hive拉链表以及退链例子笔记
拉链表设计:
在企业中,由于有些流水表每日有几千万条记录,数据仓库保存5年数据的话很容易不堪重负,因此可以使用拉链表的算法来节省存储空间。
例子:
-- 用户信息表; 采集当日全量数据存储到 (当日) 表中
CREATE TABLE dwd.user_info(
id string,
name string,
sex string,
biz_date string -- 业务日期
) -- 用户信息整合表
CREATE TABLE dws.user_merge_info(
id string,
name string,
sex string,
start_date string,
end_date string
) -- 测试插入用户信息
INSERT INTO dwd.user_info
SELECT
'','YaoMing','boy',''
UNION ALL
SELECT
'','YaoLinlin','girl',''
UNION ALL
SELECT
'','CaiLili','girl',''
UNION ALL
SELECT
'','ZhangSan','girl',''
UNION ALL
SELECT
'','LiSi','girl','' -- 查看数据
SELECT * FROM dwd.user_info
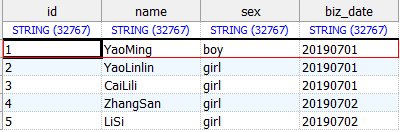
-- 初始化用户信息整合表
INSERT overwrite TABLE dws.user_merge_info
SELECT
id,
name,
sex,
'' AS start_date,
'' AS end_date
FROM (
SELECT
id,
name,
sex,
row_number() over(PARTITION BY id ORDER BY biz_date) AS row_num -- 初始化时候根据主键id分组,取最新修改的数据
FROM dwd.user_info
) t
WHERE t.row_num = 1 -- 查看数据
SELECT * FROM dws.user_merge_info

-- 现在biz_date='20190702'这天,新跑了一条全新数据id=6,以及修改了一条id=2的数据
INSERT INTO dwd.user_info
SELECT
'','WangWu','boy',''
UNION ALL
SELECT
'','YaoLinlin','boy','' -- 查看数据
SELECT * FROM dwd.user_info ORDER BY id,biz_date

-- 新增修改以及完全新增
INSERT overwrite TABLE tmp.user_merge_info_new
-- 修改的数据
SELECT
b.id,
b.name,
b.sex,
'' AS start_date, -- ${bizdate} 业务日期
'' AS end_date -- 99991231代表有效数据
FROM dws.user_merge_info a,
dwd.user_info b
WHERE a.id = b.id
AND a.end_date = ''
AND b.biz_date = '' -- ${bizdate}只取当天数据
AND (
a.name!= b.name
OR a.sex != b.sex
) UNION ALL
-- 全新的数据
SELECT
b.id,
b.name,
b.sex,
''AS start_date,
''AS end_date
FROM dws.user_merge_info a
RIGHT JOIN dwd.user_info b
ON a.id = b.id
WHERE b.biz_date=''
AND a.id IS NULL;

-- 闭链
INSERT overwrite TABLE tmp.user_merge_info_upt
SELECT
a.id,
a.name,
a.sex,
a.start_date,
'' -- 闭链,${biz_date}业务时间
FROM dws.user_merge_info a
LEFT JOIN dwd.user_info b
ON a.id=b.id
WHERE a.end_date=''
AND b.biz_date=''
AND (
a.name != b.name
OR a.sex != b.sex
)

-- 历史数据
INSERT overwrite TABLE tmp.user_merge_info_new
SELECT
a.id,
a.name,
a.sex,
a.start_date,
a.end_date
FROM dws.user_merge_info a,
tmp.user_merge_info_upt b
WHERE a.id != b.id;

