python 爬虫实例(四)
环境:
OS:Window10
python:3.7
爬取链家地产上面的数据,两个画面上的数据的爬取
效果,下面的两个网页中的数据取出来
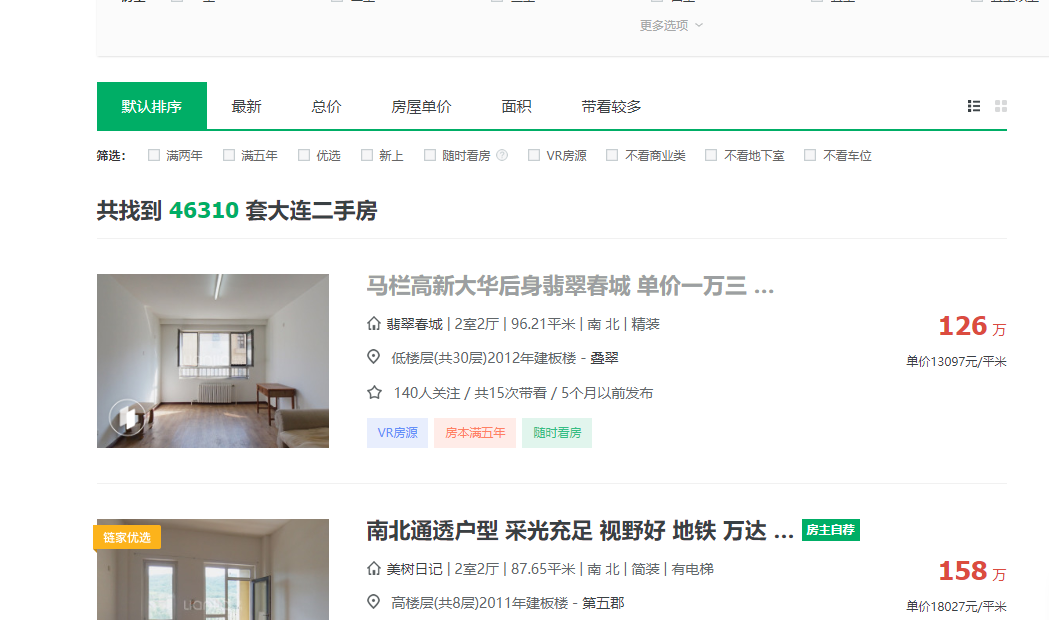
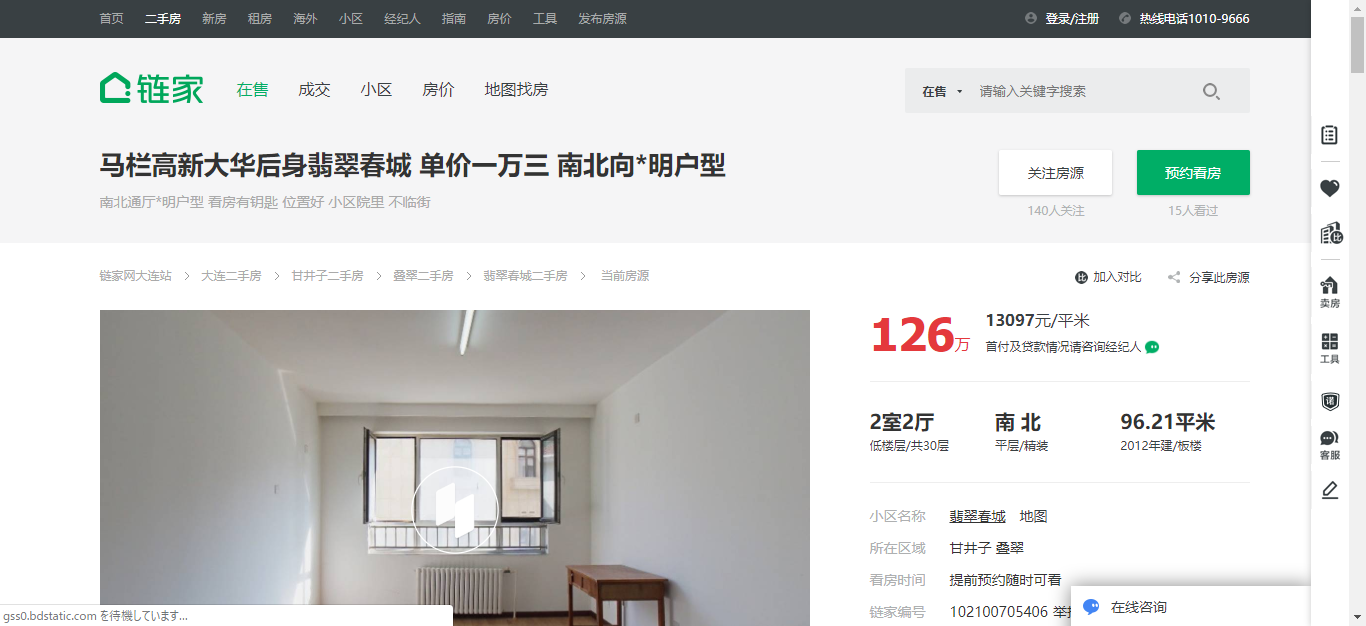
代码
import datetime
import threading import requests
from bs4 import BeautifulSoup class LianjiaHouseInfo: '''
初期化变量的值
'''
def __init__(self):
# 定义自己要爬取的URL
self.url = "https://dl.lianjia.com/ershoufang/pg{0}"
self.path = r"C:\pythonProject\Lianjia_House"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"} '''
访问URL
'''
def request(self, param): # 如果不加的话可能会出现403的错误,所以尽量的都加上header,模仿网页来访问
req = requests.get(param, headers=self.headers)
# req.raise_for_status()
# req.encoding = req.apparent_encoding
return req.text
'''
page設定
'''
def all_pages(self, pageCn):
dataListA = []
for i in range(1, pageCn+1):
if pageCn == 1:
dataListA = dataListA + self.getData(self.url[0:self.url.find("pg")])
else:
url = self.url.format(i)
dataListA = dataListA + self.getData(url)
# self.dataOrganize(dataListA)
'''
数据取得
'''
def getData(self, url):
dataList = []
thread_lock.acquire()
req = self.request(url)
# driver = webdriver.Chrome()
# driver.get(self.url)
# iframe_html = driver.page_source
# driver.close()
# print(iframe_html)
soup = BeautifulSoup(req, 'lxml')
countHouse = soup.find(class_="total fl").find("span")
print("共找到 ", countHouse.string, " 套大连二手房") sell_all = soup.find(class_="sellListContent").find_all("li")
for sell in sell_all: title = sell.find(class_="title")
if title is not None:
print("------------------------概要--------------------------------------------")
title = title.find("a")
print("title:", title.string)
housInfo = sell.find(class_="houseInfo").get_text()
print("houseInfo:", housInfo)
positionInfo = sell.find(class_="positionInfo").get_text()
print("positionInfo:", positionInfo) followInfo = sell.find(class_="followInfo").get_text()
