手写-- K-means++
1. K-means++原理
K均值聚类属于启发式方法,不能保证收敛到全局最优,初始中心的选择会直接影响聚类结果。K-means是随机选择样本点作为聚类中心,容易造成算法局部收敛或者需要较多迭代次数,而K-means++将初始点的选择转化为概率问题,容易得到更好的初始聚类中心,加速算法收敛。下图是算法的步骤,转载自Yixuan-Xu的博客,有兴趣了解K-means算法的小伙伴可以进传送门看一看。


2.算法实现
- 利用sklearn的数据库生成数据集
# make datasets
X,y=datasets.make_blobs(n_samples=500,n_features=2,centers=3,cluster_std=1.2,center_box=(-5,10))
- 初始化K个聚类中心点
def center_select(X,y,k):
'''
初始化聚类中心点 Parameters
------------------
:param X: 数据集
:param y: 显示原始数据集不同团簇之间的颜色
:param k: 将数据集分成K类 Return
------------------
return X[centers_index,:]: 初始化的中心点坐标
'''
if k<2 or k>len(X):
print('k should be more than 1 and less than len(X)')
return k centers_index=[]
for i in range(k):
if i==0:
first_index=int(np.random.random()*len(X))
centers_index.append(first_index)
else:
res=np.zeros(len(X))
for j in centers_index:
sub=np.square(X-X[j,:])
distance=np.sum(sub,axis=1)
res+=distance
proba=np.cumsum(res/np.sum(res)) # Roulette selection
val=np.random.random()
for m,k in enumerate(proba):
if val<k:
centers_index.append(m)
break return X[centers_index,:]
- 聚类迭代
def k_mean(X,y,k,iter=1000):
'''
K-means++迭代更新 Parameters
------------------
:param X: 数据集
:param y: 显示原始数据集不同团簇之间的颜色
:param k: 将数据集分成K类
:param iter: 迭代次数 Return
------------------
return center: 迭代后的聚类中心点坐标
'''
center=center_select(X,y,k)
X_label=np.insert(X,X.shape[1],-1,axis=1) # show begin
plt.scatter(X[:,0],X[:,1],c=y)
plt.scatter(center[:,0],center[:,1],marker='+',c='red',s=500)
# iteration
for i in range(iter):
dis_res=np.zeros((len(X),k))
for j in range(k):
sub=np.square(X-center[j,:])
distance=np.sum(sub,axis=1)
dis_res[:,j]=distance
label=np.argmin(dis_res,axis=1)
X_label[:,-1]=label # update center
for m in range(k):
cache=X[X_label[:,-1]==m]
center[m,:]=np.sum(cache,axis=0)/len(cache) # show result
plt.figure()
plt.scatter(X[:,0],X[:,1],c=y)
plt.scatter(center[:,0],center[:,1],marker='+',c='red',s=500)
return center
- 调用迭代函数
# cluster
center=k_mean(X,y,3,iter=1000)
- 输出初始聚类中心与迭代结束后聚类中心图像
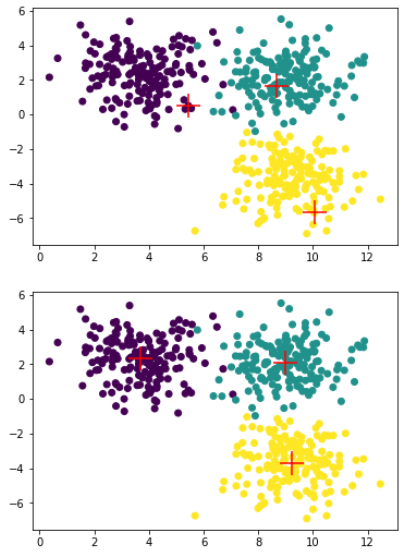
手写-- K-means++的更多相关文章
- OpenCV手写数字字符识别(基于k近邻算法)
摘要 本程序主要参照论文,<基于OpenCV的脱机手写字符识别技术>实现了,对于手写阿拉伯数字的识别工作.识别工作分为三大步骤:预处理,特征提取,分类识别.预处理过程主要找到图像的ROI部 ...