-- 整合数据
INSERT OVERWRITE TABLE dws.user_merge_info
SELECT
id,
name,
sex,
start_date,
end_date
FROM tmp.user_merge_info_new
UNION ALL
SELECT
id,
name,
sex,
start_date,
end_date
FROM tmp.user_merge_info_upt
UNION ALL
SELECT
id,
name,
sex,
start_date,
end_date
FROM tmp.user_merge_info_his -- 查看下数据
SELECT * FROM dws.user_merge_info ORDER BY id,start_date
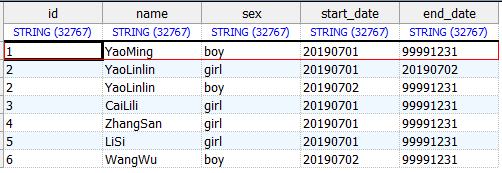
以上拉链表就实现好了
以下是退链操作模板
#!/bin/bash # 使用说明提示
if [ $# -ne 1 ]; then
echo "Usage : `basename $0` biz_date"
exit 1
fi #业务时间
biz_date=$1 # 判断是数据整合还是回退拉链表
isGoBack=`execHQL "select count(1) from dws.user_merge_info where (end_date>='$biz_date' or start_date>='$biz_date') and biz_date<>'';"` if [ $isGoBack -ne 0 ];then
# 回退模式
Log "\n## 【user_merge_info表回退】 执行开始 ##"
execHQL "
INSERT overwrite TABLE dws.user_merge_info
-- 完全不变的数据
SELECT
id
,name
,sex
,start_date
,end_date
FROM dws.user_merge_info
WHERE (start_date<'$biz_date' AND end_date='') OR end_date<'$biz_date' UNION ALL -- 重跑 重新开链的数据
SELECT
id
,name
,sex
,start_date
,'' AS end_date
FROM dws.user_merge_info
WHERE start_date<'$biz_date' AND end_date>='$biz_date' AND end_date<>'';
"
if [ $? -ne 0 ];then
Log "\n## 【user_merge_info表回退】 执行失败 ##"
exit 1
fi
Log "\n## 【user_merge_info表回退】 执行成功 ##" fi
hive拉链表以及退链例子笔记的更多相关文章
- hive拉链表
前言 本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理.设计.以及在我们大数据场景下的实现方式. 全文由下面几个部分组成:先分享一下拉链表的用途.什么是拉链表.通过一些小的使用场景来对拉链表做 ...
- hive拉链表取数
例如,一个借款用户在hive上的拉链表.(end_dt存放逻辑与普通介绍的拉链表不一致) 需要拉去它在2019-05-01日的状态, 取数逻辑是: select * from tb where sta ...
- 漫谈数据仓库之拉链表(原理、设计以及在Hive中的实现)
本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理.设计.以及在我们大数据场景下的实现方式. 全文由下面几个部分组成: 先分享一下拉链表的用途.什么是拉链表. 通过一些小的使用场景来对拉链表做近 ...
- hive 汇率拉链表转日连续流水表
1.什么是拉链表 拉链表是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史.记录一个事物从开始,一直到当前状态的所有变化的信息. 我们先看一个示例,这就是一张拉链表,存储的 ...
- hive中拉链表
在有些情况下,为了保持历史的一些状态,需要用拉链表来做,这样做目的在可以保留所有状态的情况下可以节省空间. 拉链表适用于以下几种情况吧 数据量有点大,表中某些字段有变化,但是呢变化的频率也不是很高,业 ...
- 数仓1.4 |业务数仓搭建| 拉链表| Presto
电商业务及数据结构 SKU库存量,剩余多少SPU商品聚集的最小单位,,,这类商品的抽象,提取公共的内容 订单表:周期性状态变化(order_info) id 订单编号 total_amount 订单金 ...
- DataBase 之 拉链表结构设计
一.概念 拉链表是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史.记录一个事物从开始,一直到当前状态的所有变化的信息. 在历史表中对客户的一生的记录可能就这样几条记录,避 ...
- mysql执行拉链表操作
拉链表需求: 1.数据量比较大 2.变化的比例和频率比较小,例如客户的住址信息,联系方式等,比如有1千万的用户数据,每天全量存储会存储很多不变的信息,对存储也是浪费,因此可以使用拉链表的算法来节省存储 ...
- xmake v2.5.2 发布, 支持自动拉取交叉工具链和依赖包集成
xmake 是一个基于 Lua 的轻量级跨平台构建工具,使用 xmake.lua 维护项目构建,相比 makefile/CMakeLists.txt,配置语法更加简洁直观,对新手非常友好,短时间内就能 ...
随机推荐
- 基于谷歌开源的TensorFlow Object Detection API视频物体识别系统搭建自己的应用(四)
本章主要内容是利用mqtt.多线程.队列实现模型一次加载,批量图片识别分类功能 目录结构如下: mqtt连接及多线程队列管理 MqttManager.py # -*- coding:utf8 -*- ...
- java 回调的原理与实现
回调函数,顾名思义,用于回调的函数.回调函数只是一个功能片段,由用户按照回调函数调用约定来实现的一个函数.回调函数是一个工作流的一部分,由工作流来决定函数的调用(回调)时机. 回调原本应该是一个非常简 ...
- ASE Beta Sprint - backend scrum 1
本次scrum于2019.12.2与前端组和模型组一起在sky garden进行,持续50分钟. 参与人: Xin Kang, Zhikai Chen, Lihao Ran, Hao Wang 请假: ...
- Spring Cloud Stream监听已存在的Queues/Exchanges
环境准备 rabbitmq已运行,端口5672,控制台web端口15672,用户名密码guest/guest 引入spring cloud stream依赖 compile('org.springfr ...
- hdu 4655 Cut Pieces(想法题)
Cut Pieces Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131072/65536 K (Java/Others) Tota ...
- c# 反射获取属性值 TypeUtils
using System; using System.Collections.Generic; using System.Linq; using System.Reflection; using Sy ...
- maven 配置阿里云镜像
编辑%maven_home%/conf/settings.xml文件,添加 <mirror> <id>aliyun-maven</id> <mirrorOf& ...
- vue大文件分片上传插件
最近遇见一个需要上传百兆大文件的需求,调研了七牛和腾讯云的切片分段上传功能,因此在此整理前端大文件上传相关功能的实现. 在某些业务中,大文件上传是一个比较重要的交互场景,如上传入库比较大的Excel表 ...
- [POJ1772] Substract
问题描述 We are given a sequence of N positive integers a = [a1, a2, ..., aN] on which we can perform co ...
- 调用搜狐IP地址库,根据不同访问者的IP,显示访问地址
<script src="http://pv.sohu.com/cityjson?ie=utf-8"></script> <script type ...