print("followInfo:", followInfo) print("------------------------詳細信息--------------------------------------------")
url_detail = title["href"]
req_detail = self.request(url_detail)
soup_detail = BeautifulSoup(req_detail, "lxml")
total = soup_detail.find(class_="total")
unit = soup_detail.find(class_="unit").get_text()
dataList.append(total.string+unit)
print("总价:", total.string, unit)
unitPriceValue = soup_detail.find(class_="unitPriceValue").get_text()
dataList.append(unitPriceValue)
print("单价:", unitPriceValue)
room_mainInfo = soup_detail.find(class_="room").find(class_="mainInfo").get_text()
dataList.append(room_mainInfo)
print("户型:", room_mainInfo)
type_mainInfo = soup_detail.find(class_="type").find(class_="mainInfo").get_text()
dataList.append(type_mainInfo)
print("朝向:", type_mainInfo)
area_mainInfo = soup_detail.find(class_="area").find(class_="mainInfo").get_text()
dataList.append(area_mainInfo)
print("面积:", area_mainInfo) else:
print("広告です")
thread_lock.release()
return dataList
#
# def dataOrganize(self, dataList):
#
# data2 = pd.DataFrame(dataList)
# data2.to_csv(r'C:\Users\peiqiang\Desktop\lagoujob.csv', header=False, index=False, mode='a+')
# data3 = pd.read_csv(r'C:\Users\peiqiang\Desktop\lagoujob.csv', encoding='gbk') thread_lock = threading.BoundedSemaphore(value=100)
house_Info = LianjiaHouseInfo()
startTime = datetime.datetime.now()
house_Info.all_pages(1)
endTime = datetime.datetime.now()
print("実行時間:", (endTime - startTime).seconds)
运行之后的效果

python 爬虫实例(四)的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
- Python爬虫进阶四之PySpider的用法
审时度势 PySpider 是一个我个人认为非常方便并且功能强大的爬虫框架,支持多线程爬取.JS动态解析,提供了可操作界面.出错重试.定时爬取等等的功能,使用非常人性化. 本篇内容通过跟我做一个好玩的 ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- Python 爬虫实例
下面是我写的一个简单爬虫实例 1.定义函数读取html网页的源代码 2.从源代码通过正则表达式挑选出自己需要获取的内容 3.序列中的htm依次写到d盘 #!/usr/bin/python import ...