- k最邻近算法——使用kNN进行手写识别
上篇文章中提到了使用pillow对手写文字进行预处理,本文介绍如何使用kNN算法对文字进行识别. 基本概念 k最邻近算法(k-Nearest Neighbor, KNN),是机器学习分类算法中最简单的 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- KNN (K近邻算法) - 识别手写数字
KNN项目实战——手写数字识别 1. 介绍 k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法.它的工作原理是:存在一个 ...
- K近邻实战手写数字识别
1.导包 import numpy as np import operator from os import listdir from sklearn.neighbors import KNeighb ...
- 使用神经网络来识别手写数字【译】(三)- 用Python代码实现
实现我们分类数字的网络 好,让我们使用随机梯度下降和 MNIST训练数据来写一个程序来学习怎样识别手写数字. 我们用Python (2.7) 来实现.只有 74 行代码!我们需要的第一个东西是 MNI ...
- 手写朴素贝叶斯(naive_bayes)分类算法
朴素贝叶斯假设各属性间相互独立,直接从已有样本中计算各种概率,以贝叶斯方程推导出预测样本的分类. 为了处理预测时样本的(类别,属性值)对未在训练样本出现,从而导致概率为0的情况,使用拉普拉斯修正(假设 ...
- C#中调用Matlab人工神经网络算法实现手写数字识别
手写数字识别实现 设计技术参数:通过由数字构成的图像,自动实现几个不同数字的识别,设计识别方法,有较高的识别率 关键字:二值化 投影 矩阵 目标定位 Matlab 手写数字图像识别简介: 手写 ...
- Python 手写数字识别-knn算法应用
在上一篇博文中,我们对KNN算法思想及流程有了初步的了解,KNN是采用测量不同特征值之间的距离方法进行分类,也就是说对于每个样本数据,需要和训练集中的所有数据进行欧氏距离计算.这里简述KNN算法的特点 ...
- HDU 5183 Negative and Positive (NP) ——(后缀和+手写hash表)
根据奇偶开两个hash表来记录后缀和.注意set会被卡,要手写hash表. 具体见代码: #include <stdio.h> #include <algorithm> #in ...
随机推荐
- 初始 Kafka Consumer 消费者
温馨提示:整个 Kafka 专栏基于 kafka-2.2.1 版本. 1.KafkaConsumer 概述 根据 KafkaConsumer 类上的注释上来看 KafkaConsumer 具有如下特征 ...
- C# 调用R语言
在.net项目中需要调用Matlab生成的DLL,但是在调用过程中报错,截图如下: 在网上搜索一下资料,看到该博客:https://cn.mathworks.com/matlabcentral/new ...
- Django2.2 中间件的使用
中间件:AOP中间件,在Django中内置了一些项目自带的中间件,那么中间件是什么呢 这里说明一下,一开始我也不太清楚中间件到底有什么用(大家也别急,下面会有详细的例子给大家解释)--------&g ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- bzoj_1036 树链剖分套线段树
bzoj_1036 ★★★★ 输入文件:bzoj_1036.in 输出文件:bzoj_1036.out 简单对比时间限制:1 s 内存限制:162 MB [题目描述] 一棵树上有n个节 ...
- 【C_Language】---C语言const用法总结
C语言关键字const相信对于不少C语言新手是既陌生又熟悉的,好像经常见,但是却不知道为何用,怎么用?学习至此,总结一下const的用法,使用程序来帮助你理解该关键字,希望能帮到像我一样的新手. 我看 ...
- 关于程序员须知的 linux 基础
我在 github 上新建了一个仓库 日问,每天一道面试题,有关前端,后端,devops以及软技能,促进职业成长,敲开大厂之门,欢迎交流 并且记录我的面试经验 17年面试记(阿里百度美团头条小米滴滴) ...
- nginx服务无法停止(Windows)
本人一般停止nginx服务都是通过Windows自带的任务管理器来强制结束nginx进程实现的,如图 2.但是 这次我通过同样的方法来结束nginx服务,发现nginx的进程无法结束 3.首先我要 ...
- Java框架之SpringMVC 03-RequestMapping-请求数据-响应数据
SpringMVC SpringMVC是一种轻量级的.基于MVC的Web层应用框架. 通过一套 MVC 注解,让 POJO 成为处理请求的控制器,而无须实现任何接口. 采用了松散耦合可插拔组件结构,比 ...
- 关于爬虫的日常复习(17)——scrapy系列2