python 爬虫实例(四)
环境:
OS:Window10
python:3.7
爬取链家地产上面的数据,两个画面上的数据的爬取
效果,下面的两个网页中的数据取出来
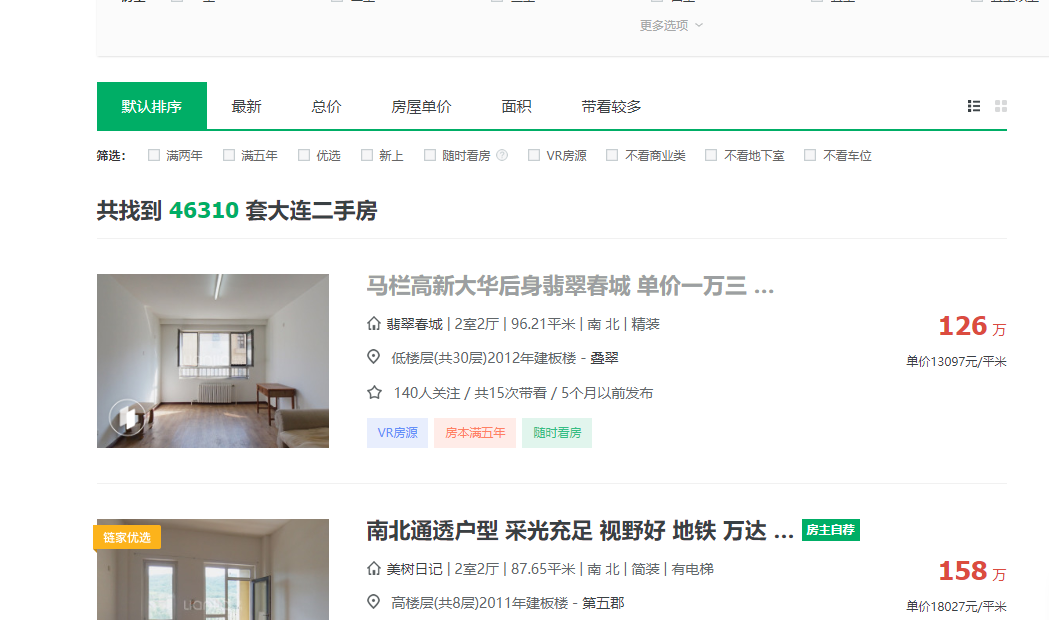
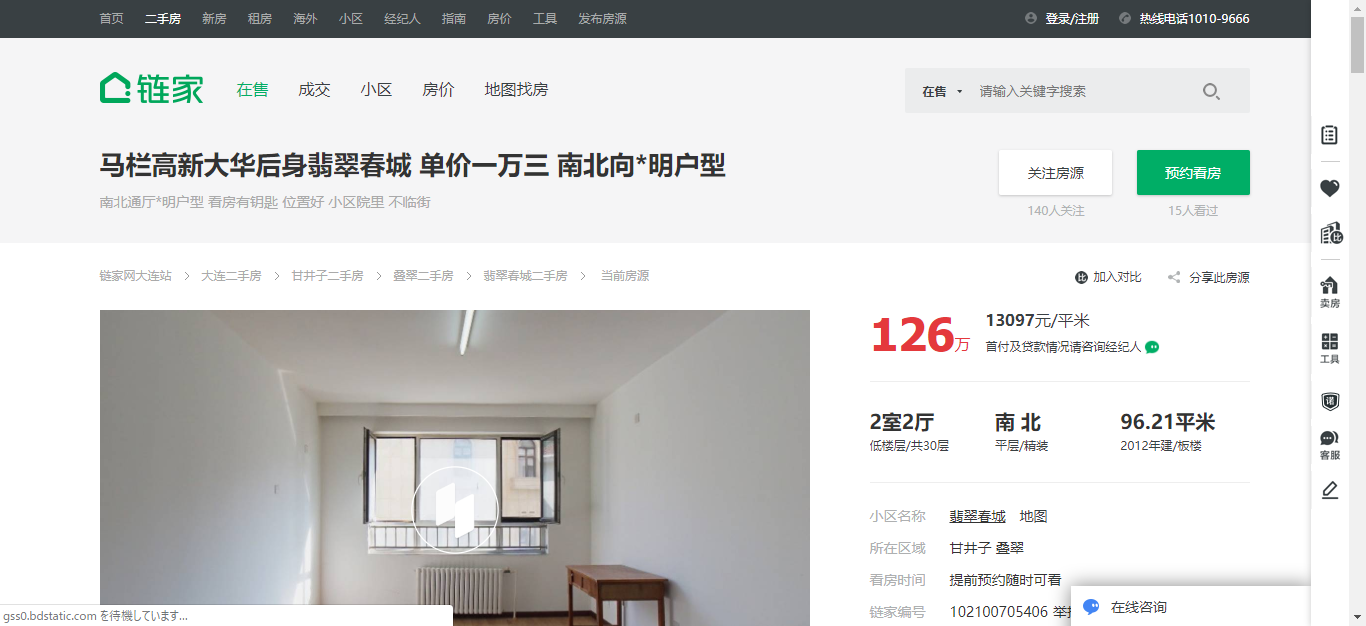
代码
import datetime
import threading import requests
from bs4 import BeautifulSoup class LianjiaHouseInfo: '''
初期化变量的值
'''
def __init__(self):
# 定义自己要爬取的URL
self.url = "https://dl.lianjia.com/ershoufang/pg{0}"
self.path = r"C:\pythonProject\Lianjia_House"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"} '''
访问URL
'''
def request(self, param): # 如果不加的话可能会出现403的错误,所以尽量的都加上header,模仿网页来访问
req = requests.get(param, headers=self.headers)
# req.raise_for_status()
# req.encoding = req.apparent_encoding
return req.text
'''
page設定
'''
def all_pages(self, pageCn):
dataListA = []
for i in range(1, pageCn+1):
if pageCn == 1:
dataListA = dataListA + self.getData(self.url[0:self.url.find("pg")])
else:
url = self.url.format(i)
dataListA = dataListA + self.getData(url)
# self.dataOrganize(dataListA)
'''
数据取得
'''
def getData(self, url):
dataList = []
thread_lock.acquire()
req = self.request(url)
# driver = webdriver.Chrome()
# driver.get(self.url)
# iframe_html = driver.page_source
# driver.close()
# print(iframe_html)
soup = BeautifulSoup(req, 'lxml')
countHouse = soup.find(class_="total fl").find("span")
print("共找到 ", countHouse.string, " 套大连二手房") sell_all = soup.find(class_="sellListContent").find_all("li")
for sell in sell_all: title = sell.find(class_="title")
if title is not None:
print("------------------------概要--------------------------------------------")
title = title.find("a")
print("title:", title.string)
housInfo = sell.find(class_="houseInfo").get_text()
print("houseInfo:", housInfo)
positionInfo = sell.find(class_="positionInfo").get_text()