- shell及Python爬虫实例展示
1.shell爬虫实例: [root@db01 ~]# vim pa.sh #!/bin/bash www_link=http://www.cnblogs.com/clsn/default.html? ...
- python爬虫实例——爬取歌单
学习自<<从零开始学python网络爬虫>> 爬取酷狗歌单,保存入csv文件 直接上源代码:(含注释) import requests #用于请求网页获取网页数据 from b ...
随机推荐
- C程序的函数说明使用和特点说明第一节
一.函数的特点: 全部都是全部函数构成 面向过程的:是函数式语言 函数的调用 是按需调用 封装包含 二.程序中函数的作用: 可以使用函数使程序变的简短 和 清晰 提高代码重用性 提高开发效率 有利于程 ...
- TPS与QPS,以及GMV
TPS是指每秒处理事务的个数,处理的载体可以是单台服务器,也可以是一个服务器集群. 例如:下单接口,一秒内,下单完成次数为1000,则下单接口总 tps = 1000,共有10台服务器提供下单服务,单 ...
- AtCoder Grand Contest 018题解
传送门 \(A\) 根据裴蜀定理显然要\(k|\gcd(a_1,...,a_n)\),顺便注意不能造出大于\(\max(a_1,...,a_n)\)的数 int n,g,k,x,mx; int mai ...
- GoCN每日新闻(2019-09-28)
GoCN每日新闻(2019-09-28) 1. 可视化Go程序的调用图 https://truefurby.github.io/go-callvis/2. Go modules编写和发布官方教程 h ...
- __enter__,__exit__区别
__enter__():在使用with语句时调用,会话管理器在代码块开始前调用,返回值与as后的参数绑定 __exit__():会话管理器在代码块执行完成好后调用,在with语句完成时,对象销毁之前调 ...
- TCP采用四次挥手关闭连接如图所示为什么建立连接协议是三次握手,而关闭连接却是四次握手呢?
tcp四次挥手,由于TCP连接是全双工的,因此每个方向都必须单独进行关闭. 由于TCP连接是全双工的,因此每个方向都必须单独进行关闭.这个原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个 ...
- Bat 复制本地文件到共享目录
@echo off title "copy UI" net use \\172.16.104.93\心电图 "password" /user:"adm ...
- rocketMq和kafka的架构区别
概述 其实一直想写一篇rocketMq和kafka在架构设计上的差别,但是一直有个问题没搞明白所以迟迟没动手,今天无意中听人点播了一下似乎明白了这个问题,所以就有了这篇对比. 这篇博文主要讲清楚kaf ...
- [FUZZ]文件上传fuzz字典生成脚本—使用方法
文件上传fuzz字典生成脚本-使用方法 原作者:c0ny1 项目地址:https://github.com/c0ny1/upload-fuzz-dic-builder 项目预览效果图: 帮助手册: 脚 ...
- HTML Entity
1.1 介绍 在编写HTML页面时,需要用到"<".">"."空格"等符号,直接输入这些符号时,会错误的把它们与标记混在一起,非 ...