MindSpore 数据加载及处理
参考地址:
https://www.mindspore.cn/tutorial/zh-CN/r1.2/dataset.html
========================================================
数据集下载:
mkdir -p ./datasets/MNIST_Data/train ./datasets/MNIST_Data/test
wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-labels-idx1-ubyte
wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-images-idx3-ubyte
wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-labels-idx1-ubyte
wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-images-idx3-ubyte
tree ./datasets/MNIST_Data
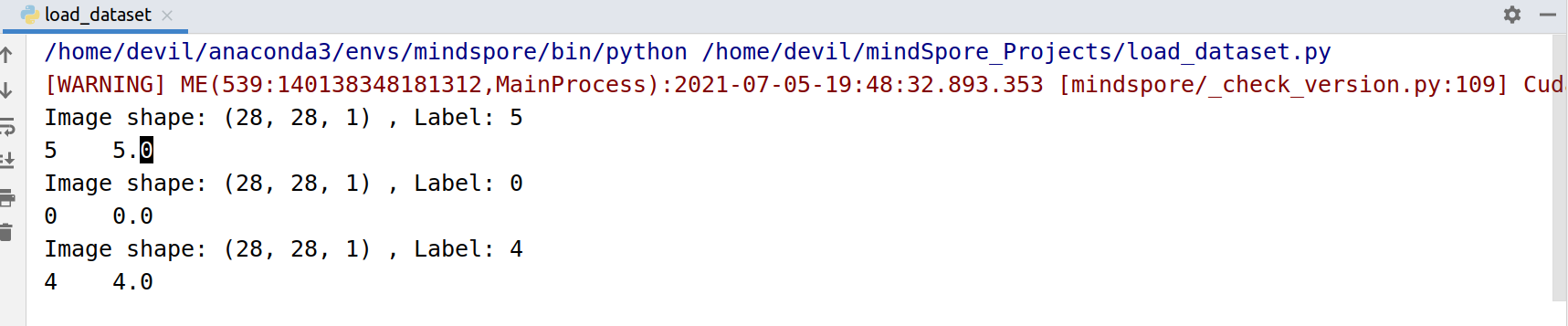
顺序读取N个样本:
import mindspore.dataset as ds
from mindspore import dtype as mstype DATA_DIR = "./datasets/MNIST_Data/train"
sampler = ds.SequentialSampler(num_samples=3)
dataset = ds.MnistDataset(DATA_DIR, sampler=sampler) for data in dataset.create_dict_iterator():
print("Image shape: {}".format(data['image'].shape), ", Label: {}".format(data['label']))
print(data['label'], "\t", data['label'].astype(mstype.float32))
自定义数据集
import mindspore.dataset as ds import numpy as np np.random.seed(58) class DatasetGenerator:
def __init__(self):
self.data = np.random.sample((5, 2))
self.label = np.random.sample((5, 1)) def __getitem__(self, index):
return self.data[index], self.label[index] def __len__(self):
return len(self.data) dataset_generator = DatasetGenerator()
dataset = ds.GeneratorDataset(dataset_generator, ["data", "label"], shuffle=False) for i, data in enumerate(dataset.create_dict_iterator()):
print("第 %d 个样本"%i)
print('{}'.format(data["data"]), '{}'.format(data["label"]))

对自定义数据集进行一定预处理:
import mindspore.dataset as ds import numpy as np np.random.seed(58) class DatasetGenerator:
def __init__(self):
self.data = np.random.sample((5, 2))
self.label = np.random.sample((5, 1)) def __getitem__(self, index):
return self.data[index], self.label[index] def __len__(self):
return len(self.data) dataset_generator = DatasetGenerator()