print("positionInfo:", positionInfo) followInfo = sell.find(class_="followInfo").get_text()
print("followInfo:", followInfo) print("------------------------詳細信息--------------------------------------------")
url_detail = title["href"]
req_detail = self.request(url_detail)
soup_detail = BeautifulSoup(req_detail, "lxml")
total = soup_detail.find(class_="total")
unit = soup_detail.find(class_="unit").get_text()
dataList.append(total.string+unit)
print("总价:", total.string, unit)
unitPriceValue = soup_detail.find(class_="unitPriceValue").get_text()
dataList.append(unitPriceValue)
print("单价:", unitPriceValue)
room_mainInfo = soup_detail.find(class_="room").find(class_="mainInfo").get_text()
dataList.append(room_mainInfo)
print("户型:", room_mainInfo)
type_mainInfo = soup_detail.find(class_="type").find(class_="mainInfo").get_text()
dataList.append(type_mainInfo)
print("朝向:", type_mainInfo)
area_mainInfo = soup_detail.find(class_="area").find(class_="mainInfo").get_text()
dataList.append(area_mainInfo)
print("面积:", area_mainInfo) else:
print("広告です")
thread_lock.release()
return dataList
#
# def dataOrganize(self, dataList):
#
# data2 = pd.DataFrame(dataList)
# data2.to_csv(r'C:\Users\peiqiang\Desktop\lagoujob.csv', header=False, index=False, mode='a+')
# data3 = pd.read_csv(r'C:\Users\peiqiang\Desktop\lagoujob.csv', encoding='gbk') thread_lock = threading.BoundedSemaphore(value=100)
house_Info = LianjiaHouseInfo()
startTime = datetime.datetime.now()
house_Info.all_pages(1)
endTime = datetime.datetime.now()
print("実行時間:", (endTime - startTime).seconds)
运行之后的效果

python 爬虫实例(四)的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
- Python爬虫进阶四之PySpider的用法
