图文详解)
不多说,直接上干货! 帮助站长快速搭建网站服务器平台! phpstudy软件简介 此是基于phpStudy 2016.01.01. 该程序包集成最新的Apache+Nginx+LightTPD+PHP ...
- 执行Hive时出现org.apache.hadoop.util.RunJar.main(RunJar.java:136) Caused by: java.lang.NumberFormatException: For input string: "1s"错误的解决办法(图文详解)
不多说,直接上干货 问题详情 [kfk@bigdata-pro01 apache-hive--bin]$ bin/hive Logging initialized -bin/conf/hive-log ...
- [中英对照]User-Space Device Drivers in Linux: A First Look | 初识Linux用户态设备驱动程序
如对Linux用户态驱动程序开发有兴趣,请阅读本文,否则请飘过. User-Space Device Drivers in Linux: A First Look | 初识Linux用户态设备驱动程序 ...
- 实例说明optimize table在优化mysql时很重要
今天在看CU的时候,发现有人问有关optimize来表优化的问题,当年因为这个问题,困扰我很长一段时间,今天有空我把这个问题,用实际数据来展示出来,让大家可以亲眼来看看,optimize table的 ...
- JavaScript自动化构建工具grunt、gulp、webpack介绍
前端开发自动化工作流工具,JavaScript自动化构建工具grunt.gulp.webpack介绍 前端自动化,这样的一个名词听起来非常的有吸引力,向往力.当今时代,前端工程师需要维护的代码变得及为 ...
- SimpleCalendar日历插件改版
先附上一张货真价实的效果图: 以上部分代码,为了适应我司项目的需求,原来插件源码大改(因为项目中下拉框用了select2,所以原来插件的下拉框就有问题了,在加上原来插件本身就有点问题,特别是农历 .节 ...