dataset = ds.GeneratorDataset(dataset_generator, ["data", "label"], shuffle=False) # 随机打乱数据顺序
dataset = dataset.shuffle(buffer_size=10)
# 对数据集进行分批
dataset = dataset.batch(batch_size=2) for i, data in enumerate(dataset.create_dict_iterator()):
print("第 %d 次选取样本"%i)
print("data: \n{}".format(data["data"]))
print("label: \n{}".format(data["label"]))

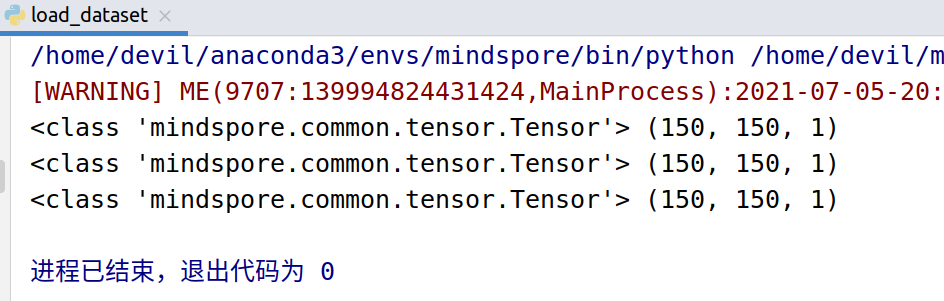
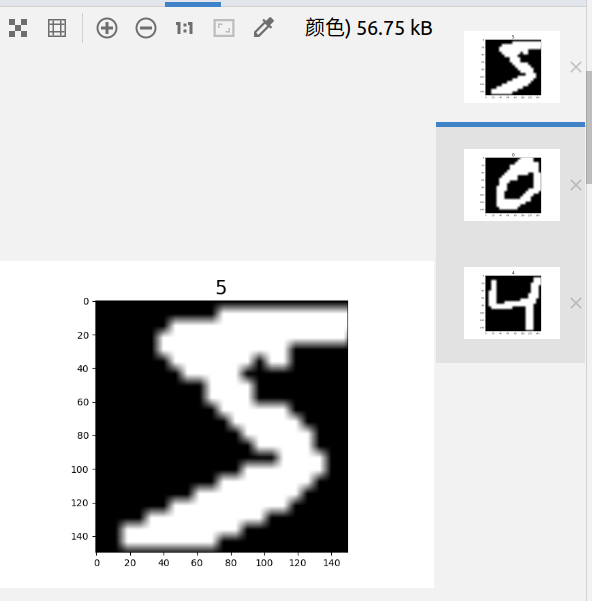
数据处理及增强
import matplotlib.pyplot as plt import mindspore.dataset as ds
from mindspore.dataset.vision import Inter
import mindspore.dataset.vision.c_transforms as c_vision DATA_DIR = './datasets/MNIST_Data/train'
_number_samples = 3 mnist_dataset = ds.MnistDataset(DATA_DIR, num_samples=_number_samples, shuffle=False) resize_op = c_vision.Resize(size=(200,200), interpolation=Inter.LINEAR)
crop_op = c_vision.RandomCrop(150) # 随机将图像裁剪成150尺寸
transforms_list = [resize_op, crop_op]
mnist_dataset = mnist_dataset.map(operations=transforms_list, input_columns=["image"]) # 查看数据原图
mnist_it = mnist_dataset.create_dict_iterator() for _ in range(_number_samples):
data = next(mnist_it)
print(type(data['image']), data['image'].shape) plt.imshow(data['image'].asnumpy().squeeze(), cmap=plt.cm.gray)
plt.title(data['label'].asnumpy(), fontsize=20)
plt.show()
MindSpore 数据加载及处理的更多相关文章
- ScrollView嵌套ListView,GridView数据加载不全问题的解决
我们大家都知道ListView,GridView加载数据项,如果数据项过多时,就会显示滚动条.ScrollView组件里面只能包含一个组件,当ScrollView里面嵌套listView,GridVi ...
- python多种格式数据加载、处理与存储
多种格式数据加载.处理与存储 实际的场景中,我们会在不同的地方遇到各种不同的数据格式(比如大家熟悉的csv与txt,比如网页HTML格式,比如XML格式),我们来一起看看python如何和这些格式的数 ...
- flask+sqlite3+echarts3+ajax 异步数据加载
结构: /www | |-- /static |....|-- jquery-3.1.1.js |....|-- echarts.js(echarts3是单文件!!) | |-- /templates ...
- Entity Framework关联查询以及数据加载(延迟加载,预加载)
数据加载分为延迟加载和预加载 EF的关联实体加载有三种方式:Lazy Loading,Eager Loading,Explicit Loading,其中Lazy Loading和Explicit Lo ...