审时度势 PySpider 是一个我个人认为非常方便并且功能强大的爬虫框架,支持多线程爬取.JS动态解析,提供了可操作界面.出错重试.定时爬取等等的功能,使用非常人性化. 本篇内容通过跟我做一个好玩的 ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- Python 爬虫实例
下面是我写的一个简单爬虫实例 1.定义函数读取html网页的源代码 2.从源代码通过正则表达式挑选出自己需要获取的内容 3.序列中的htm依次写到d盘 #!/usr/bin/python import ...
- shell及Python爬虫实例展示
1.shell爬虫实例: [root@db01 ~]# vim pa.sh #!/bin/bash www_link=http://www.cnblogs.com/clsn/default.html? ...
- python爬虫实例——爬取歌单
学习自<<从零开始学python网络爬虫>> 爬取酷狗歌单,保存入csv文件 直接上源代码:(含注释) import requests #用于请求网页获取网页数据 from b ...
随机推荐
- C利用time函数实现简单的定时器
//定时器 #include <stdio.h> #include <time.h> #include <stdlib.h> int main(int num, c ...
- shell编程练习题
求2个数之和 计算1-100的和 将一目录下所有的文件的扩展名改为bak 编译当前目录下的所有.c文件: 打印root可以使用可执行文件数,处理结果: root's bins: 2306 打印当前ss ...
- node.js Error: connect EMFILE 或者 getaddrinfo ENOTFOUND
Error: getaddrinfo ENOTFOUND] code: 'ENOTFOUND', errno: 'ENOTFOUND', syscall: 'getaddrinfo' Error: c ...
- GO语言测试
Go语言的测试技术是相对低级的.它依赖一个 go test 测试命令和一组按照约定方式编写的 测试函数,测试命令可以运行这些测试函数.编写相对轻量级的纯测试代码是有效的,而且它很容易延伸到基准测试和示 ...
- windows命令行操作
一.打开方式 - 开始菜单 --> 运行 --> 输入cmd --> 回车 二.常用的指令 dir - 列出当前目录 ...
- エンジニア死滅シタ世界之高層ビル [MISSION LEVEL: B]-Python3
n = input() pre="" next_str = "" new_str = "" for i in range(int(n)): ...
- uSurvival 1.41多人在线生存逃杀吃鸡类游戏源码
uSurvival - the new Multiplayer Survival Asset from the creator of uMMORPG. Features:* Kill Zombies ...
- Kafka的Topic、Partition和Message
Kafka的Topic和Partition Topic Topic是Kafka数据写入操作的基本单元,可以指定副本 一个Topic包含一个或多个Partition,建Topic的时候可以手动指定Par ...
- 浏览器cookie数 跨站请求伪造 欧盟Cookie指令
<?php for ($w=0; $w < 200 ; $w++) { setcookie('name'.$w,'value'.$w, time()+3600*10 ); } var_du ...
- Tensorflow 2 模型默认保存路径
Tensorflow 2 模型默认保存路径 商务合作,科技咨询,版权转让:向日葵,135-4855__4328,xiexiaokui#qq.com 保存: import datetime now=da ...