- JQuery插件:遮罩+数据加载中。。。(特点:遮你想遮,罩你想罩)
在很多项目中都会涉及到数据加载.数据加载有时可能会是2-3秒,为了给一个友好的提示,一般都会给一个[数据加载中...]的提示.今天就做了一个这样的提示框. 先去jQuery官网看看怎么写jQuery插 ...
- 如何评估ETL的数据加载时间
简述如何评估大型ETL数据加载时间. 答:评估一个大型的ETL的数据加载时间是一件很复杂的事情.数据加载分为两类,一类是初次加载,另一类是增量加载. 在数据仓库正式投入使用时,需要进行一次初次加载,而 ...
- 浅谈Entity Framework中的数据加载方式
如果你还没有接触过或者根本不了解什么是Entity Framework,那么请看这里http://www.entityframeworktutorial.net/EntityFramework-Arc ...
- 实现虚拟模式的动态数据加载Windows窗体DataGridView控件 .net 4.5 (一)
实现虚拟模式的即时数据加载Windows窗体DataGridView控件 .net 4.5 原文地址 :http://msdn.microsoft.com/en-us/library/ms171624 ...
- Android Volley和Gson实现网络数据加载
Android Volley和Gson实现网络数据加载 先看接口 1 升级接口 http://s.meibeike.com/mcloud/ota/cloudService POST请求 参数列表如下 ...
- Echarts通过Ajax实现动态数据加载
Echarts(3.x版)官网实例的数据都是静态的,实际使用中往往会要求从服务器端取数据进行动态显示,官网教程里给出的异步数据加载很粗略,下面就以官网最简单的实例为例子,详细演示如下过程:1.客户端通 ...
随机推荐
- WIN10 家庭版 罗技G hub 安装提示不兼容当前操作系统解决方法
WIN10 家庭版 罗技G hub 安装提示不兼容当前操作系统解决方法 解决方法: 下载Onboard Memory Manager就可以. --
- C# .NET 生成国密私钥公钥对
使用的工具类: using Org.BouncyCastle.Asn1; using Org.BouncyCastle.Asn1.GM; using Org.BouncyCastle.Asn1.X9; ...
- Jmeter进行HTTPS接口压测及SSL证书验证
一.前言 使用JMeter压测HTTPS接口比较简单,只需要预先处理SSL证书认证,后面就是压测HTTP接口的通用步骤. HTTPS连接证书来验证浏览器和WEB服务器之间的连接.通过HTTP连接时,服 ...
- 工程数学 实验5-MATLAB最优化工具箱的使用
(1)线性规划应用案例的求解 1.基本要求 通过一个农业生产计划优化安排的实例求解,培养学生解决实际线性规划问题的初步能力:熟悉线性规划的建模过程:掌握Matlab优化工具箱中线性规划函数的调用. 2 ...
- [AGC030C] Coloring Torus
非常巧妙的一道构造题,发现对于所构造的 \(n\) 有上限,那么对于 \(K<=500\) 的情况,很好构造,每行全是一个数就行了,对于 \(K>500\) 的情况,显然每行都是 \(1, ...
- 配置h5py、netCDF4库的方法:Anaconda环境
本文介绍基于Anaconda环境,下载并安装Python中h5py与netCDF4这两个模块的方法. 在Python语言中,h5py与netCDF4这两个模块是与遥感图像处理.地学分析等GIS ...
- Linux 内核:RCU机制与使用
Linux 内核:RCU机制与使用 背景 学习Linux源码的时候,发现很多熟悉的数据结构多了__rcu后缀,因此了解了一下这些内容. 介绍 RCU(Read-Copy Update)是数据同步的一种 ...
- 配置上新 | 单双四核任选,TI Cortex-A53工业核心板仅198元起!
创龙科技作为TI官方合作伙伴,在2022年9月即推出搭载TI AM62x最新明星处理器的工业核心板-SOM-TL62x. SOM-TL62x工业核心板基于TI Sitara系列AM62x单/双/四核A ...
- Java实现分页的方式有哪些?
1.手动分页 不使用任何框架,用limt分页 select xx from tab_a limt #{pageNo},#{pageSize} 2.RowBounds分页(不推荐) 这个是内存分页,它的 ...
- Oracle 锁表查询和解锁方法
system登录 查询被锁表信息 select sess.sid, sess.serial#, lo.oracle_username, lo.os_user_name, ao.object_name, ...